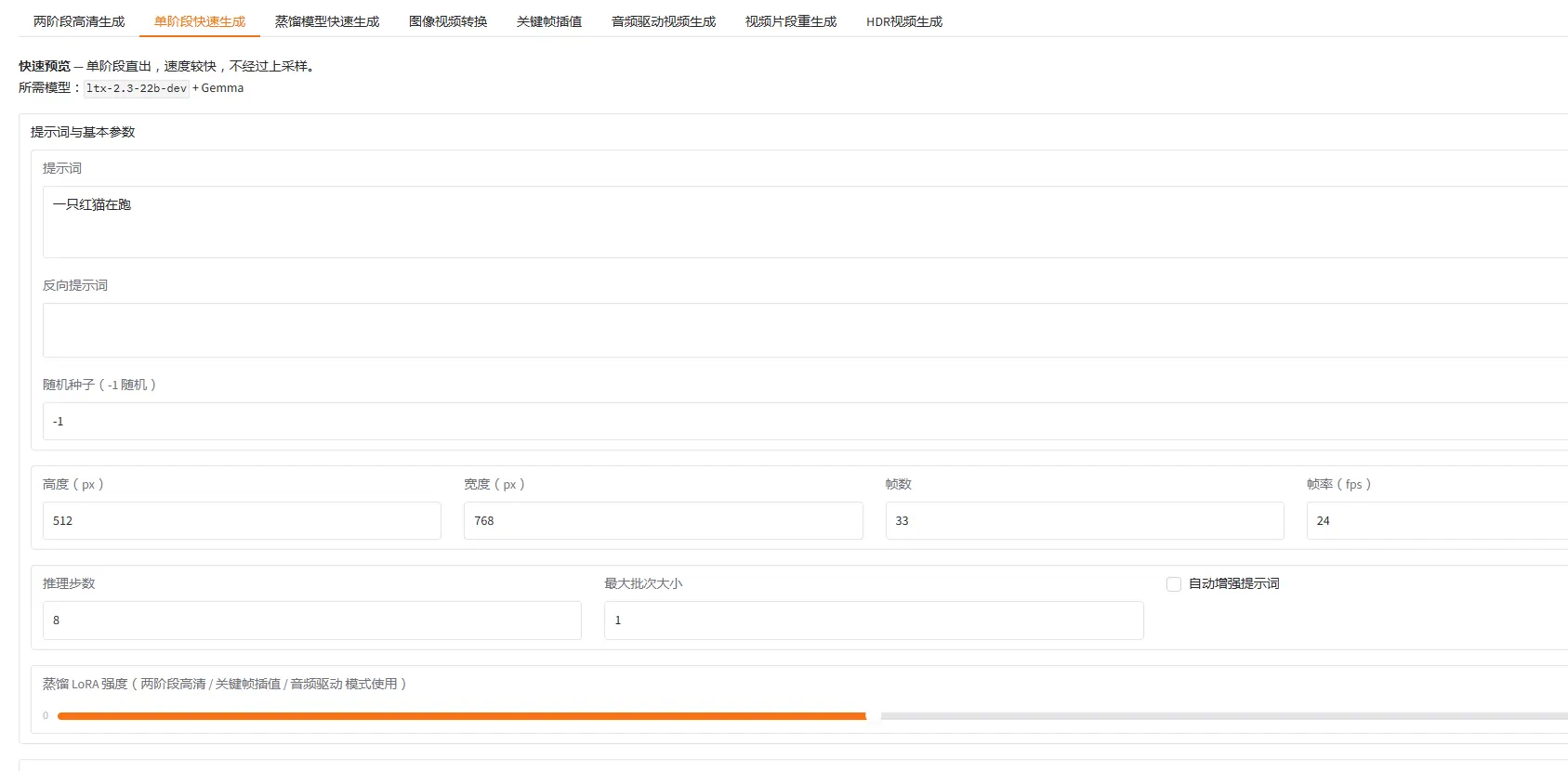
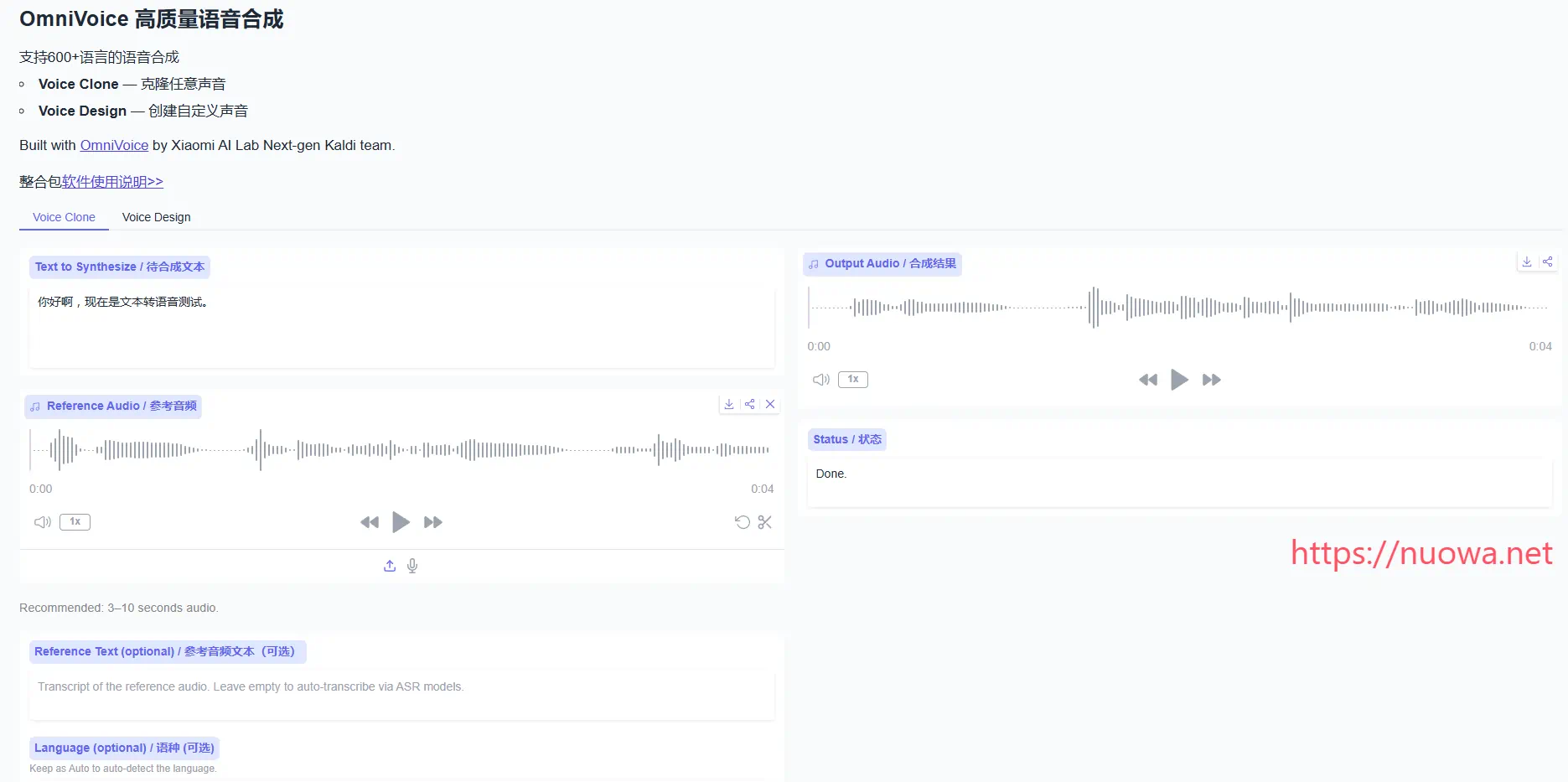
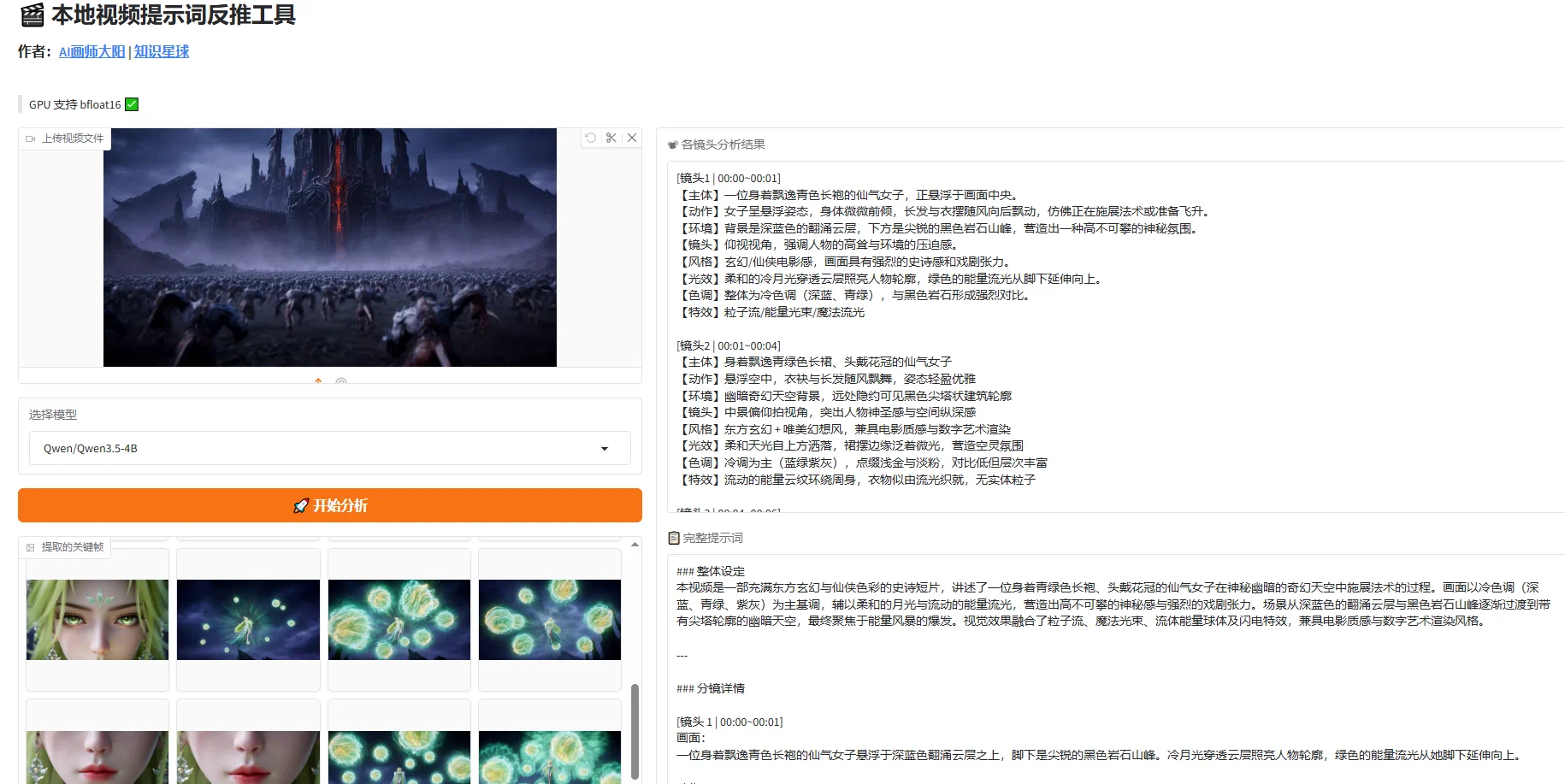
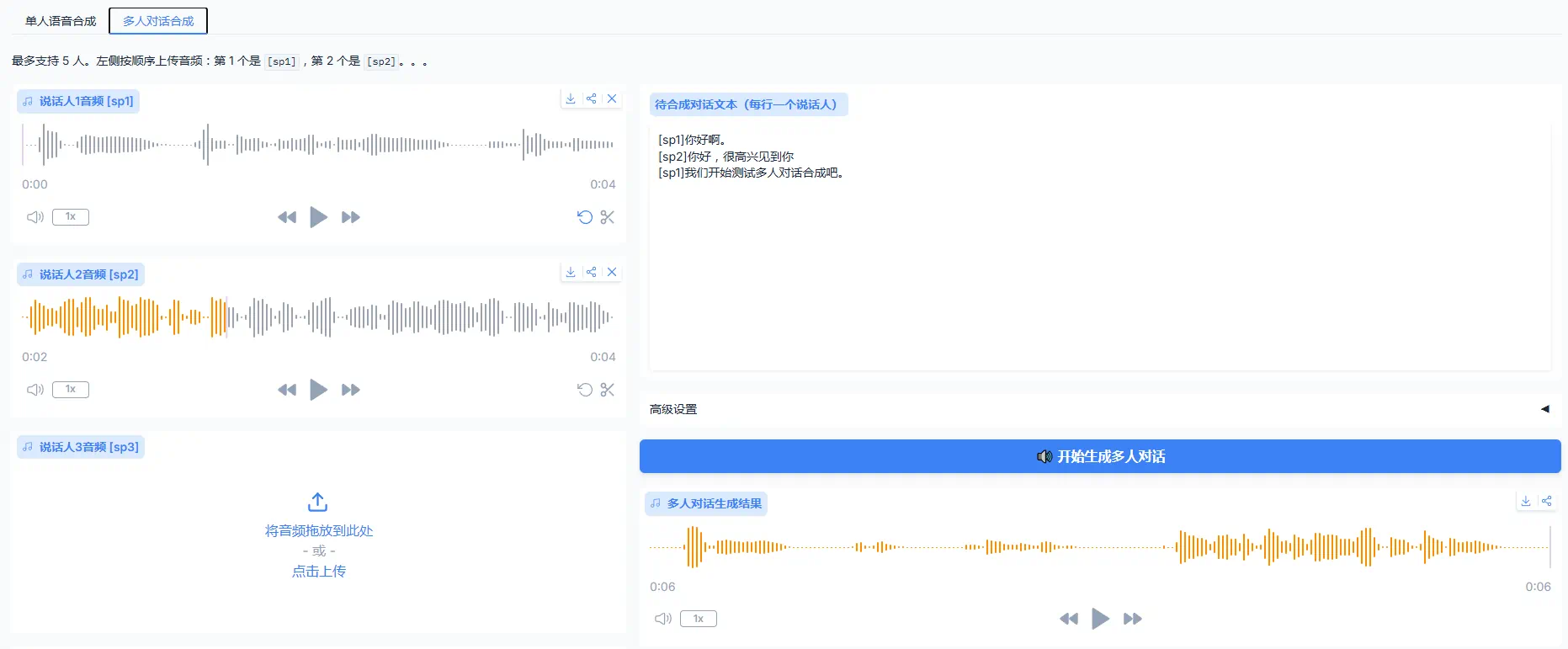
comfyui是目前非常热门的一个应用,它使python应用可以图形化以节点的方式直接拖拽使用,使用起来非常方便,而且可以与其他python应用节点配合使用,大大丰富了comfyui的功能,而且网上大量平台可以下载到各种的comfyui工作流,让你使用起来更加方便。
当前comfyui最新版本为0.21.1版本
v0.21.1版本更新内容
[合作伙伴节点] 新增 Flux2ImageNode 和 GrokImageEditNodeV2 节点
【合作伙伴节点】新增 ByteDanceSeedreamNodeV2 节点,支持 DynamicCombo 和 Autogrow 功能
[合作伙伴节点] 新的 OpenAI 图像节点,带有 DynamicCombo 和 Autogrow 功能
model_patcher:修复 fp8 (CORE-160) 的安全张量保存问题
支持 anima TE lora kohya 格式
功能:支持 HiDream-O1-Image (CORE-187)
修复 hidream o1 的 dtype 问题
[合作伙伴节点] 修复箭袋节点
@MillerMedia 在#13789中标记了规范中已弃用的云运行时端点
@MillerMedia 在#13842中提出了抑制 WebSocket 端点上 Spectral lint 误报的问题。
修复 LTXV 视频中多帧引导线对齐问题 (CORE-129)
撤销部分重大更改。
修复:如果 LoadAudio define_schema 中缺少输入目录,则创建输入目录
Hidream O1 非动态显存的内存利用率更高。
任务:将嵌入式文档更新至 v0.5.0
将“创建视频”添加到“基本功能”选项卡
功能:扩展 Save3D 以保存顶点颜色和纹理 (CORE-189)
[合作伙伴节点] 添加 Claude LLM 节点
任务:将工作流程模板更新至 v0.9.75
修复 VOID 调用失败并出现 RuntimeError 的问题
0.3.66版本更新内容
- Python 3.14 说明。由@comfyanonymous在#10337中提供
- 更快的工作流取消功能。由@comfyanonymous在#10301中实现
- api-nodes:修复了动态定价格式;将comfy_io重命名为IO,由@bigcat88在#10336中完成
- 将前端升级到1.28.6,由@arjansingh在#10345中操作
- gfx942不支持fp8运算。由@comfyanonymous在#10348中指出
- 添加TemporalScoreRescaling节点,由@chaObserv在#10351中实现
- 功能(api-nodes):添加Veo3.1模型,由@bigcat88在#10357中完成
- 最新的pytorch稳定版是cu130,由@comfyanonymous在#10361中说明
- 修复嵌套merge_nested_dicts的输入顺序,由@Kosinkadink在#10362中完成
- 重构:用merge_nested_dicts替代手动补丁合并,由@neverbiasu在#10360中实现
- 将前端升级到1.28.7,由@arjansingh在#10364中操作
- 功能:已弃用的API警报,由@LittleSound在#10366中实现
- 修复(api-nodes):从Veo3节点中移除“veo2”模型,由@bigcat88在#10372中完成
- 针对nvidia问题的解决方法,即在torch 2.9上VAE占用3倍多的内存,由@comfyanonymous在#10373中提供
- 该解决方法在cudnn 91200上也适用,由@comfyanonymous在#10375中说明
- 在EasyCache的apply_cache_diff中执行batch_slice,由@Kosinkadink在#10376中完成
- 执行:融入依赖感知缓存/修复带有循环/延迟等的–cache-none,由@rattus128在#10368中实现
- [V3] 将nodes_controlnet.py转换为V3模式,由@bigcat88在#10202中完成
- 更新Python 3.14安装说明,由@comfyanonymous在#10385中操作
- 为cast_bias_weight函数禁用torch编译器,由@comfyanonymous在#10384中完成
- 当开启–fast自动调优时,默认关闭cuda内存分配。由@comfyanonymous在#10393中实现
- 修复批量大小大于1时在chroma radiance中产生错误输出的问题。由@comfyanonymous在#10394中完成
- 提升chroma radiance的速度。由@comfyanonymous在#10395中实现
- Pytorch太糟糕了。由@comfyanonymous在#10398中表述
- 关于未使用文件的弃用警告,由@christian-byrne在#10387中添加
- 将模板更新到0.2.1,由@comfyui-wiki在#10413中操作
- 关于在AMD上禁用cudnn的日志消息。由@comfyanonymous在#10418中添加
- 还原“执行:融入依赖感知缓存/修复带有循环/
v0.3.52版本更新内容
LTXV:修复真实噪声掩码存在时的关键帧噪声掩码尺寸@harelc在#9425中
在 readme 中添加了对 qwen 编辑模型的支持。@comfyanonymous在#9463中
支持 Qwen Diffsynth Controlnets 精明和深度。@comfyanonymous在#9465中
修复:在工作流保存期间处理无效的文件名(#9434)@saurabh-pingale在#9445中
忘记了这一点。@comfyanonymous在#9470中
支持 diffsynth inpaint controlnet/model patch。通过@comfyanonymous在#9471中
将字符串节点转换为 V3 模式@bigcat88在#9370中
v3 节点(a 部分)@bigcat88在#9149中
[V3] 将 Google Veo API 节点转换为 V3 模式@bigcat88在#9272中
[V3] 将 Ideogram API 节点转换为 V3 模式@bigcat88在#9278中
使未来的 qwen 控制网的实现更加容易。@comfyanonymous在#9485中
支持 InstantX Qwen 控制网。@comfyanonymous在#9488中
feat(api-nodes):将“OpenAI Chat”显示名称更改为“OpenAI ChatGPT”@bigcat88在#9443中
feat(api-nodes):通过以下方式向 Gemini Chat 节点添加复制按钮@bigcat88在#9440中
将模板更新至 0.1.65@comfyui-wiki在#9501中
通过以下方式添加元素融合@contentis在#9495中
实现 EasyCache 并发明 LazyCache@Kosinkadink在#9496中
修复 3d 潜伏期的调节蒙版。通过@comfyanonymous在#9506中
Python 3.13 得到了很好的支持。@comfyanonymous在#9511中
不要默认使用烦人的新导航模式。@comfyanonymous在#9518中
将前端更新至 v1.25.10 并恢复导航模式覆盖@christian-byrne在#9522中
v0.3.51版本更新内容
放回前端版本。由@comfyanonymous在#9317中
再次减小便携尺寸。通过@comfyanonymous在#9323中
SDPA 后端优先级@contentis在#9299中
使最后的 PR 在旧版 PyTorch 上不会崩溃。@comfyanonymous在#9324中
修复 XPU iGPU 回归问题@simonlui在#9322中
通过以下方式为核心采样代码添加了上下文窗口支持@Kosinkadink在#9238中
av 是必不可少的依赖项。@comfyanonymous在#9341中
通过以下方式使问题模板中的自定义节点测试复选框成为可选的@webfiltered在#9342中
更新 CODEOWNERS@yoland68在#9343中
通过以下方式更新 Moonvalley 视频节点的默认参数@guill在#9290中
将 WAN 节点转换为 V3 模式@bigcat88在#9201中
使 SLG 节点在 Qwen 图像模型上工作。通过@comfyanonymous在#9345中
避免旧版 PyTorch 出现 Torch 编译 graphbreak@StrongerXi在#9344中
修复上次提交在旧版 PyTorch 上不起作用的问题。@comfyanonymous在#9346中
使用旧版 pytorch 时添加警告。@comfyanonymous在#9347中
修复(OpenAIGPTImage1):通过以下方式为分段上传设置正确的 MIME 类型@bigcat88在#9348中
添加 FluxKontextMultiReferenceLatentMethod 节点。@comfyanonymous在#9356中
实现 wan2.2 摄像头模型。通过@comfyanonymous在#9357中
将前端更新至 v1.25.8@christian-byrne在#9361中
录制音频节点@jtydhr88在#8716中
Qwen 图像模型重构。@comfyanonymous在#9375中
WIP Qwen 编辑模型:扩散模型部分。@comfyanonymous在#9383中
将模板更新至 0.1.60@comfyui-wiki在#9377中
使上下文步骤索引检测更加稳健@Kosinkadink在#9392中
将前端升级到 1.25.9@christian-byrne在#9394中
修复(WAN 节点):WanTrackToVideo 的节点 ID 无效@bigcat88在#9396中
qwen 编辑模型的 P2。由@comfyanonymous在#9412中
api_nodes:通过以下方式添加 kling-v2-1 和 v2-1-master@bigcat88在#9257中
api_nodes:添加 MinimaxHailuoVideoNode 节点@bigcat88在#9262中
api_nodes:通过以下方式添加 GPT-5 系列模型@bigcat88在#9325中
api_nodes:谷歌模型的发布版本@bigcat88在#9304中
feat(api-nodes):添加 Vidu 视频节点@bigcat88在#9368中
更改 TextEncodeQwenImageEdit 节点以使用更接近参考代码的逻辑。通过@comfyanonymous在#9432中
qwen vl 的绳索修复。@comfyanonymous在#9435中
Qwen 旋转嵌入现在应该与参考代码匹配。@comfyanonymous在#9437中
禁用 qwen 的提示权重。通过@comfyanonymous在#9438中
修复 qwen 图像嵌入的 bf16 精度问题。通过@comfyanonymous在#9441中
将模板升级至 0.1.62@comfyui-wiki在#9419中
本整合包为comfyui官方制作优化的windows NVIDIA版一键启动整合包,下载解压后直接双击启动
如果报错无法启动的话,99%原因是驱动问题,更新英伟达显卡驱动到最新版即可
comfyui官方原版一键启动整合包下载链接:
https://pan.quark.cn/s/6628be3a39c8
相关推荐


最近更新
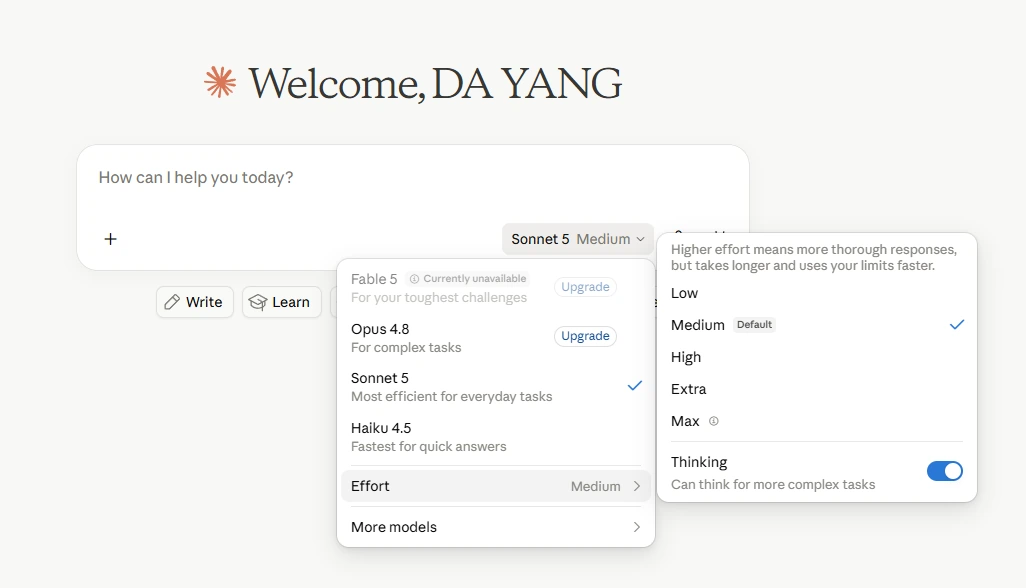
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
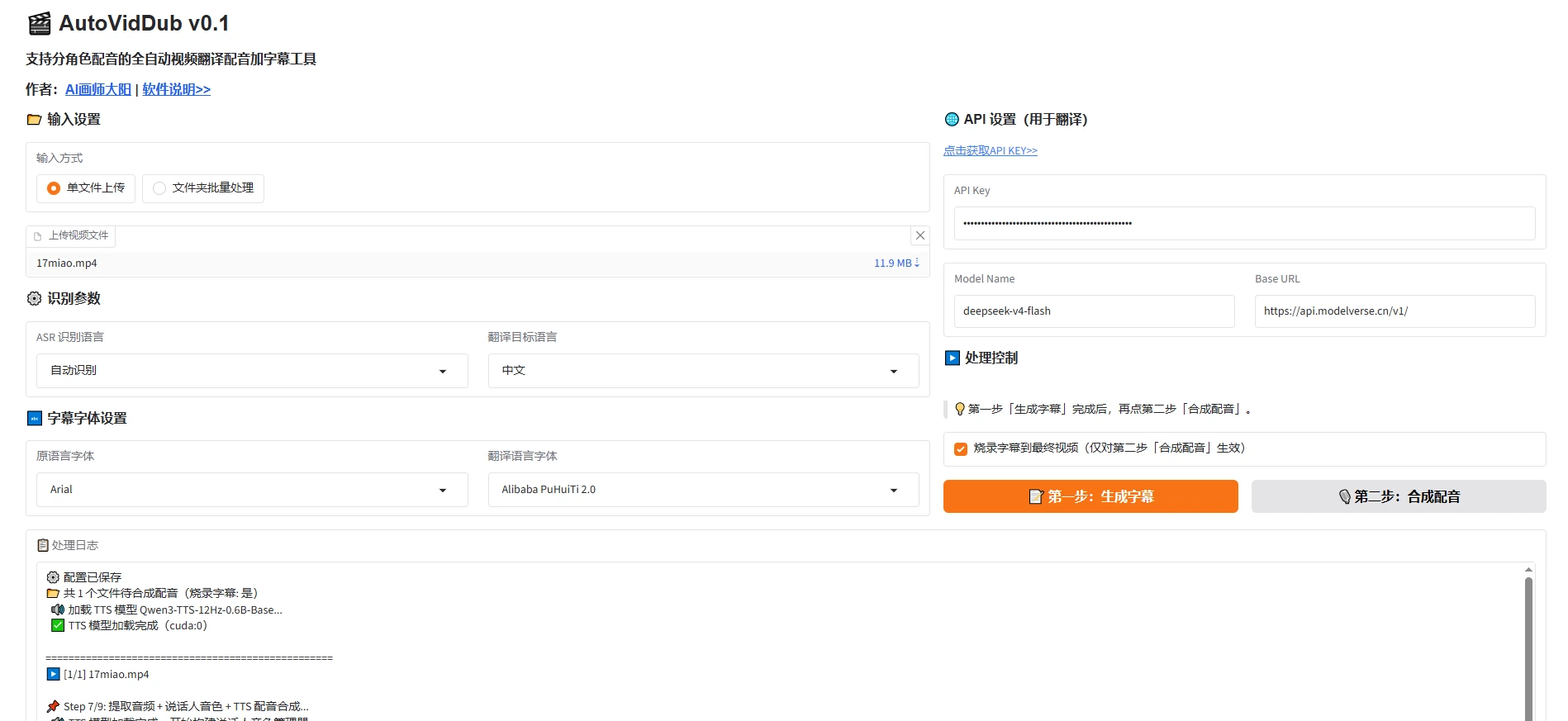
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
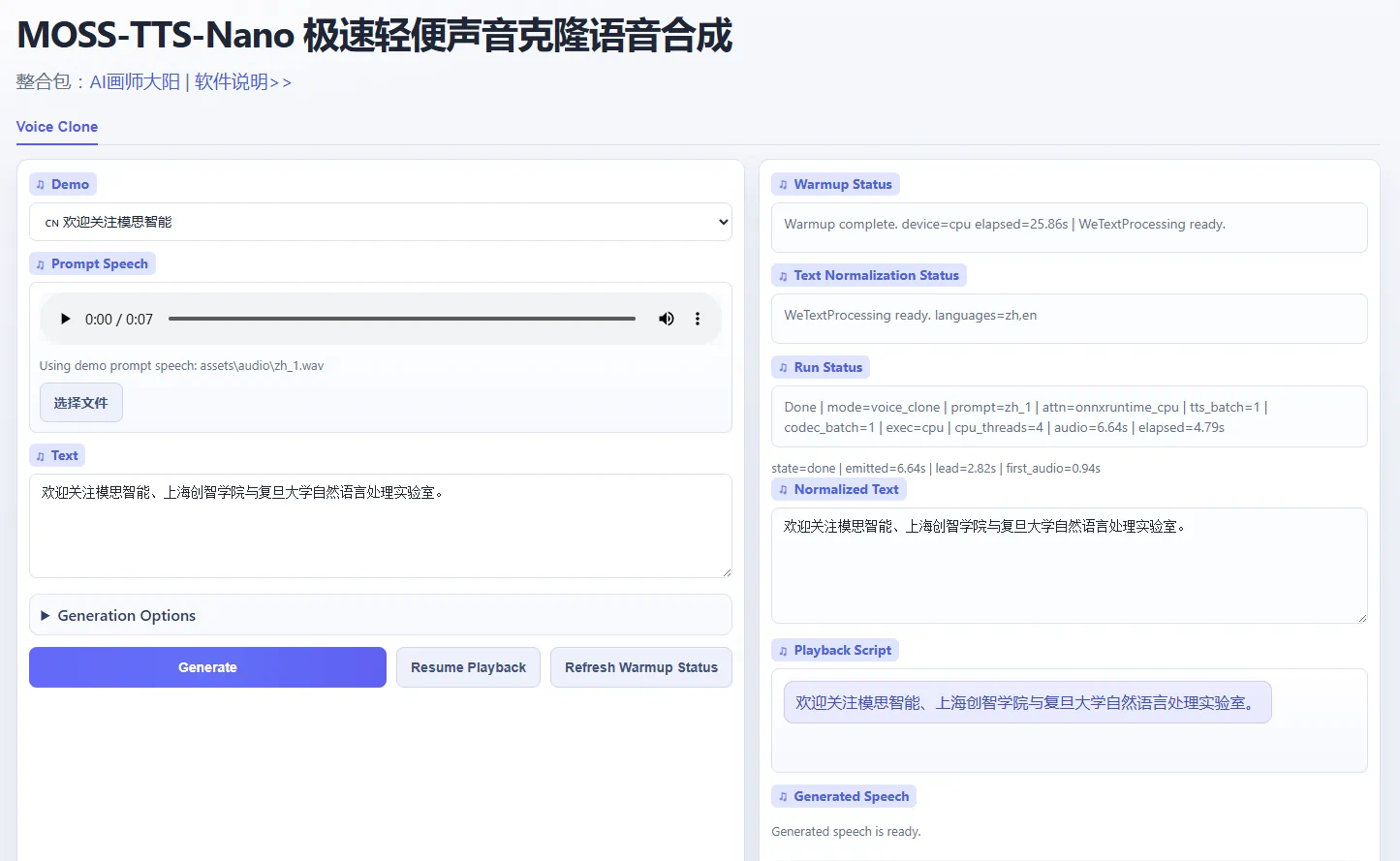
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
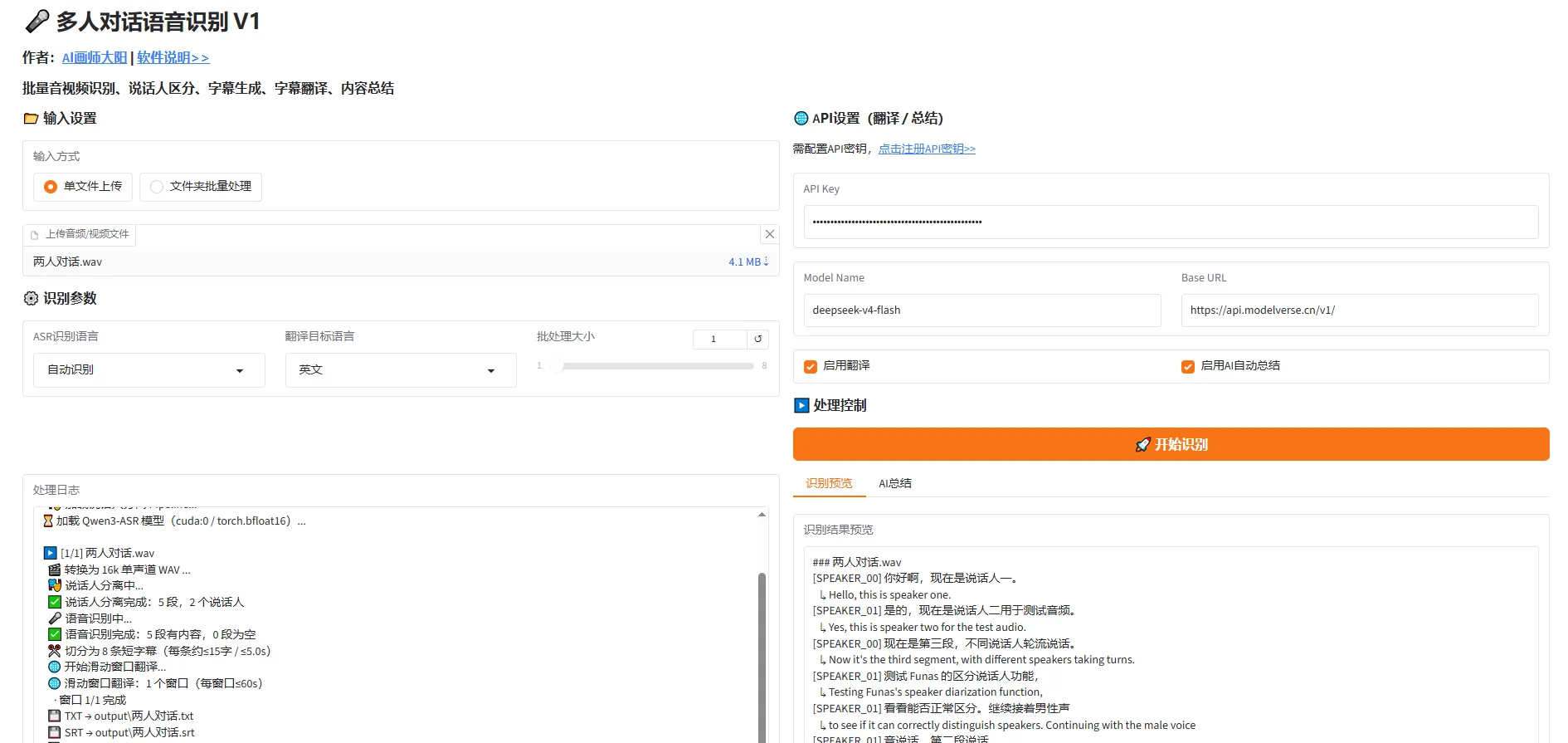
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
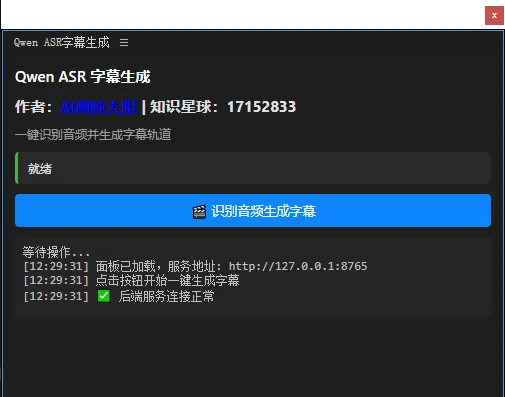
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
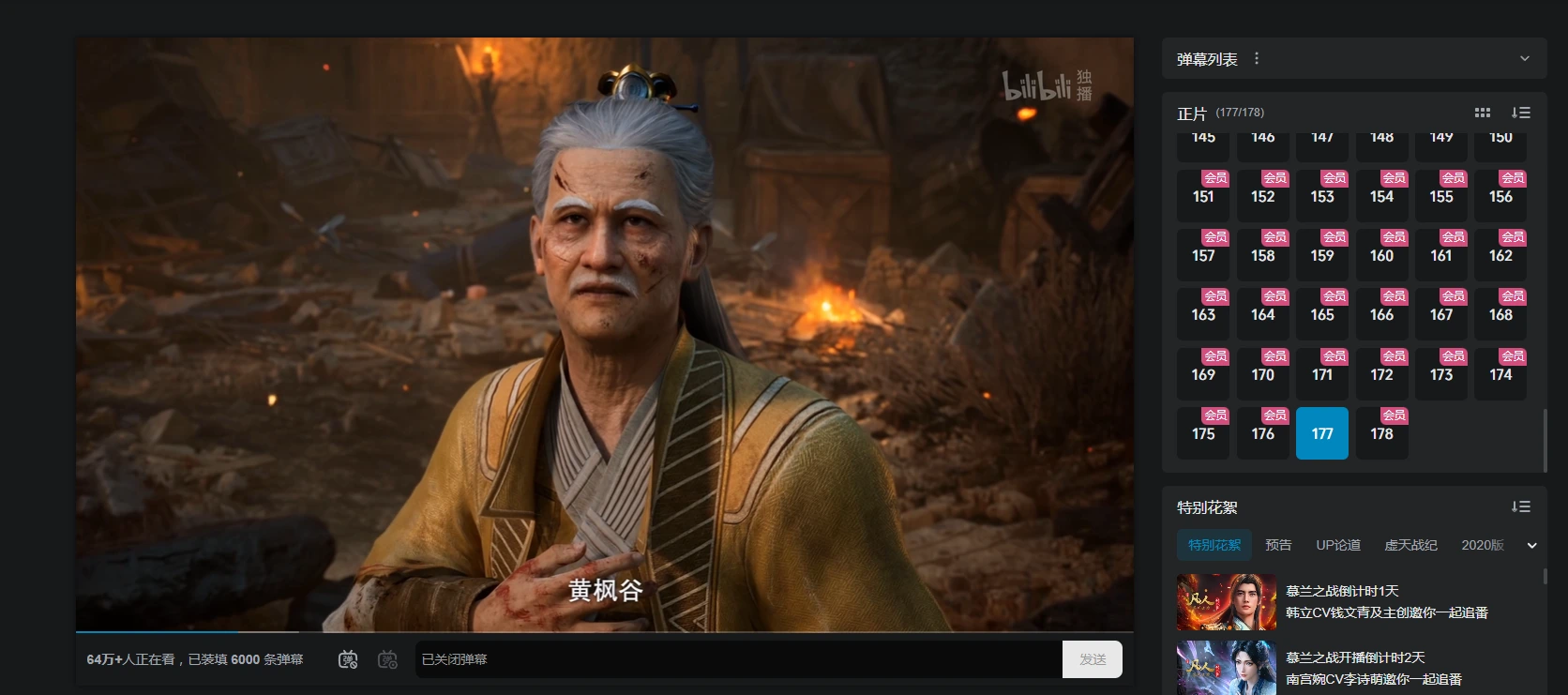
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
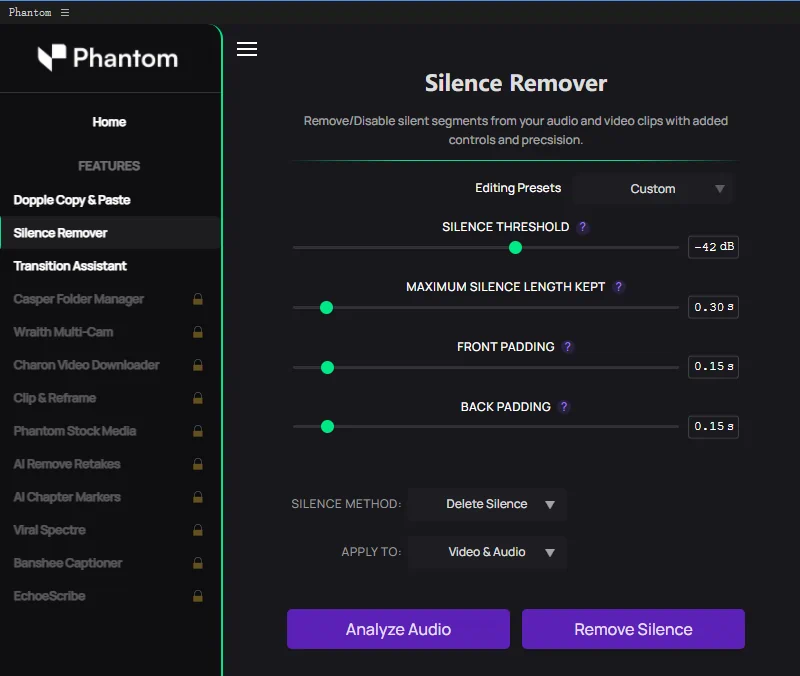
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
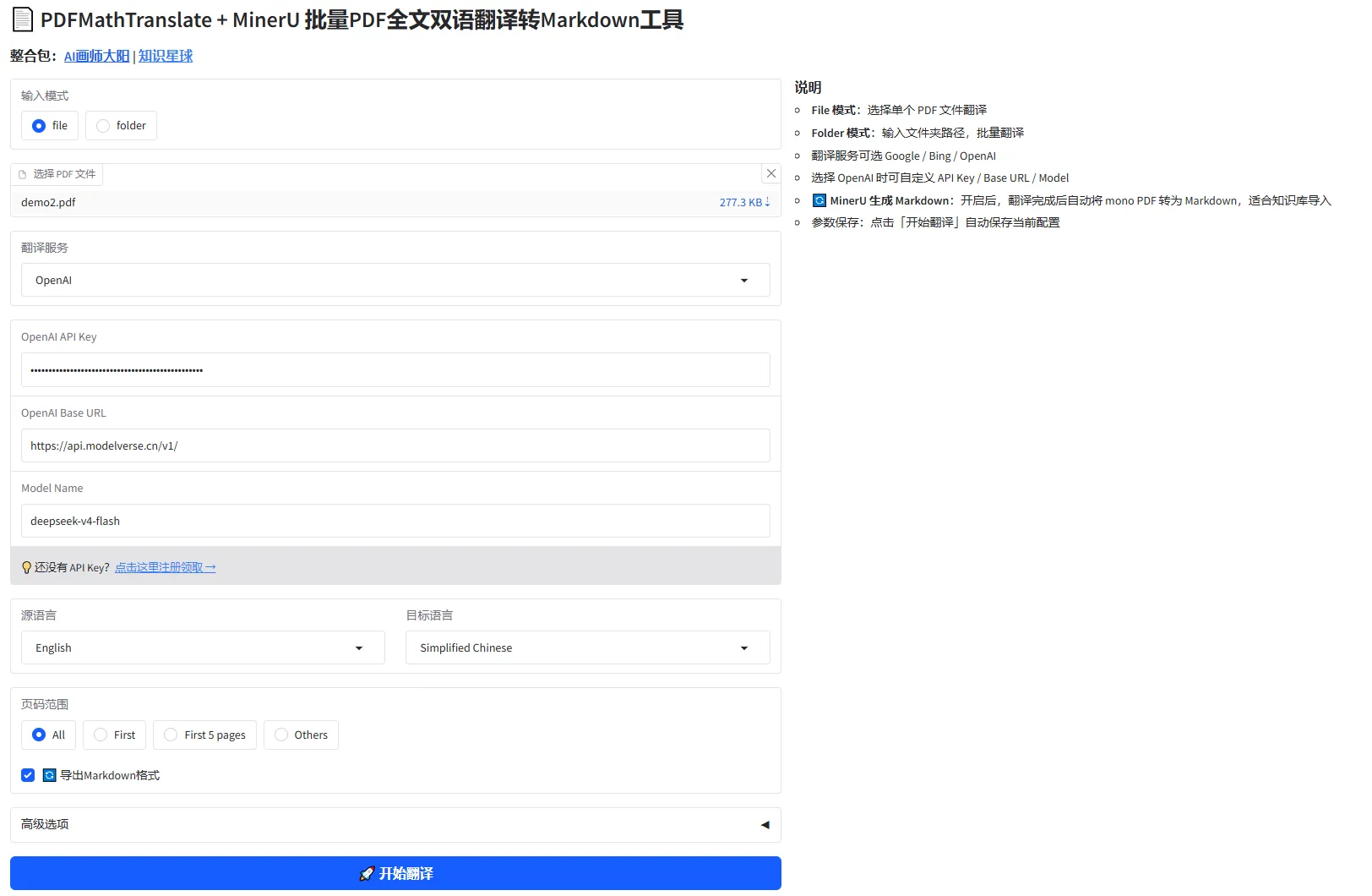
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...