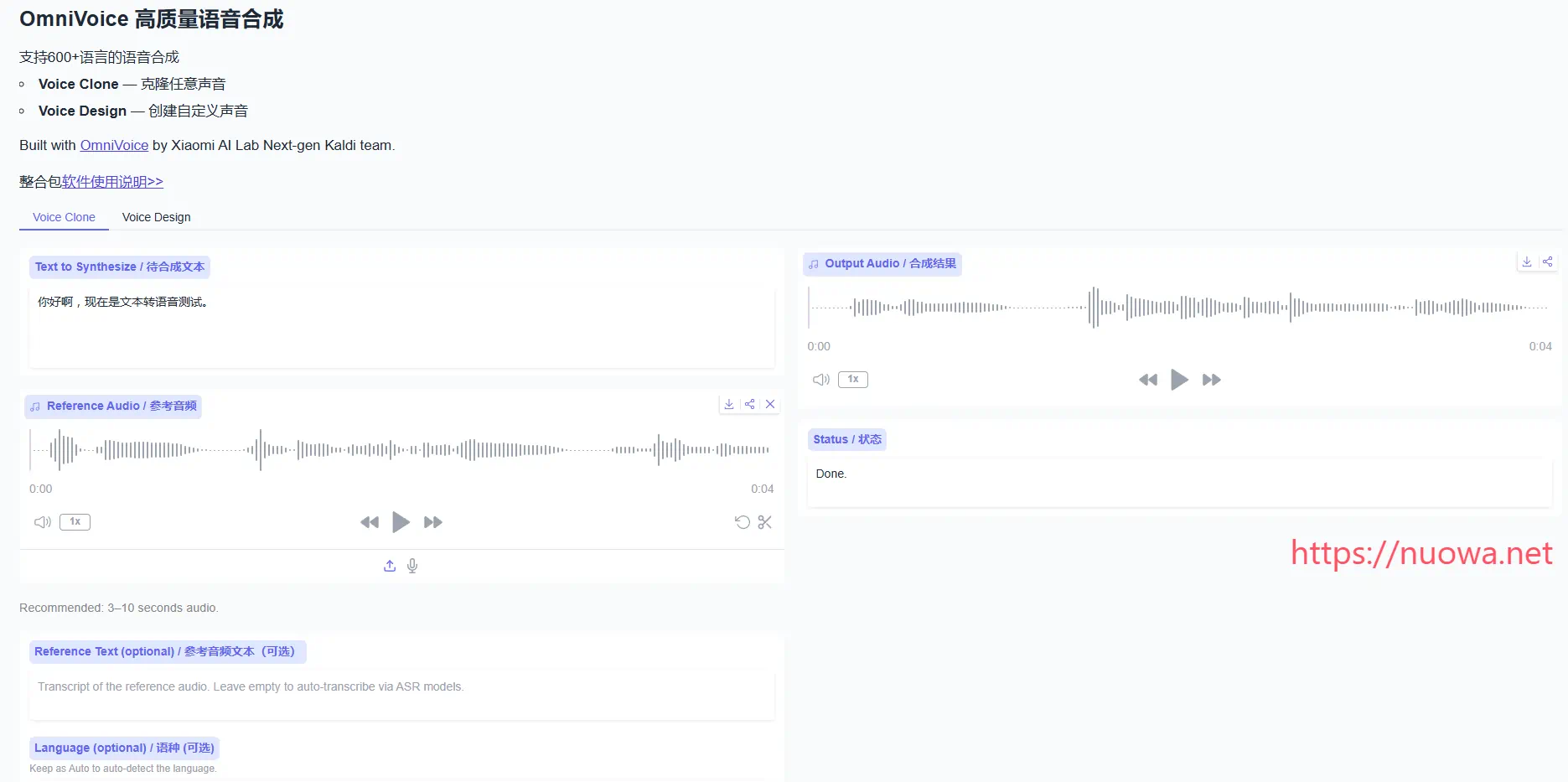
本次和大家分享一个非常强大的动作模仿及视频人物替换工具Wan2.2-Animate-14B,Wan-Animate接受一个视频和一个角色图像作为输入,并生成一个动作模仿或人物替换的视频,视频自然流畅,可玩性非常高。
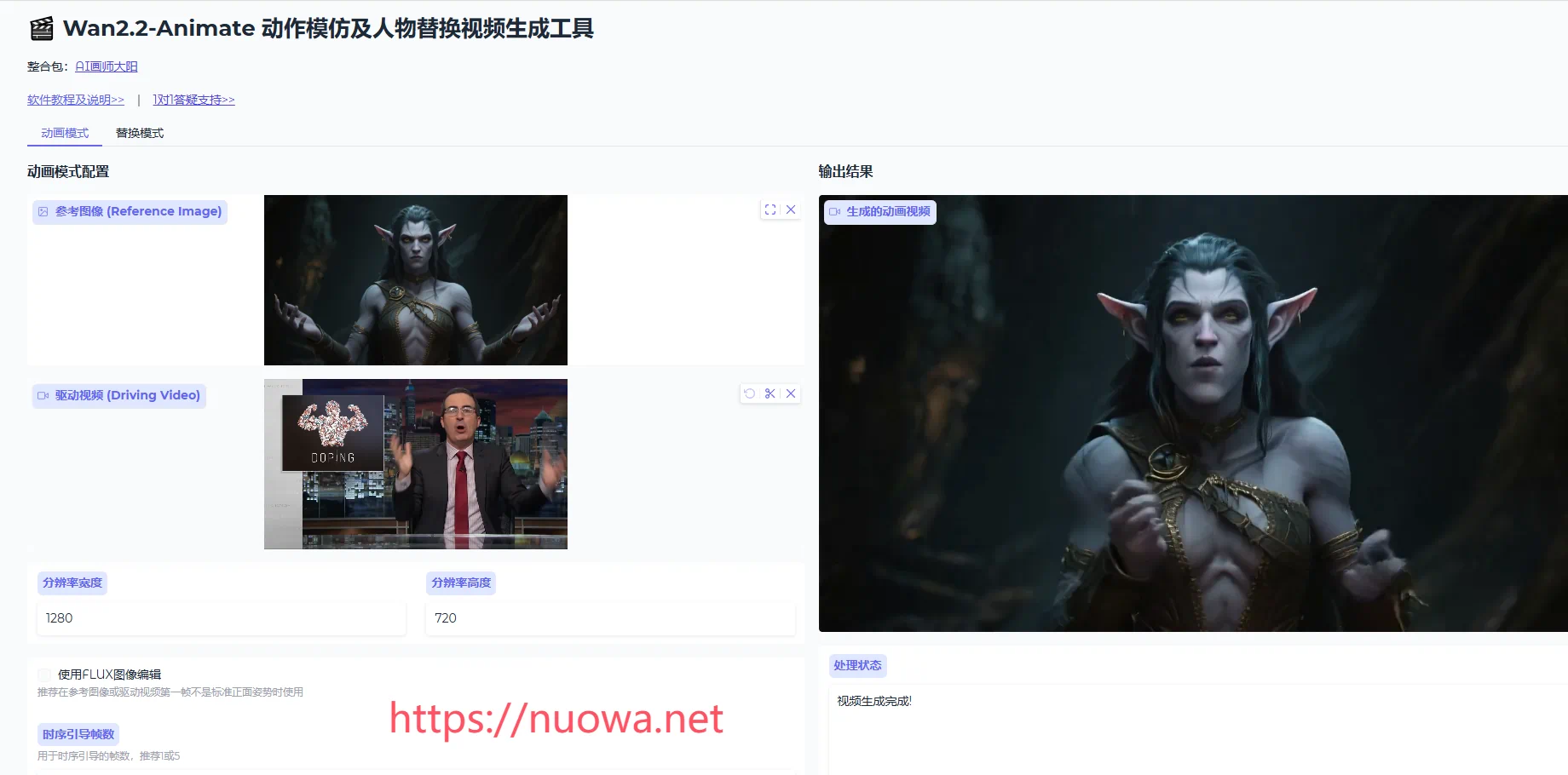
Wan2.2-Animate-14B官方介绍
Wan2.2是我们基础视频模型的一次重大升级。在 Wan2.2 中,我们专注于引入以下创新:
- 👍 有效的 MoE 架构:Wan2.2 在视频扩散模型中引入了混合专家(MoE)架构。通过用专门的强大专家模型跨时间步分离去噪过程,这扩大了整体模型容量,同时保持相同的计算成本。
- 👍 电影级美学:Wan2.2 引入了精心策划的美学数据,包括详细的照明、构图、对比度、色调等标签。这使得能够更精确和可控地生成电影风格,并有助于创建具有可定制美学偏好的视频。
- 👍 复杂的运动生成:与 Wan2.1 相比,Wan2.2 的训练数据量显著增加,图像增加了 +65.6%,视频增加了 +83.2%。这种扩展显著增强了模型在多个维度上的泛化能力,如运动、语义和美学,在所有开源和闭源模型中达到顶级性能。
- 👍 高效的高清混合 TI2V:Wan2.2 开源了一个基于我们先进的 Wan2.2-VAE 构建的 5B 模型,实现了 16×16×4 的压缩比。该模型支持 720P 分辨率、24fps 的文本到视频和图像到视频生成,并且可以在像 4090 这样的消费级显卡上运行。它是目前最快的 720P@24fps 模型之一,能够同时服务于工业界和学术界。
Wan2.2-Animate-14B整合包使用说明
首先将网盘内的软件压缩包下载到本地电脑上并解压,然后双击启动.bat。
第一次使用时会自动下载模型文件,模型文件总共约67G,注意硬盘剩余容量
软件启动成功后会自动打开WebUI界面
Wan-Animate 支持两种模式:
- 动画模式: 用视频素材中提取的人物动作,驱动图片素材中的角色运动,包括面部表情
- 替换模式: 用图片素材中的角色,替换视频素材中的角色
当前,对于输入有以下的限制
- 视频文件大小: 小于 200MB
- 视频分辨率: 最小边大于 200, 最大边小于2048
- 视频时长: 2s ~ 30s
- 视频比例:1:3 ~ 3:1
- 视频格式: mp4, avi, mov
- 图片文件大小: 小于5MB
- 图片分辨率:最小边大于200,最大边小于4096
- 图片格式: jpg, png, jpeg, webp, bmp
动画模式: 上传一张人物图片和一个驱动视频,模型将让图片中的人物按照视频中的动作运动。
替换模式: 上传一张目标人物图片和一个包含源人物的视频,模型将用目标人物替换视频中的源人物。
参数说明:
- 分辨率: 处理的目标分辨率,保持原始宽高比
- FLUX图像编辑: 在姿势重定向时使用,改善非标准姿势的处理
- 掩码参数: 控制替换模式中掩码的大小和形状
- 时序引导帧数: 影响时间一致性的帧数
- 重光照LoRA: 在替换模式中改善光照一致性
软件首先会对图片视频素材进行预处理,这个过程使用CPU处理的。然后会进行视频合成,这个过程使用GPU处理。
视频生成是一个复杂漫长的过程,如果软件没有报错停止,那就是在处理中,可以通过任务管理器查看CPU或GPU使用率是否高负荷运行,如果使用率极高就说明软件正在运行中,请耐心等待。或通过WEBUI界面【处理状态】查看软件是否正在处理中,软件处理完成或是报错终止都会有提示信息。
生成视频分辨率默认720*1280,最好和视频素材保持一致
视频教程及效果演示:https://nuowa.net/2256
注意事项
只支持Windows 10或11
需要英伟达独显,16G显存可运行,但是耗时极长,建议3090或更高显卡用户使用
电脑内存大于40G
支持英伟达50系列显卡
软件运行路径中不要有非英文字符和空格
视频素材帧率不宜过大,不影响观看的前提下帧率越低越好。
图片素材和视频素材尺寸比例要保持一致,如都是16:9或9:16等
生成720P视频的话建议时长在10秒内
windows电脑版Wan2.2-Animate-14B整合包下载
在线一键启动链接
相关推荐

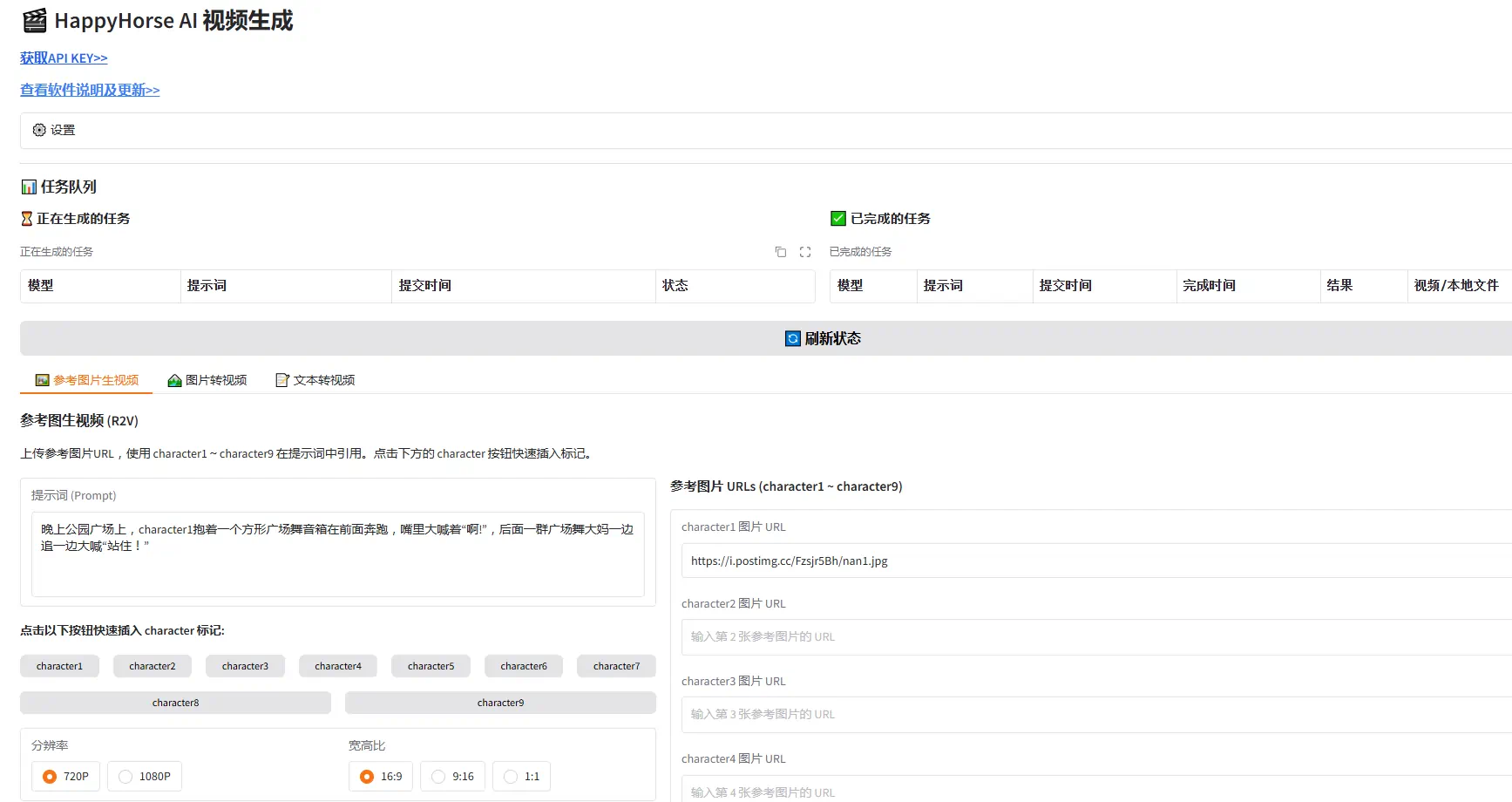
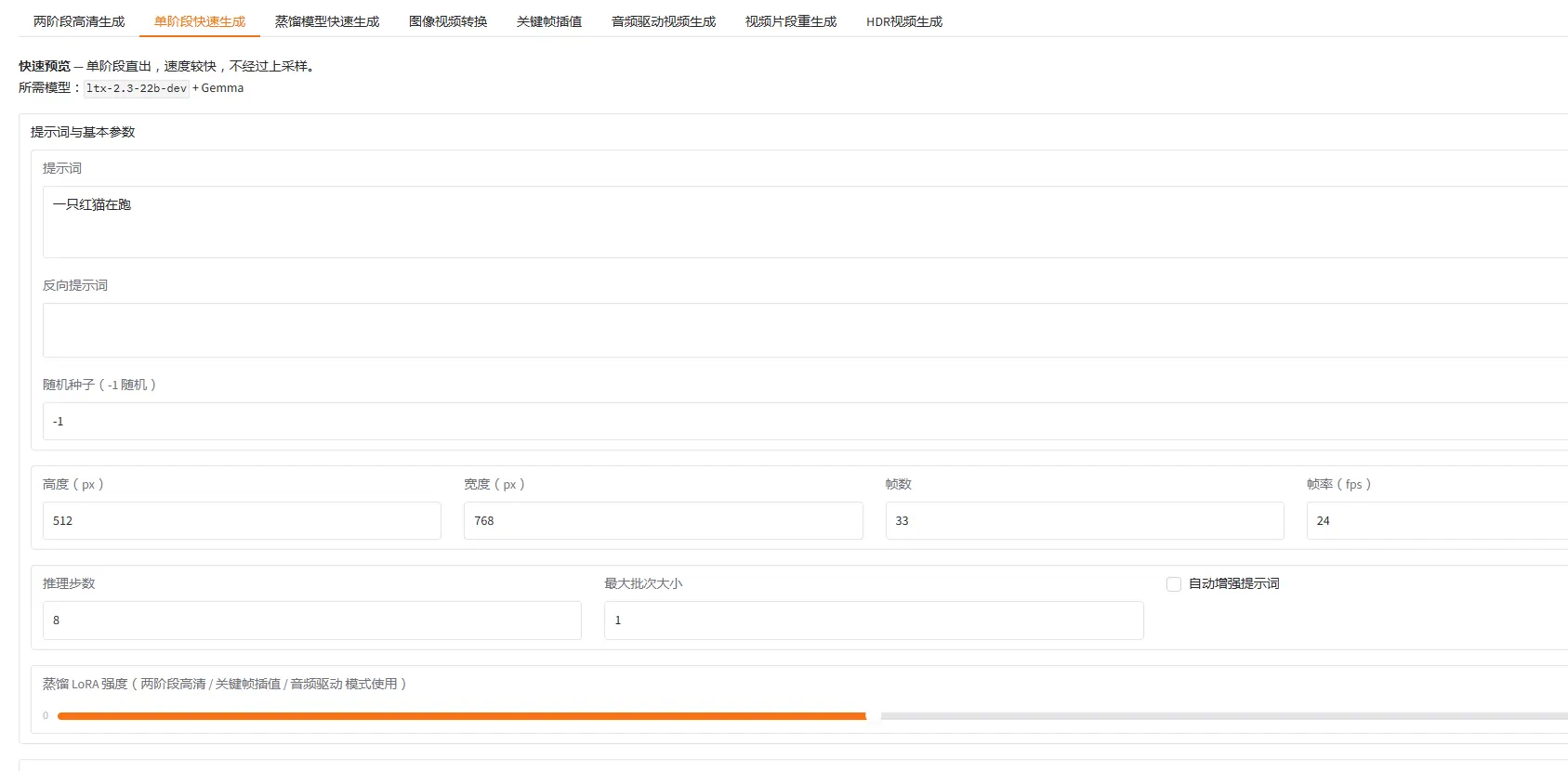
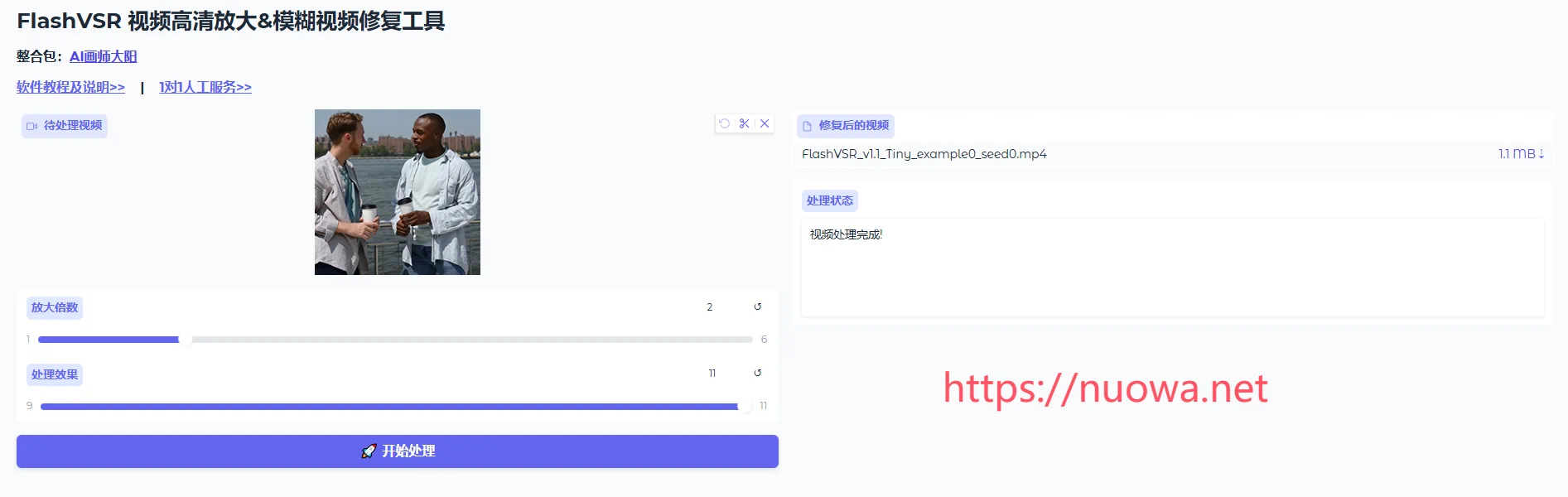

最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
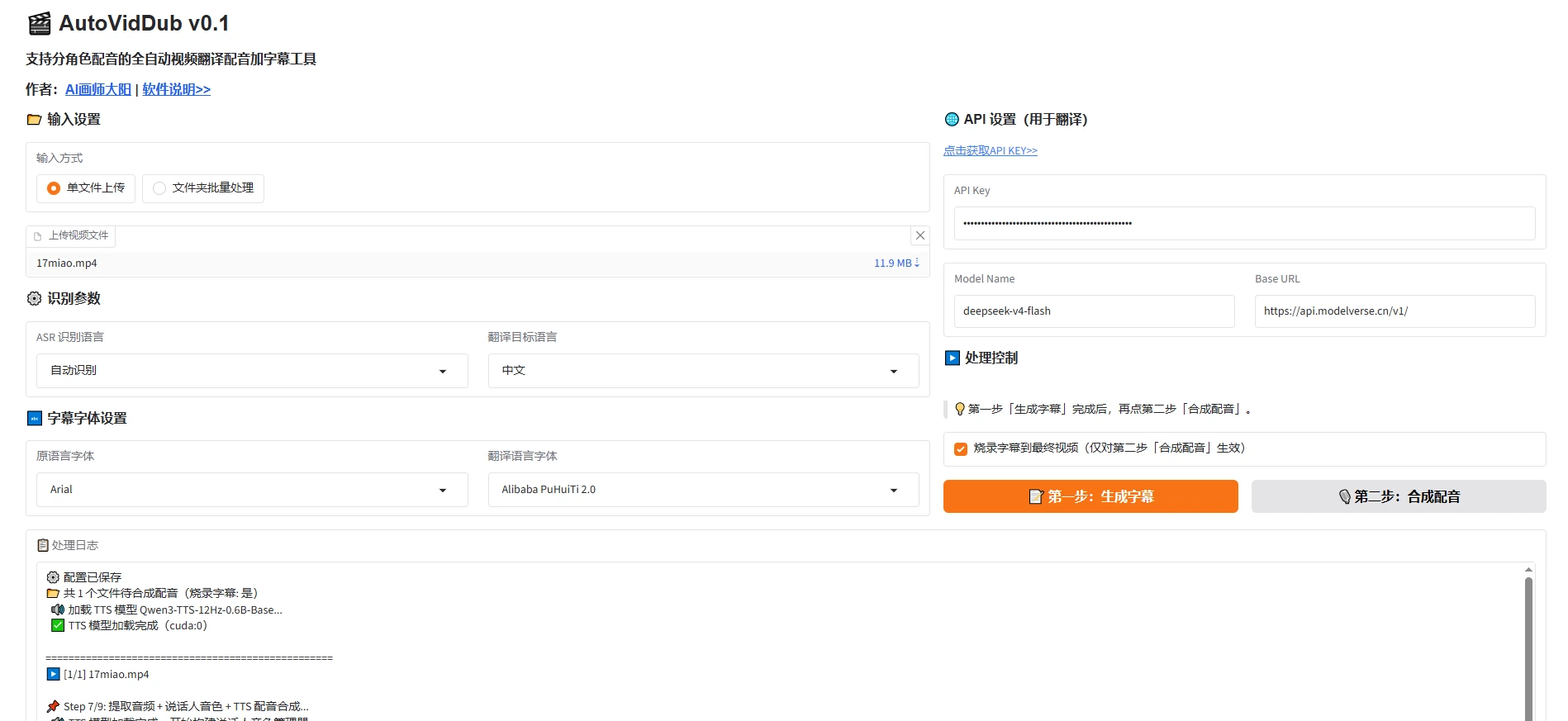
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
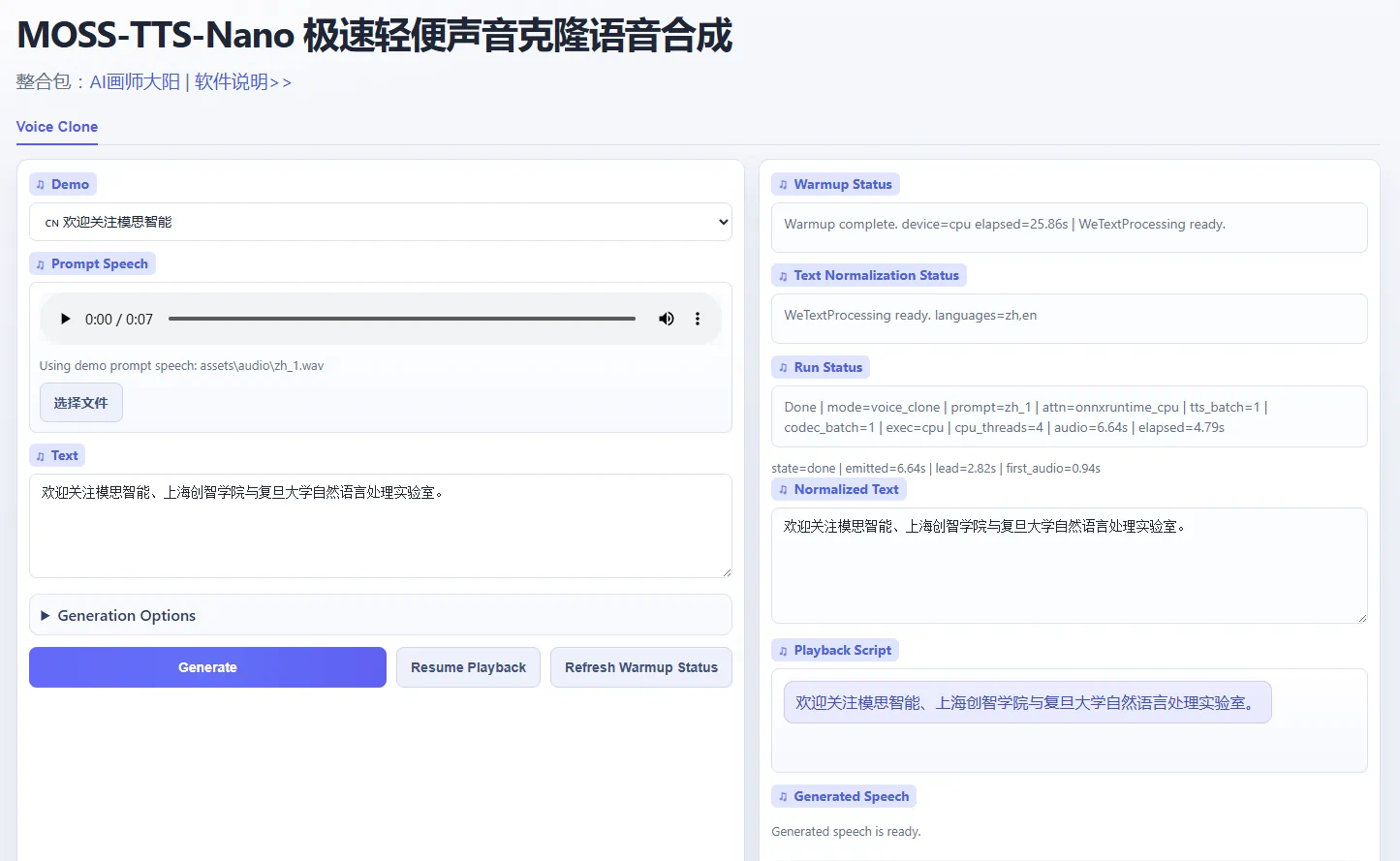
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
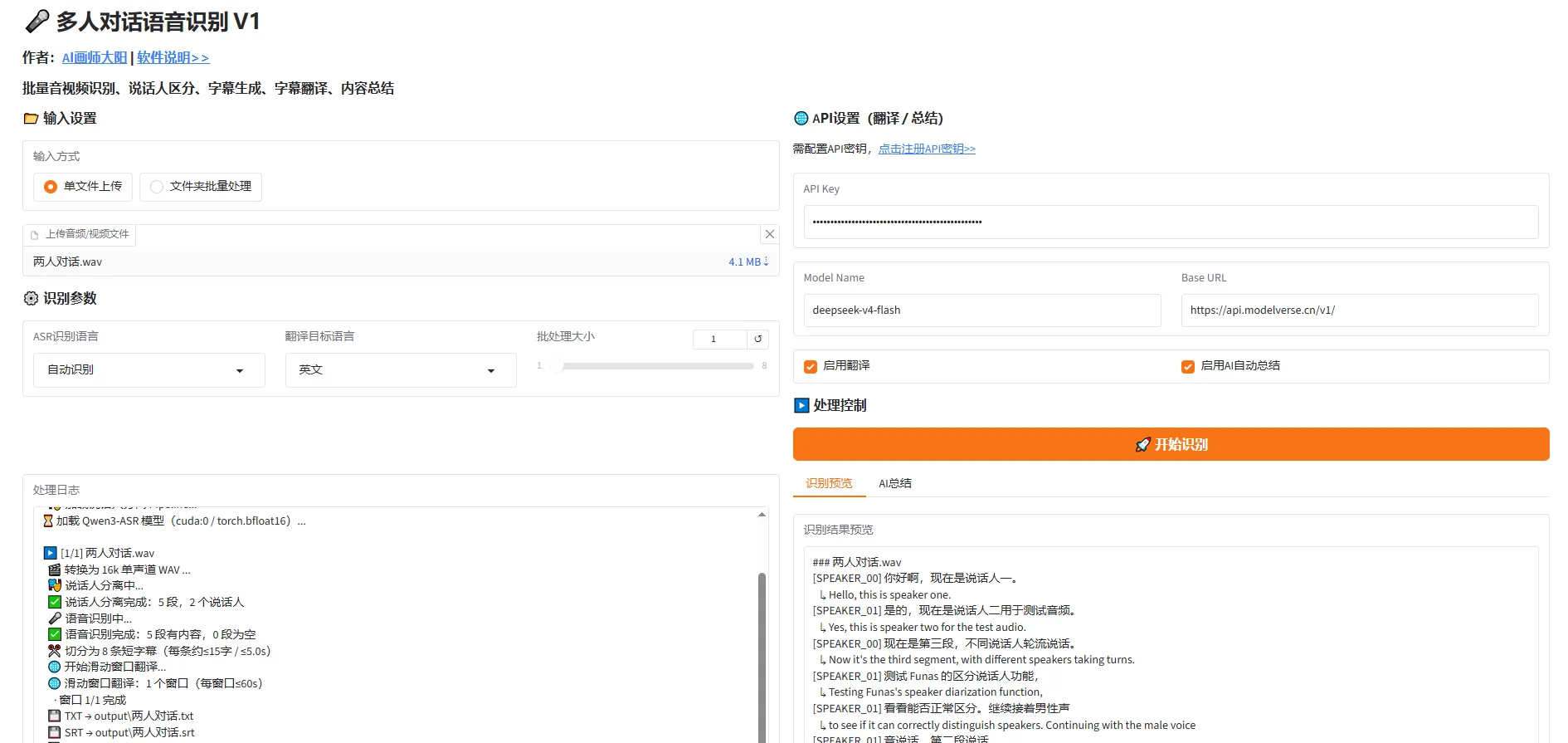
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
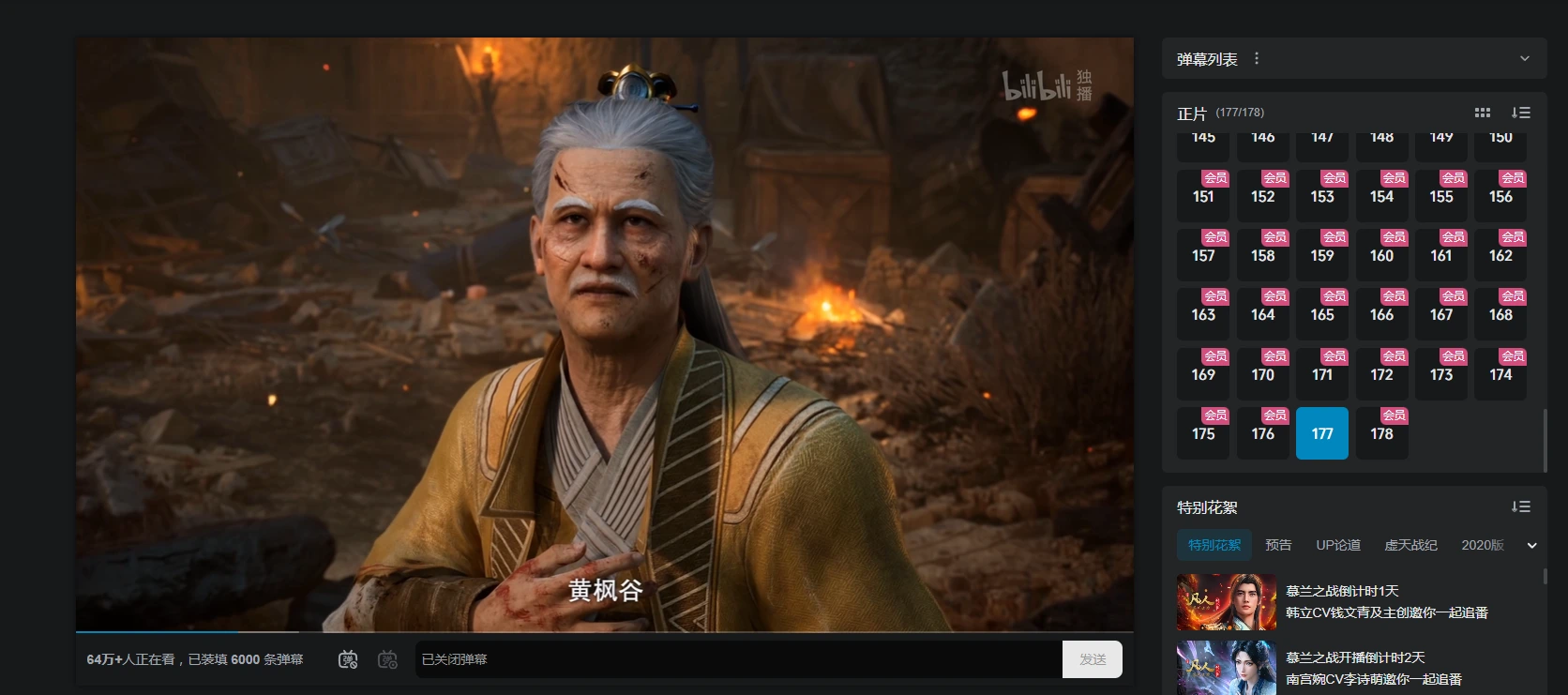
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
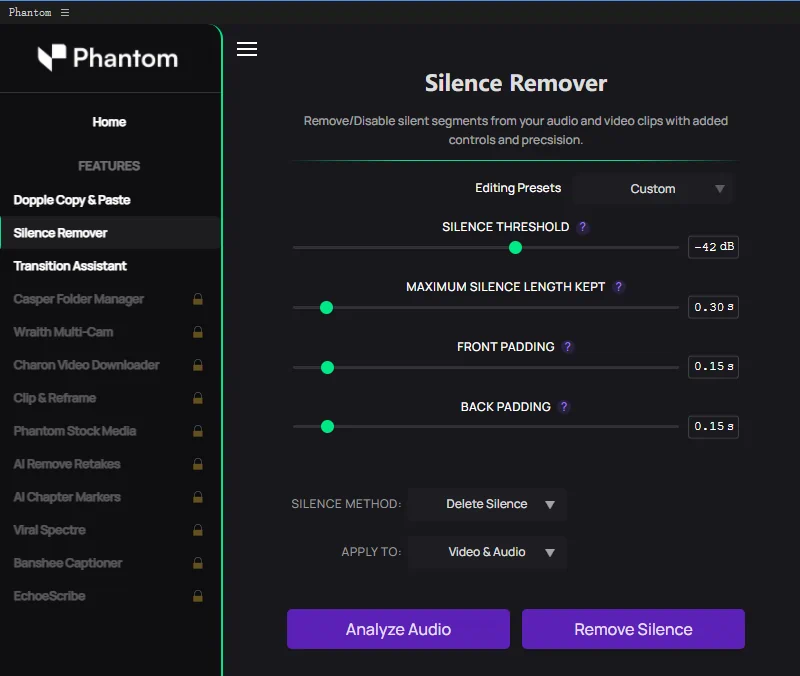
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
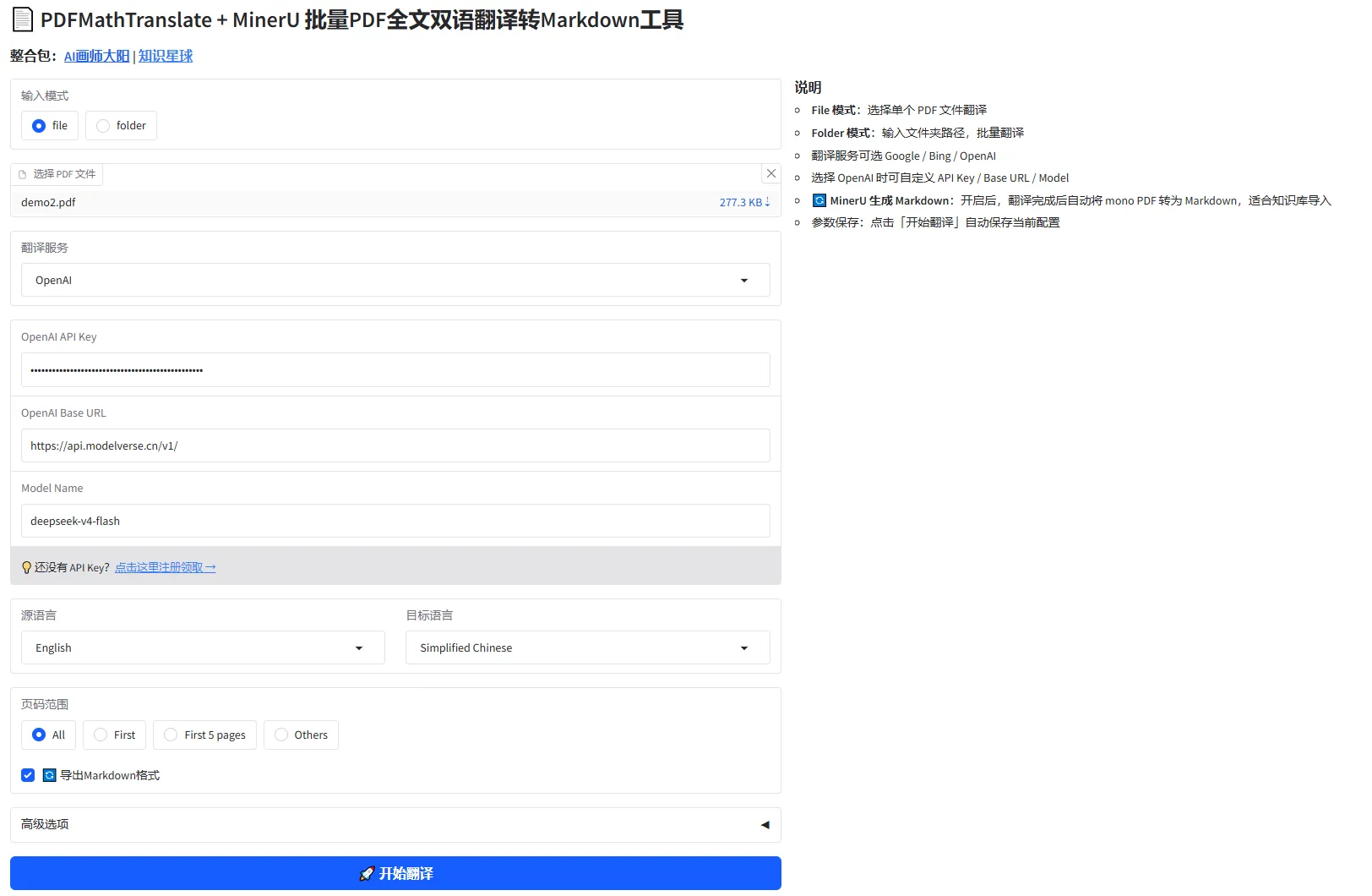
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...