LTX-2 是由 Lightricks 开发的首个基于 DiT(扩散变换器)架构的音视频基础模型,能够在一个统一模型中同时生成高质量的视频与同步音频。与以往需要分别处理视频和音频的方案不同,LTX-2 将两者深度融合,实现真正的音画同步生成。
模型文件说明
本应用首次使用某功能时会按需自动下载对应模型,请确保网络畅通或提前将网盘内模型文件下载到项目文件夹内。模型保存在项目根目录的 checkpoints/ 文件夹,Gemma 文本编码器保存在 gemma/ 文件夹。
| 模型文件 | 用途 | 大小(约) |
|---|---|---|
ltx-2.3-22b-dev.safetensors | 开发版主模型,画质最佳 | ~44 GB |
ltx-2.3-22b-distilled-1.1.safetensors | 蒸馏版主模型,速度最快 | ~44 GB |
ltx-2.3-spatial-upscaler-x2-1.1.safetensors | 2× 空间上采样器 | ~1 GB |
ltx-2.3-22b-distilled-lora-384-1.1.safetensors | 蒸馏 LoRA(辅助两阶段生成) | ~7GB |
gemma-3-12b-it-qat-q4_0-unquantized(完整目录) | 文本编码器 | ~22.7 GB |
LTX2.3整合包软件功能介绍
八大功能详解
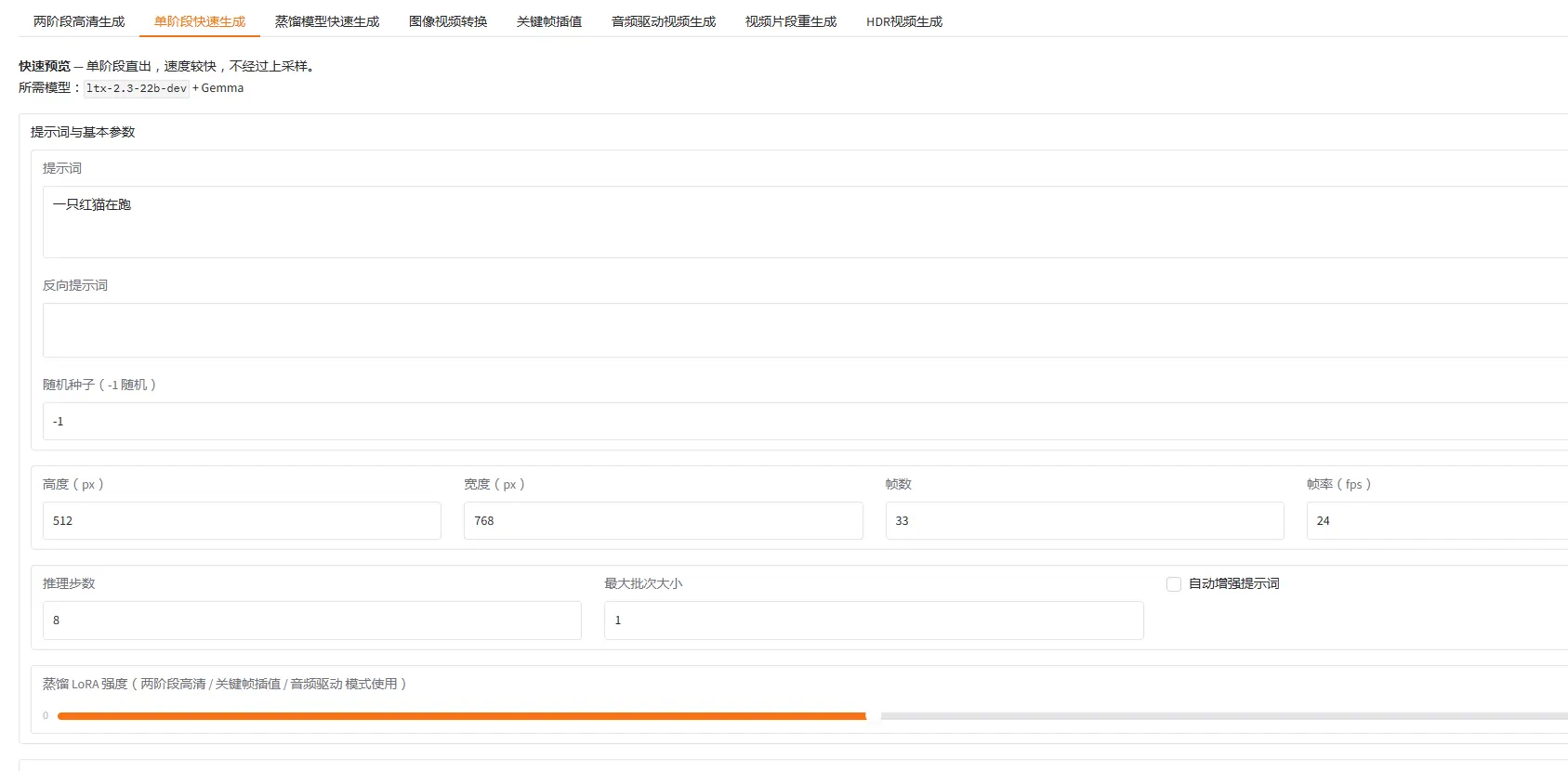
1. 两阶段高清生成(推荐)
适用场景:追求最佳画质的正式出片。
工作原理:先用开发版主模型生成低分辨率草图,再通过 2× 空间上采样器将分辨率翻倍,兼顾内容质量与细节清晰度。
所需模型:ltx-2.3-22b-dev + spatial-upscaler-x2 + distilled-lora + Gemma
使用步骤:
- 切换到「两阶段高清生成」Tab
- 在「提示词与基本参数」中填写提示词,设置尺寸和帧数
- 调整「蒸馏 LoRA 强度」(默认 1.0,范围 0~2,过高可能过度锐化)
- 点击「开始生成」
注意事项:
- 生成时间较长,适合最终出片而非快速预览
- 建议推理步数设置为 20~40
2. 蒸馏模型快速生成
适用场景:对速度要求极高的场景,或显存有限的环境。
工作原理:使用经过知识蒸馏的模型,仅需 8 步固定 sigma 推理即可生成视频,配合空间上采样器输出。
所需模型:ltx-2.3-22b-distilled + spatial-upscaler-x2 + Gemma
使用步骤:
- 切换到「蒸馏模型快速生成」Tab
- 填写提示词,设置参数
- 点击「开始生成」
注意事项:
- 推理步数固定为 8 步,修改「推理步数」参数对此模式无效
- 速度最快,但画质和细节丰富度略低于两阶段高清
- 此模式不使用蒸馏 LoRA,无需设置「蒸馏 LoRA 强度」
3. 图像视频转换
适用场景:基于参考图像或参考视频,生成风格一致、动作受控的新视频(IC-LoRA)。
所需模型:ltx-2.3-22b-distilled + spatial-upscaler-x2 + Gemma
Tab 内专属参数:
| 参数 | 说明 |
|---|---|
| 参考视频文件 | 上传一个或多个参考视频,作为条件引导生成 |
| 参考视频强度 | 每个参考视频的影响强度(0~1+),逗号分隔,如 0.8,0.6 |
| 跳过第二阶段上采样 | 勾选后跳过高分辨率阶段,速度更快但分辨率不翻倍 |
| 注意力强度 | 控制参考视频的注意力影响程度(0.0~1.0),越大越贴近参考内容 |
| 遮罩视频(可选) | 上传遮罩视频,白色区域受参考条件影响,黑色区域自由生成 |
使用步骤:
- 上传参考视频(支持多个)
- 设置每个视频的强度,如
1.0或0.8,0.6 - 在「图像条件」Accordion 中上传参考图像(可选)
- 填写描述目标视频内容的提示词
- 点击「开始生成」
注意事项:
- 参考视频数量与强度值数量需对应;若值少于文件数,最后一个值自动补全
- 遮罩视频尺寸会自动缩放为生成尺寸的一半
4. 关键帧插值
适用场景:给定若干关键帧图像,生成它们之间平滑过渡的视频片段。
所需模型:ltx-2.3-22b-dev + spatial-upscaler-x2 + distilled-lora + Gemma
使用步骤:
- 切换到「关键帧插值」Tab
- 展开下方「图像条件(可选)」Accordion
- 上传多张关键帧图像
- 在「帧索引」中填写每张图对应的帧号,如
0,16,32(帧号从 0 开始,间隔表示插值帧数) - 在「强度」中填写各关键帧的影响强度,如
1.0,1.0,1.0 - 填写描述整体动作/场景的提示词
- 确保「帧数」≥ 最大帧索引 + 1
- 点击「开始生成」
注意事项:
- 关键帧数量、帧索引数量、强度值数量需一致
- 第一帧索引通常设为
0,最后一帧索引设为num_frames - 1 - 蒸馏 LoRA 强度影响插值的平滑程度,推荐保持默认值 1.0
5. 音频驱动视频生成
适用场景:以音乐或语音为驱动,生成与音频节奏同步的视频内容。
所需模型:ltx-2.3-22b-dev + spatial-upscaler-x2 + distilled-lora + Gemma
Tab 内专属参数:
| 参数 | 说明 |
|---|---|
| 音频文件 | 上传 WAV、MP3 等格式的音频文件 |
| 音频开始时间(秒) | 从音频的第几秒开始使用(默认 0) |
| 最大时长(秒) | 使用多长的音频片段(0 表示自动,与视频帧数匹配) |
使用步骤:
- 切换到「音频驱动视频生成」Tab
- 上传音频文件
- 设置开始时间和最大时长(通常保持默认)
- 填写提示词,描述视频的视觉内容
- 设置「帧数」和「帧率」,让视频时长与音频时长匹配
- 点击「开始生成」
注意事项:
- 音频文件为必填项,不上传会报错
- 视频时长 = 帧数 ÷ 帧率,建议与使用的音频时长保持一致
- 可在「图像条件」中上传参考图像来影响视觉风格
6. 视频片段重生成
适用场景:对已有视频中某段不满意的片段进行局部重新生成,其余部分保持不变。
所需模型:ltx-2.3-22b-distilled + Gemma
Tab 内专属参数:
| 参数 | 说明 |
|---|---|
| 源视频文件 | 上传需要局部修改的原始视频 |
| 开始时间(秒) | 要重生成的片段起点 |
| 结束时间(秒) | 要重生成的片段终点 |
| 重生成视频轨 | 勾选后重新生成该时间段的视频画面 |
| 重生成音频轨 | 勾选后重新生成该时间段的音频 |
| 使用蒸馏模型 | 勾选使用快速蒸馏模型,取消勾选则使用全量推理(需手动设置引导参数) |
使用步骤:
- 切换到「视频片段重生成」Tab
- 上传源视频
- 设置开始和结束时间(精确到秒)
- 选择是否重生成视频轨和/或音频轨
- 填写提示词(描述重生成片段的目标内容)
- 点击「开始生成」
注意事项:
- 「源视频文件」为必填项,不上传会报错
- 时间范围外的部分保持原样不变
- 使用蒸馏模型时,引导参数将自动使用预设值,手动修改无效
7. HDR 视频生成
适用场景:专业影视后期制作,需要高动态范围(HDR)素材,用于专业调色、色调映射和合成。
所需模型:ltx-2.3-22b-distilled + spatial-upscaler-x2 + HDR IC-LoRA
Tab 内专属参数:
| 参数 | 说明 |
|---|---|
| 参考视频文件 | 上传 SDR 参考视频,作为 HDR 转换的基础 |
| 参考视频强度 | 各参考视频的条件强度(逗号分隔) |
| 空间分块大小 | 控制上采样时的分块尺寸,默认 1280,影响显存占用 |
| 仅输出 EXR | 勾选后只保存 EXR 序列,不生成 MP4 预览 |
| EXR 半精度 | 使用 float16 保存 EXR,文件更小但精度略降 |
| 高质量模式 | 启用更精细的 HDR 处理流程(速度更慢) |
使用步骤:
- 切换到「HDR视频生成」Tab
- 上传参考 SDR 视频
- 点击「开始生成」
输出说明:
- 输出为 EXR 帧序列(LogC3 编码的线性光照数据),保存在
output/hdr_XXXXXX_exr/目录 - 默认同时生成一个 MP4 预览文件(可勾选「仅输出 EXR」跳过)
- EXR 文件需在 DaVinci Resolve、Nuke 等专业软件中进行色调映射后才能正常显示
注意事项:
- 空间分块大小越大显存占用越高,OOM 时可适当减小
通用参数说明
提示词与基本参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| 提示词 | 空 | 描述视频内容,建议详细描述动作、场景、镜头、光影(参见下方提示词写作技巧) |
| 反向提示词 | 空 | 描述不希望出现的内容,如 blurry, low quality |
| 随机种子 | -1 | -1 为随机;固定值可复现相同结果 |
| 高度 / 宽度(px) | 512 / 768 | 生成分辨率 |
| 帧数 | 33 | 生成的总帧数,视频时长 = 帧数 ÷ 帧率 |
| 帧率(fps) | 24 | 输出视频帧率 |
| 推理步数 | 8 | 扩散去噪步数,越多质量越好但速度越慢(蒸馏模式固定 8 步) |
| 最大批次大小 | 1 | 并行处理的分块数,增大可加速但需要更多显存 |
| 自动增强提示词 | 否 | 开启后用 Gemma 自动扩写提示词,适合短提示词 |
| 蒸馏 LoRA 强度 | 1.0 | 两阶段/关键帧/音频驱动模式专用,影响第二阶段细节锐化程度 |
图像条件(可选)
上传参考图像,为生成视频提供视觉锚点。
| 参数 | 说明 |
|---|---|
| 条件图像文件 | 上传一张或多张图像(关键帧插值模式必须在此上传) |
| 帧索引 | 每张图像对应视频中的哪一帧(从 0 开始),逗号分隔 |
| 强度 | 每张图像对生成内容的影响程度,逗号分隔 |
| CRF | 图像压缩质量(值越小质量越高,通常保持默认 33) |
运行参数
| 参数 | 说明 |
|---|---|
| 显存卸载模式 | none:全部放显存;cpu:部分卸载到内存;disk:卸载到硬盘(最省显存但最慢) |
| 量化模式 | none:全精度;fp8-cast:动态 FP8 量化(40/50系列可开启);fp8-scaled-mm:Hopper GPU 专用 |
| Torch 编译加速 | 首次启用时编译耗时约几分钟,之后每次生成明显加速 |
| 附加 LoRA | 每行一条,格式:/path/to/lora.safetensors,0.8 |
引导参数(高级)
控制扩散过程的引导强度,一般无需修改。
| 参数 | 建议范围 | 说明 |
|---|---|---|
| cfg_scale | 2~7 | 分类器引导强度,越大越贴合提示词但可能过饱和 |
| stg_scale | 0~2 | 跳步引导强度 |
| rescale_scale | 0.5~0.9 | 引导缩放补偿,防止过度饱和 |
| modality_scale | 1~5 | 多模态(音视频)对齐强度 |
| skip_step | 0 | 跳过的初始步数 |
| stg_blocks | 28 | 应用跳步引导的 Transformer 块索引 |
提示词写作技巧
LTX-2 使用 Gemma 进行深度语义理解,支持详细的自然语言描述。保持描述精确具体,像电影分镜表一样思考。建议控制在 200 词以内。
输出与设置保存
输出文件
生成的视频保存在项目根目录的 output/ 文件夹,文件名格式为:
output/{功能名称}_{日期时间}.mp4
HDR 模式额外生成:
output/hdr_{日期时间}_exr/frame_00000.exr
output/hdr_{日期时间}_exr/frame_00001.exr
...
设置保存
- 手动保存:点击「保存设置」按钮
- 自动保存:每次点击「开始生成」时自动保存当前所有参数
- 设置文件保存路径:
{项目根目录}/settings.json - 下次打开应用时,所有参数会自动从
settings.json恢复
常见问题
Q:首次运行需要多少存储空间?
A:完整下载所有模型约需 100 GB 以上空间(dev 模型 ~44 GB、distilled 模型 ~44 GB、Gemma ~22.7 GB、上采样器等)。如果只使用特定功能,只下载对应模型。
项目文件夹目录结构为:
--LTX2.3
--checkpoints
--ltx-2.3-22b-distilled-1.1.safetensors
--以及其它.safetensors模型文件
--gemma
--hf
--output
--..Q:最低显存要求是多少?
A:显存较低时可启用「量化模式」(fp8-cast,RTX30或更低系列不要开启)+ 「显存卸载模式」(cpu 或 disk)组合使用。英伟达显卡显存越低速度越慢,如果不想长时间等待,建议显存大于12GB。
Q:生成结果和提示词不符?
A:
- 增大
cfg_scale(如从 3 调到 5~7) - 提示词更具体,描述更详细
- 开启「自动增强提示词」
- 增加「推理步数」
Q:视频中出现闪烁或不连贯?
A:适当增大 stg_scale 或降低 cfg_scale,也可以尝试不同的随机种子。
LTX2.3音视频生成软件下载链接
https://pan.quark.cn/s/41e4da892a11
相关推荐




最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
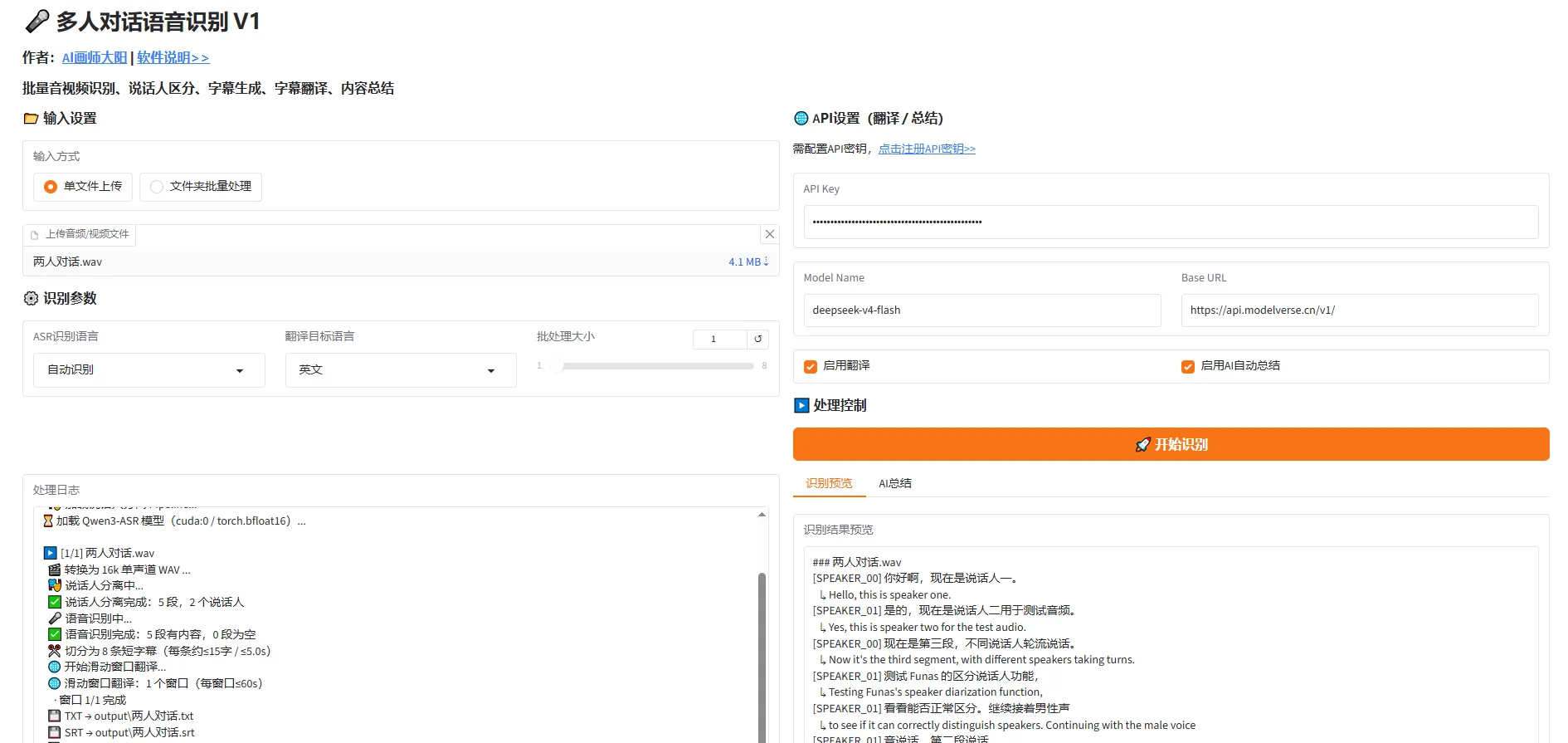
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
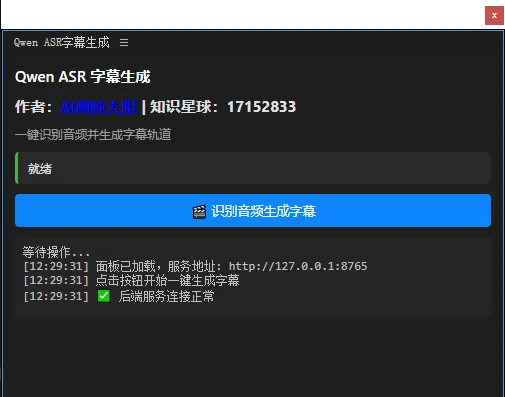
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
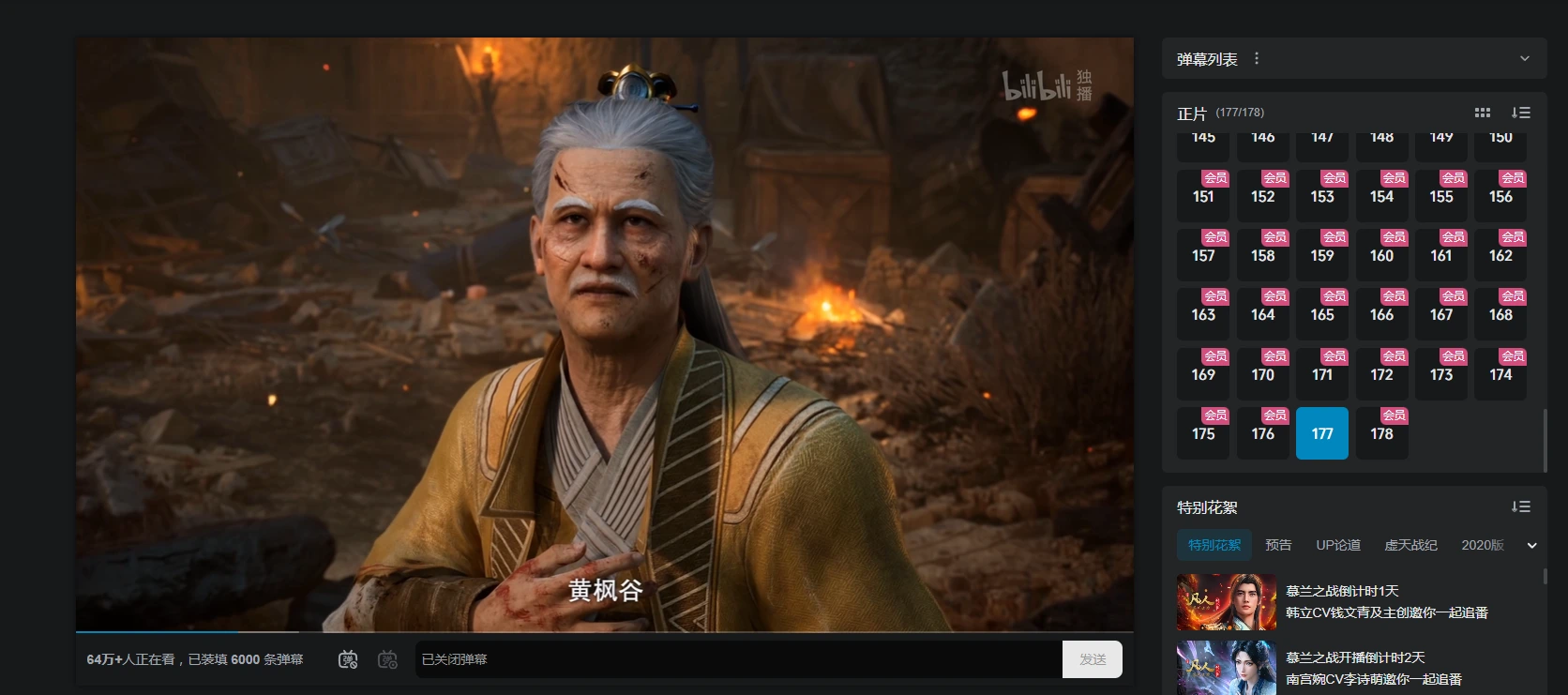
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
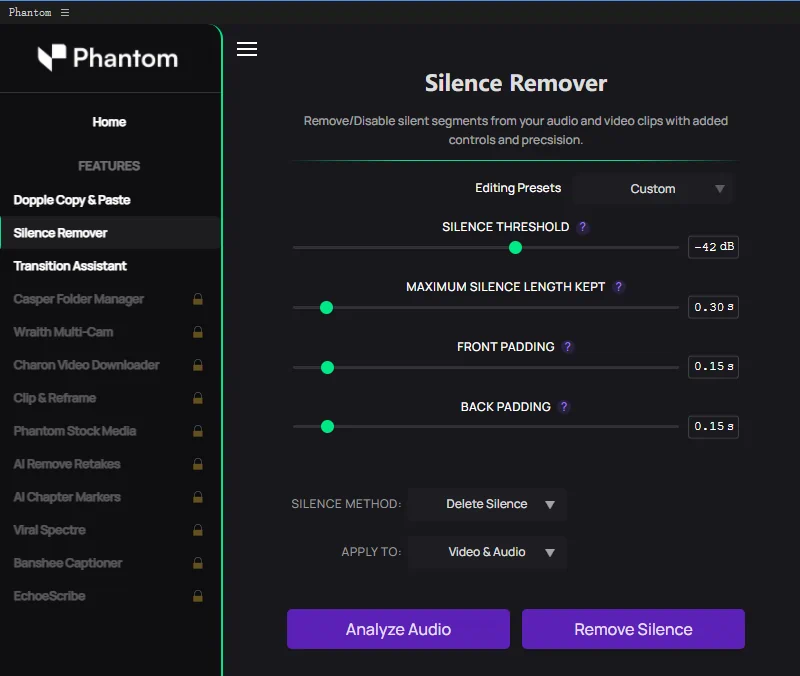
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
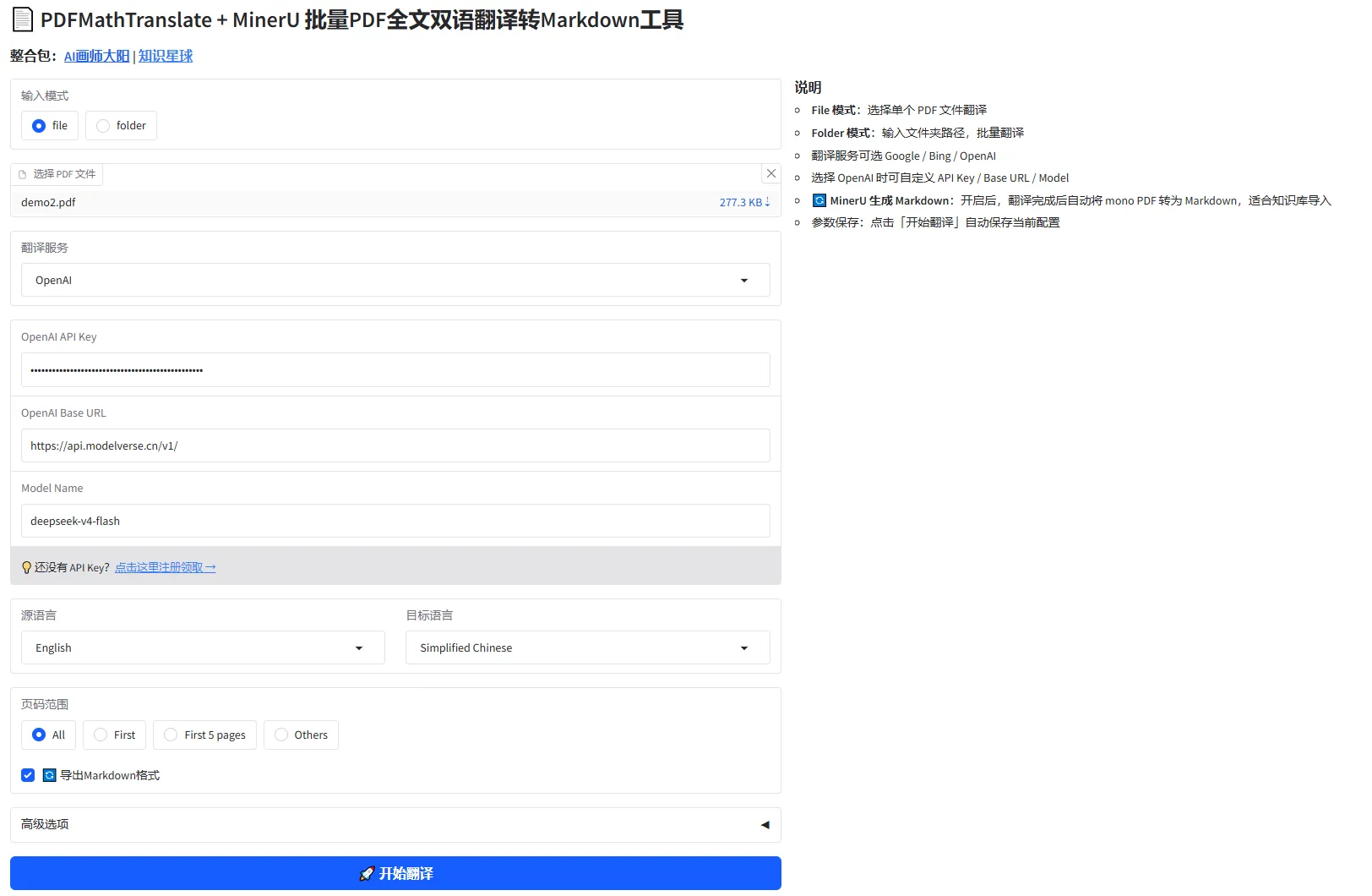
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...