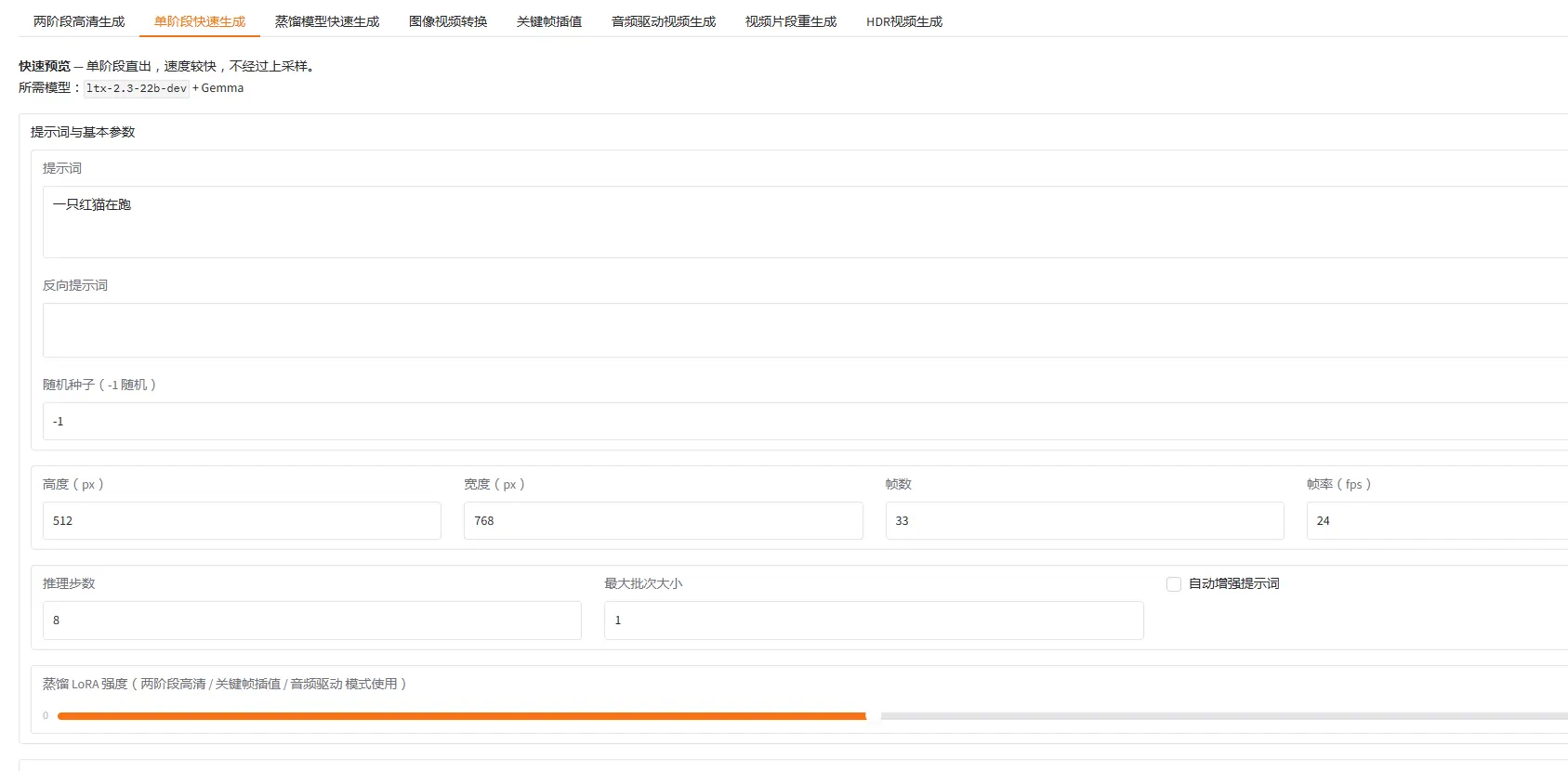
本工作流核心能力是将三张不同角度、内容的参考图,通过 AI 理解融合,生成一张新的图像,新图像内容根据描述词指令生成。工作流集成了阿里巴巴的 Qwen2.5-VL 多模态大模型(图像编辑版本)与 SeedVR2 超分辨率放大模型,实现了「理解 → 生成 → 放大」的完整闭环。
| 工作流类型 | 多参考图合成 + AI 超分辨率放大 |
| 核心模型 | Qwen Image Edit 2511 (fp8) + SeedVR2 3B (Q8) |
| LoRA 加速 | Qwen-Image-Edit Lightning 4步推理版 |
| 输出分辨率 | 生成 720×1280,SeedVR2 放大至 1080p+ |
| 适用场景 | 服装展示、虚拟试衣、人物形象合成、AI 写真 |
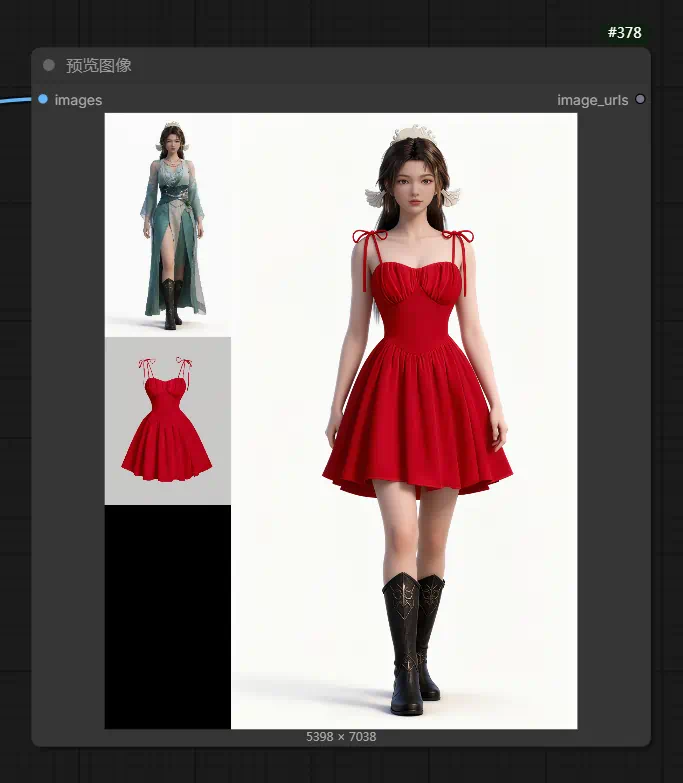
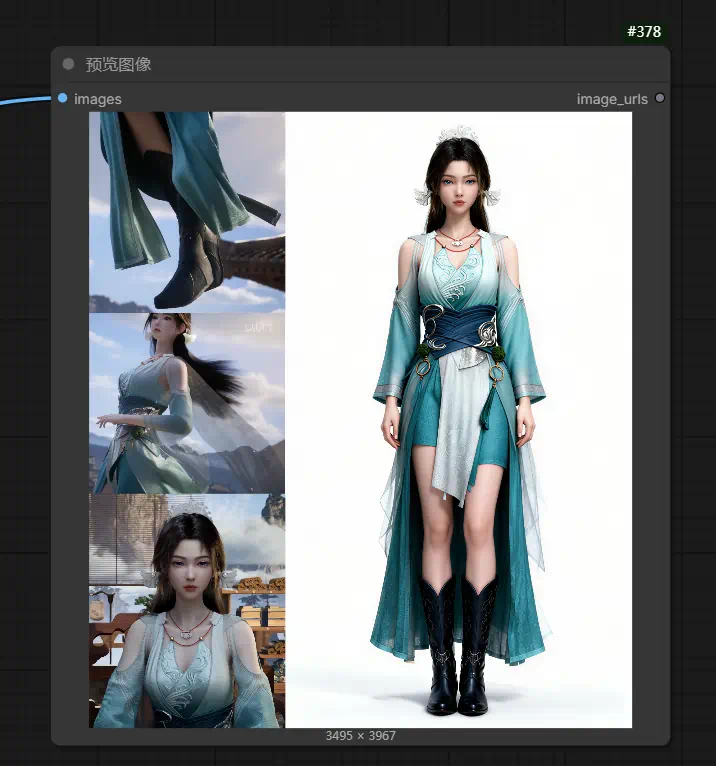
工作流节点结构
整体数据流
工作流从左到右分为四个功能区,各区域之间通过数据连线传递信息:
| 区域 | 颜色标记 | 主要节点 | 职责 |
| 设置区(左侧) | 蓝色边框 | 3×LoadImage、CR Text、EmptyLatentImage | 上传参考图、填写提示词、设定画布尺寸 |
| 主流程区(中) | 蓝色边框 | CLIPLoader、UNETLoader、LoRA、KSampler、VAEDecode | 模型加载、文本编码、扩散采样、解码输出 |
| 放大区(右侧) | 紫色边框 | SeedVR2LoadDiTModel、SeedVR2LoadVAEModel、SeedVR2VideoUpscaler | AI 超分辨率放大至高清 |
| 预览区 | 自动 | ImageConcatMulti、ImageConcanate、SaveImage、PreviewImage | 参考图拼合展示、保存最终结果 |
核心节点说明
① 图像加载节点(LoadImage × 3)
工作流预设了三个图像加载节点,对应三个不同部位或角度的参考图。每张图同时连接到两处:一路送入文本编码器(作为视觉参考),另一路送入图像拼接节点(用于预览对比)。
② 文本与图像联合编码(TextEncodeQwenImageEditPlus)
这是工作流的核心节点,基于 Qwen2.5-VL 多模态模型,能够同时理解文字提示词和三张参考图的视觉内容。它将「语言描述 + 图像特征」融合编码为扩散模型可消费的 Conditioning 向量。
| 重要 | 该节点硬编码只支持 image1 / image2 / image3 共三个图像输入,无法直接扩展。如需5图参考,须将多余的图先用 ImageConcatMulti 横向拼合后再输入 image3 插槽。 |
③ 参考潜空间方法(FluxKontextMultiReferenceLatentMethod × 2)
正向 Conditioning 经此节点处理后进入采样器正面输入,负向(ConditioningZeroOut 清零后)作为负面输入。method 参数统一设为 index_timestep_zero,是当前兼容性最佳的选项。
④ KSampler(采样器)
配合 Lightning LoRA 使用,当前配置为:steps=8、cfg=1、采样器=euler、调度器=simple、denoise=1.0。这是 4步闪电推理的标准配置,在速度与质量之间取得平衡。
⑤ SeedVR2 超分辨率放大链
VAEDecode 解码出的图像(约 720×1280)会直接进入 SeedVR2VideoUpscaler,经 DiT 模型与 VAE 模型协同放大至 1080p 甚至更高分辨率,细节恢复能力显著优于传统插值算法。
使用方法
Step 1 上传参考图
- 点击「设置区」中的三个 LoadImage 节点,分别上传三张参考图
- 三张图的分辨率不需要一致,节点会自动处理尺寸差异
Step 2 填写提示词
在 CR Text 节点中填写生成描述,需明确说明每张图对应的内容,以及期望的输出形式。参考格式:
根据图1中的腿部图、图2中的侧身图、图3中的上半身正面图,生成人物全身正面纯色背景图片
- 提示词支持中文,Qwen 模型对中文理解表现优秀
- 可以加入风格描述,如「写实摄影风格」「干净白色背景」「全身正面站立」
- 不需要写负面提示词,负面端已由 ConditioningZeroOut 清零处理
Step 3 确认画布尺寸
EmptyLatentImage 节点默认设为 720×1280(竖向人物图),一般无需修改。如需横图可改为 1280×720,方形可改为 1024×1024。
Step 4 执行生成
点击 ComfyUI 界面右下角的「Queue Prompt」按钮开始运行。生成过程分为两个阶段:
- 阶段一:KSampler 采样(约10~30秒,取决于显存和步数)
- 阶段二:SeedVR2 超分放大(约20~60秒,会占用较多 VRAM)
Step 5 查看结果
右侧 SaveImage 节点会将主生成图保存到 ComfyUI 的 output 目录,PreviewImage 节点展示「参考图拼合 + 超分结果」对比预览。
关键参数配置详解
KSampler 参数
| seed | 随机种子,设为 randomize 每次生成不同结果;固定数值可复现 |
| steps | 推理步数,默认 8,配合 Lightning LoRA 无需增加,增加反而可能降质 |
| cfg | 提示词引导强度,当前为 1,Lightning 模式下不建议超过 1.5 |
| sampler_name | euler,Lightning LoRA 的推荐采样器 |
| scheduler | simple,与 euler 配套使用效果最佳 |
| denoise | 去噪强度,1.0 = 完全重绘,从空白 Latent 生成 |
SeedVR2 放大参数
| resolution | 目标放大分辨率(长边),默认 1080,可设 1440/2160 |
| max_resolution | 最大分辨率限制,0 = 不限制 |
| batch_size | 单次处理帧数,图片场景设为 1 即可 |
| color_correction | 色彩校正模式,lab 效果最自然,推荐保持 |
| offload_device | 模型卸载设备,必须设为 cpu(不可为 none,否则崩溃) |
| cache_model | 是否缓存 DiT 模型到内存,True = 第二次运行更快 |
| 注意 | SeedVR2 的 offload_device 参数必须设为「cpu」,不能留空或设为「none」。设为 none 时程序会直接报错崩溃:”Model caching requires offload_device to be set.” |
使用注意事项
显存管理
- 建议英伟达显卡显存8G以上
- 如显存不足导致 OOM,可尝试将 SeedVR2 的 blocks_to_swap 从 0 适当增大(如 8~16),将部分 DiT 计算块卸载至 CPU
- SeedVR2 的 cache_model 设为 True 可加速第二次运行,但会多占约 2~4GB 系统内存
参考图质量要求
- 分辨率建议不低于 512×512,过小的图会导致细节丢失
- 三张图尽量来自同一人物,差异过大(体型、肤色明显不同)会导致合成混乱
- 避免使用高度压缩、有明显噪点的图片,会影响 Qwen 的图像理解质量
- 图片中的人物尽量为独立个体,不要有大量其他人物干扰
提示词技巧
- 明确描述每张图的内容与对应关系(图1是…,图2是…,图3是…)
- 指定输出风格:「写实摄影」「白色纯色背景」「全身正面站立」「高清」等
- 如果生成的人物比例不对,可在提示词中加入「保持正常人体比例」「全身比例正确」
- 不建议在提示词中描述背景细节,纯色背景场景下越简单越好
常见问题排查
| 问题现象 | 解决方案 |
| SeedVR2 报 offload_device 错误 | 将 SeedVR2LoadDiTModel 的 offload_device 从 none 改为 cpu |
| invalid prompt: class_type None | 工作流包含未注册节点,用文本编辑器删除 JSON 中对应 id 的节点对象后重新加载 |
| Fast Groups 节点缺失 | 通过 ComfyUI-Manager 安装 rgthree-comfy 插件并重启 |
| 生成图人物比例失真 | 在提示词中增加全身比例、站姿描述;检查 EmptyLatentImage 的宽高比 |
| SeedVR2 显存溢出(OOM) | 增大 blocks_to_swap 参数(建议从 8 开始尝试);或将 max_resolution 降低 |
| 生成速度很慢 | 确认 LoRA 已正确加载(steps 应在 8 左右即完成);检查是否有其他进程占用 GPU |
| 三张图合成效果差 | 参考图之间差异过大,尝试换用同一套装的不同角度图;优化提示词描述 |
优化建议
批量生成
将 EmptyLatentImage 的 batch_size 改为 2~4 可同时生成多张,结合随机种子(randomize)可快速筛选最佳结果。但每增加一张 batch 会相应增加显存需求和生成时间。
二次细化
对 SaveImage 输出的结果不满意时,可将其重新载入 LoadImage,使用 img2img 模式(KSampler 的 denoise 调低至 0.5~0.7)进行局部细化,保留整体构图同时优化细节。
SeedVR2 放大参数调优
- color_correction=lab 效果最自然,如遇肤色偏差可尝试切换为 none
- input_noise_scale 和 latent_noise_scale 适当调高(0.02~0.05)可让细节更丰富,但过高会引入噪点
- resolution 设为 2160 可获得更高清结果,但耗时和显存翻倍,需权衡
本工作流将多模态理解模型与扩散生成模型深度结合,在服装展示、AI 写真、虚拟形象合成等场景下具有较强实用价值。合理配置显存参数、提供高质量参考图、写清晰的提示词,是获得理想结果的三个关键要素。
comfyui三参考图生图工作流下载链接
https://pan.quark.cn/s/17f7fd198685
模型文件下载链接:
https://pan.quark.cn/s/186b6dd01260
相关推荐



最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
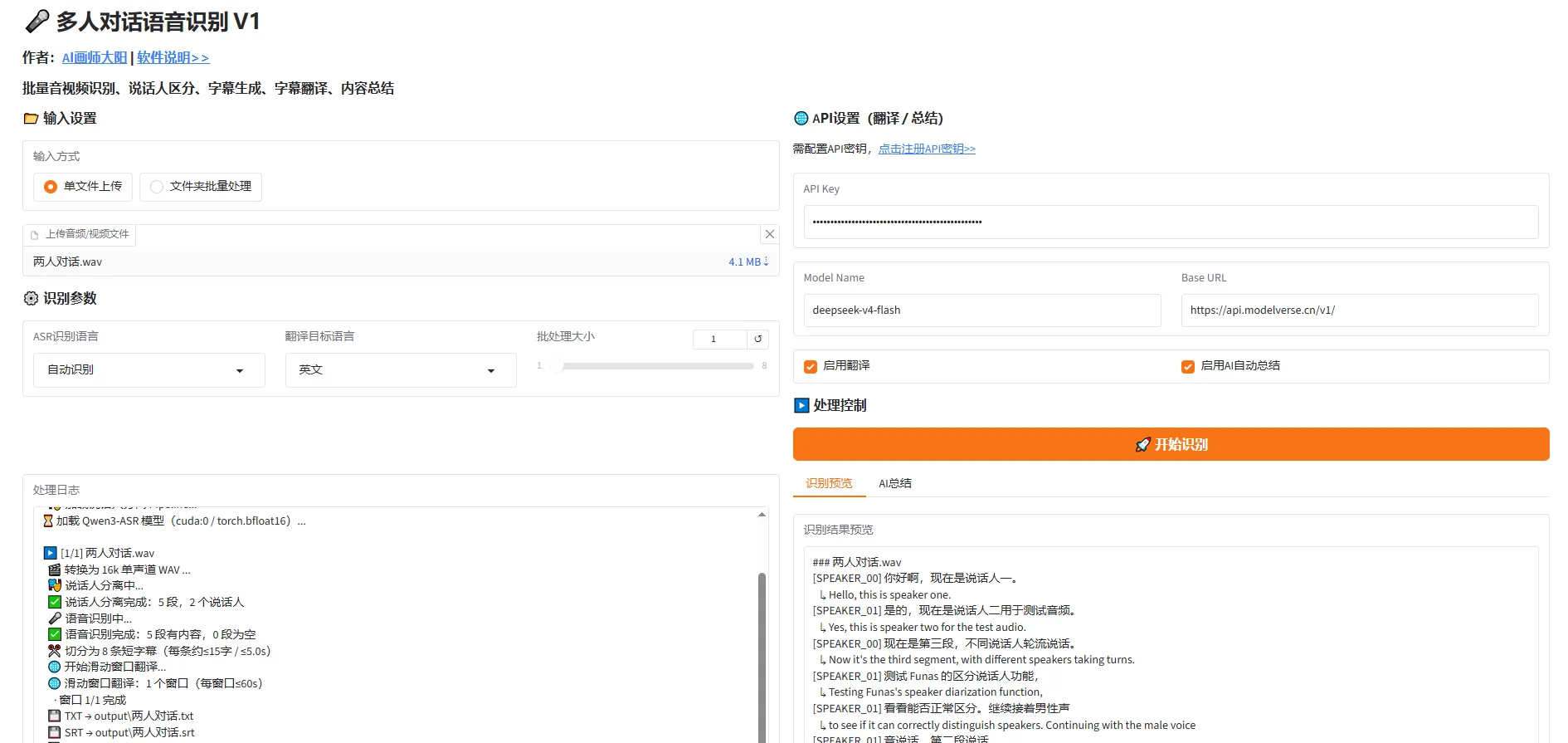
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
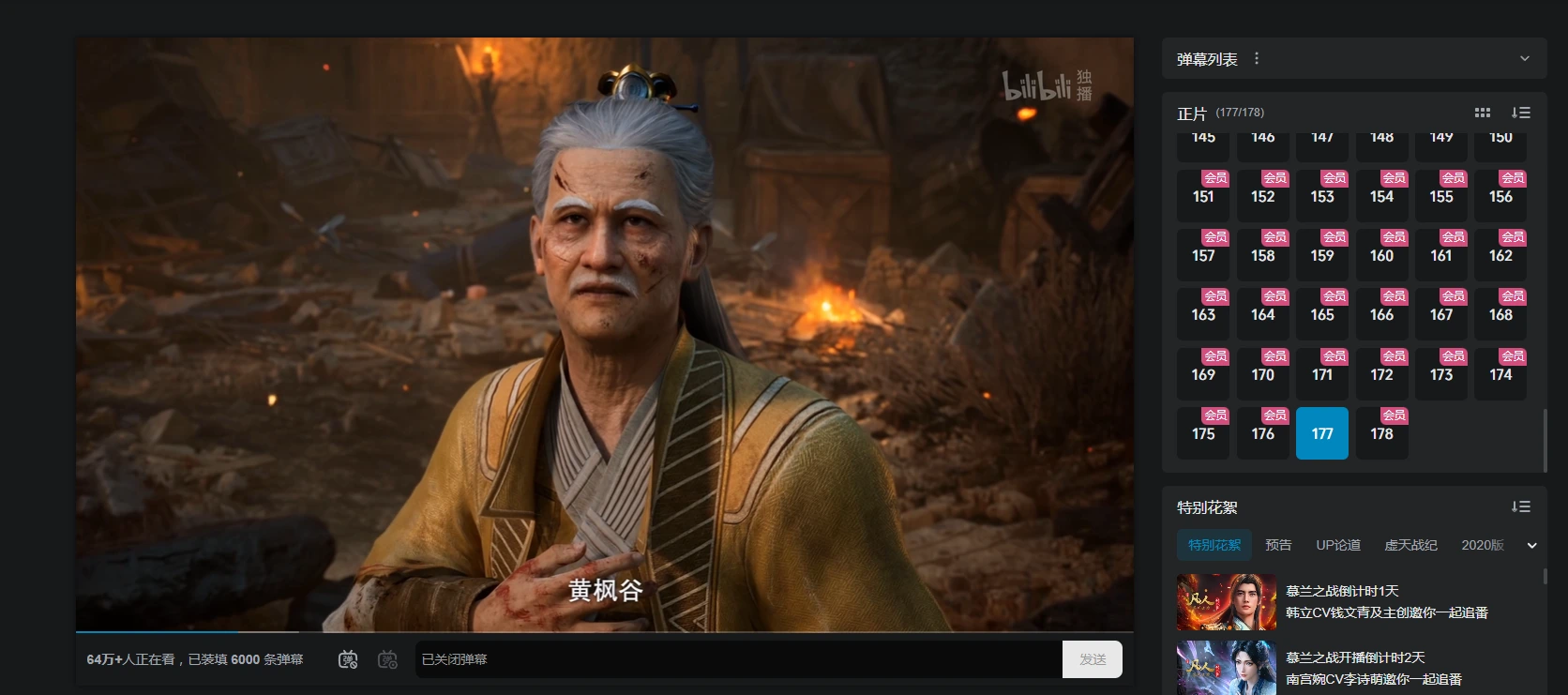
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
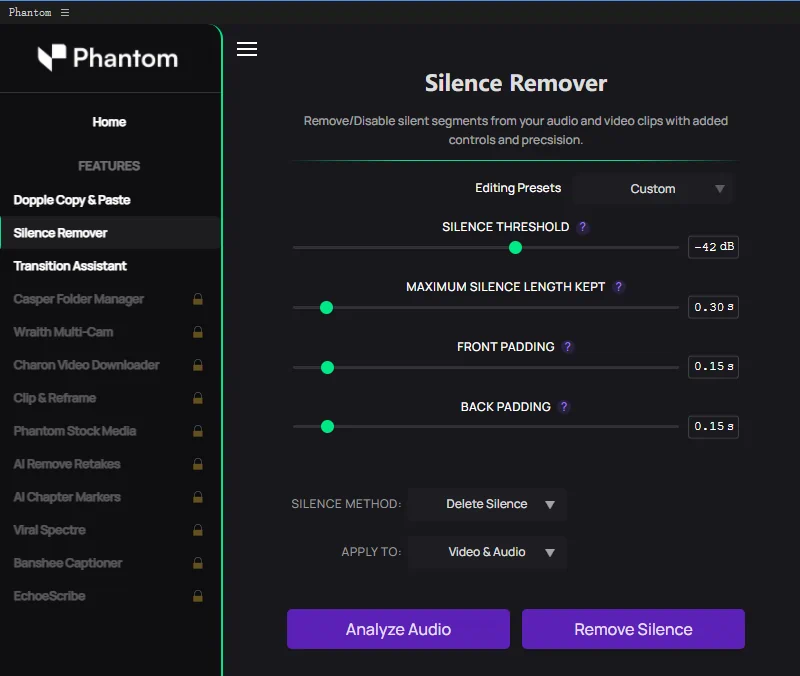
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
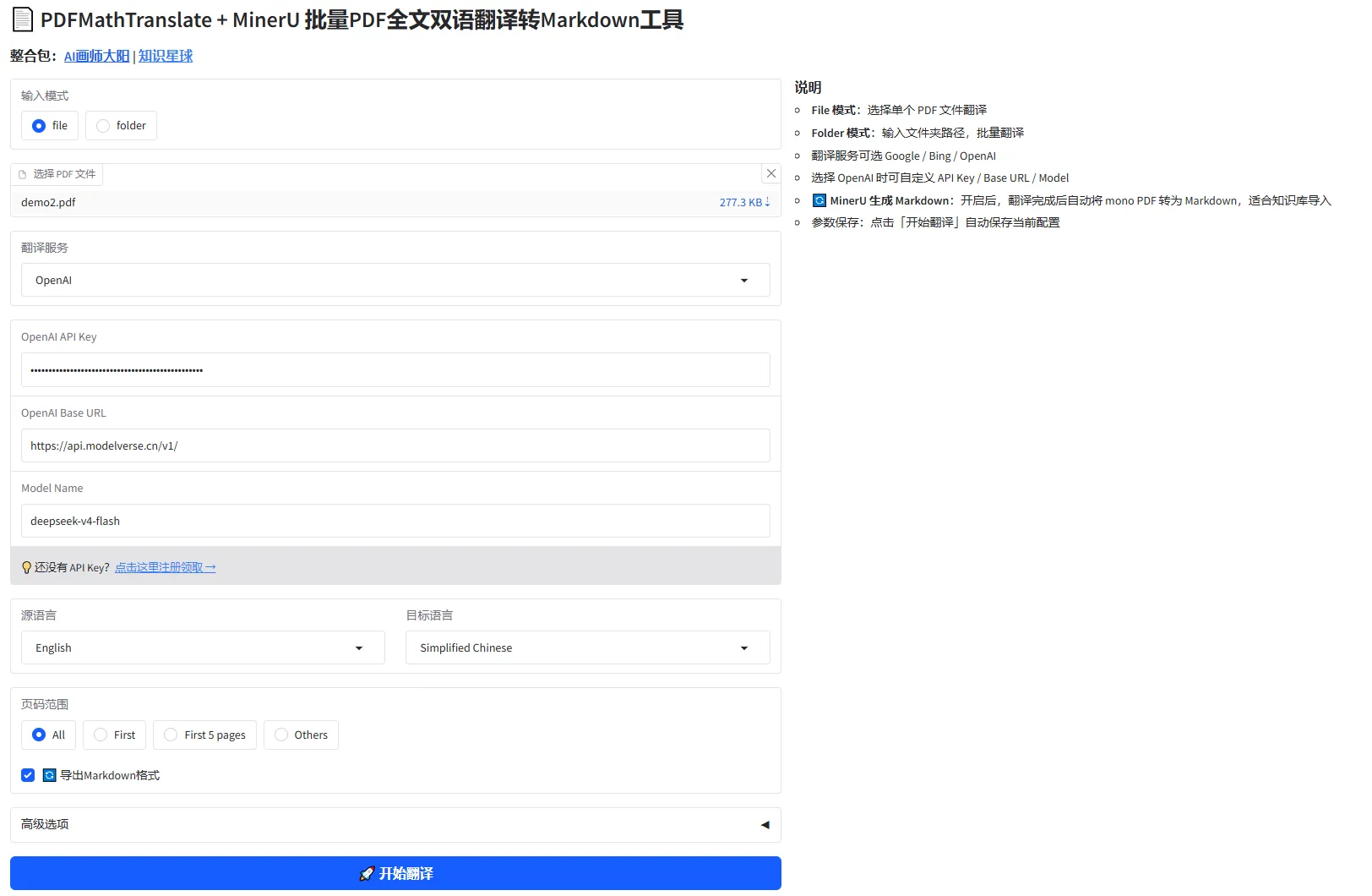
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...