YuE:开放的全曲音乐生成基础模型,可免费一键生成完整歌曲,AI作曲,AI演唱,是一个高质量的AI音乐生成软件。我制作了最新的面安装一键启动整合包。
YuE介绍
YuE 是一系列突破性的开源基础模型,专为音乐生成而设计,尤其适用于将歌词转化为完整的歌曲(lyrics2song)。它可以生成一首时长数分钟的完整歌曲,包含朗朗上口的声乐和伴奏。YuE 能够模拟多种音乐类型/语言/演唱技巧。
YuE项目核心功能
- 歌词到歌曲的全流程生成
- 输入纯文本歌词,即可生成包含人声演唱和多轨伴奏的完整音乐作品。
- 支持多语言歌词:英语、中文、日语、韩语。
- 高度自定义的音乐风格
- 用户可指定流派(流行、金属、电子、古典等)、乐器组合、情绪基调(欢快/忧郁)、人声音色(性别/音色)。
- 支持音频提示引导:上传参考音频片段,模型可模仿其风格生成新作品。
应用场景
- 音乐创作:快速生成demo,辅助作曲者探索编曲方向。
- 影视游戏配乐:根据场景需求定制背景音乐(如战斗金属乐或浪漫钢琴曲)。
- 教育与研究:
- 多语言音乐生成机制研究(如中英文混填歌词)。
- 跨模态艺术实验:联动图像生成模型创作视听结合作品。
YuE一键启动整合包使用说明
首先将网盘内的软件压缩包下载到本地电脑上并解压,双击【启动软件.exe】
我已经预先下载了可生成中文歌曲的模型,如果你想生成英语或日韩歌曲的话,可以运行下载模型按钮,下载其它语言模型。
软件启动成功后会自动打开webui界面。
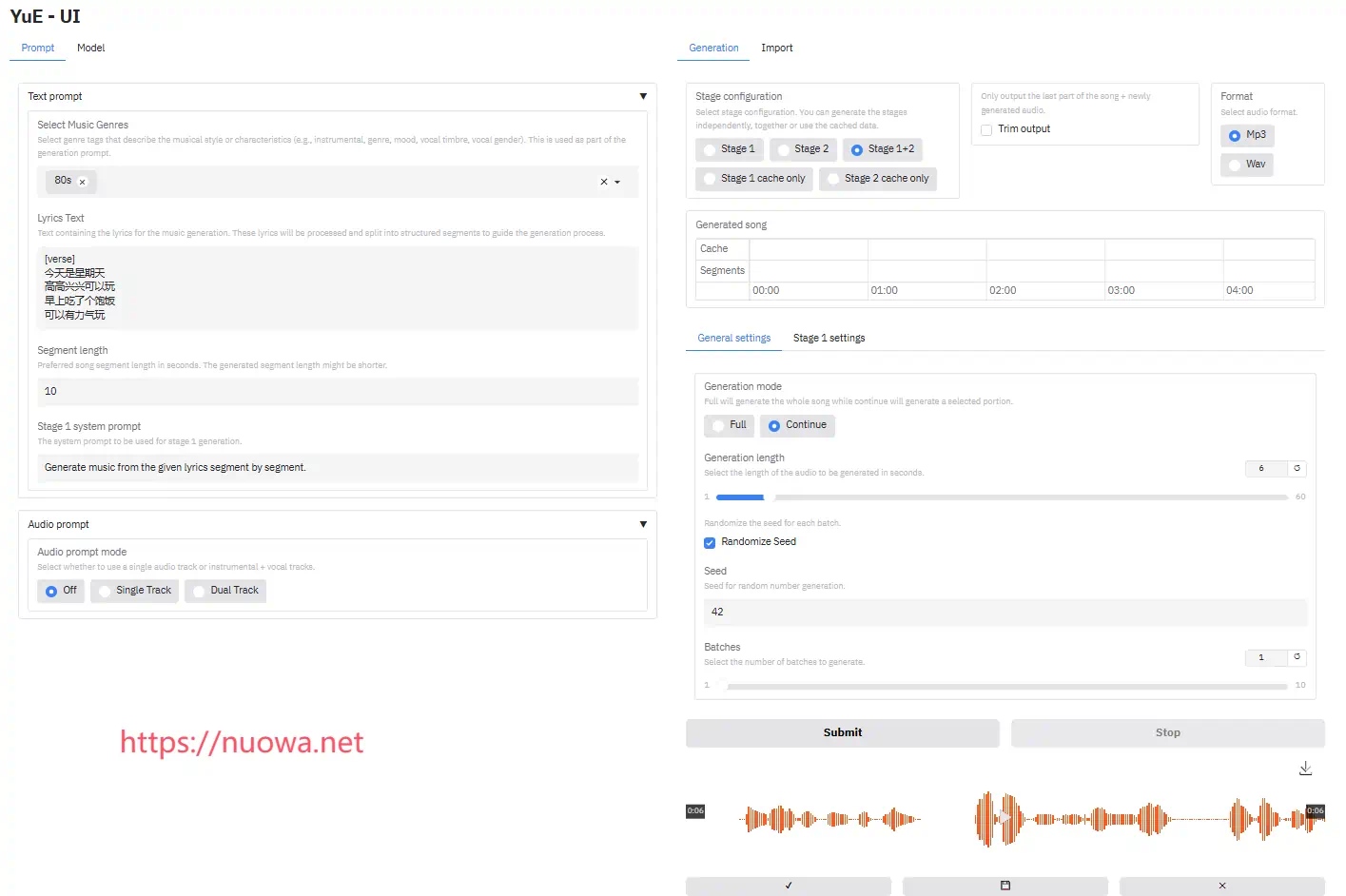
首先在【Model】-【Stage1 Model】里选择你想要使用的模型
【Stage 1 Cache Size】可根据显卡配置设置缓存大小。第一阶段生成过程中,如果爆显存了,就调小这个值,如果显存还有剩余就增大这个值。
其它参数保持默认设置就可以,感兴趣的可以自行研究测试。
【Prompt】
【Select Music Genres】即音乐类型,尝试使用流派标签尽可能准确地描述音乐。稳定的提示通常包含 5 个部分:流派、乐器、情绪、性别和音色。
列表选项提供 200 个常用标签,当然您也可以尝试创建自己的标签!标签的顺序可以灵活调整。
您还可以在生成歌曲的不同部分时尝试添加或删除标签,以改变最终效果。
【Lyrics Text】歌曲歌词。歌词必须采用命名分段结构。每个段落需以方括号[]包裹的名称开头。
歌词书写形式参考
[verse]
Staring at the sunset, colors paint the sky
Thoughts of you keep swirling, can’t deny
I know I let you down, I made mistakes
But I’m here to mend the heart I didn’t break
[chorus]
Every road you take, I’ll be one step behind
Every dream you chase, I’m reaching for the light
You can’t fight this feeling now
I won’t back down
You know you can’t deny it now
I won’t back down
[verse]
They might say I’m foolish, chasing after you
But they don’t feel this love the way we do
My heart beats only for you, can’t you see?
I won’t let you slip away from me
[chorus]
Every road you take, I’ll be one step behind
Every dream you chase, I’m reaching for the light
You can’t fight this feeling now
I won’t back down
You know you can’t deny it now
I won’t back down
[bridge]
No, I won’t back down, won’t turn around
Until you’re back where you belong
I’ll cross the oceans wide, stand by your side
Together we are strong
[outro]
Every road you take, I’ll be one step behind
Every dream you chase, love’s the tie that binds
You can’t fight this feeling now
I won’t back down
注意每段歌词必须要带有[verse],[chorus]这样的关键词
操作须知
- 无需一次性提供完整歌词,可逐步添加新段落,核心原则是保持内容持续向前推进。
- 切记不要删除已有段落,否则会导致歌词与已生成歌曲不同步。
- 可随时修改歌词内容或重命名段落(不影响已生成部分的结构)。
【Stage 1 system prompt】生成歌曲要求描述
【Audio prompt mode】是否使用参考音乐,如果需要的话可上传音频文件
【Generated song】可以将合成的多个音乐片段添加到一起合成一个完整的音乐。
【Generation length】生成音乐时长
【Batches】批量生成音乐数
设置完成后点击按钮【Submit】按钮开始合成
大部分设置保持默认就可以,剩下参数有感兴趣的可以自行测试一下。
视频教程及效果演示:https://nuowa.net/1974
注意事项
建议英伟达显卡显存不低于8G
支持英伟达50系列显卡
只支持windows10或11系统
软件运行路径中不要有非英文字符和空格,待处理素材同样注意
AI全自动音乐生成器YuE整合包下载链接
https://pan.quark.cn/s/3fdc2603118b
https://pan.xunlei.com/s/VOSRjbimEMGnyO9mDM6hCuOeA1?pwd=qr7k#
AI音乐创作软件YuE本地电脑安装部署教程
相关推荐
 AI歌曲创作软件DiffRhythm一键启动包,自定义风格AI谱曲演唱
AI歌曲创作软件DiffRhythm一键启动包,自定义风格AI谱曲演唱- 极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
- 最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
- AI实时语音聊天对话系统,外语口语陪练/虚拟好友实时语音交流
- 多人对话声音克隆语音合成工具Chatterbox TTS免安装版,AI实时文字转语音
- AI实时变声器Voice Changer2.1.4 CUDA版下载,高质量RVC变声软件
- 阿里Qwen3-TTS高质量声音克隆语音合成系统,AI视频配音多人对话生成工具
- 多人对话有声书制作软件VoxCPM Windows版整合包,高质量声音克隆语音合成工具

最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
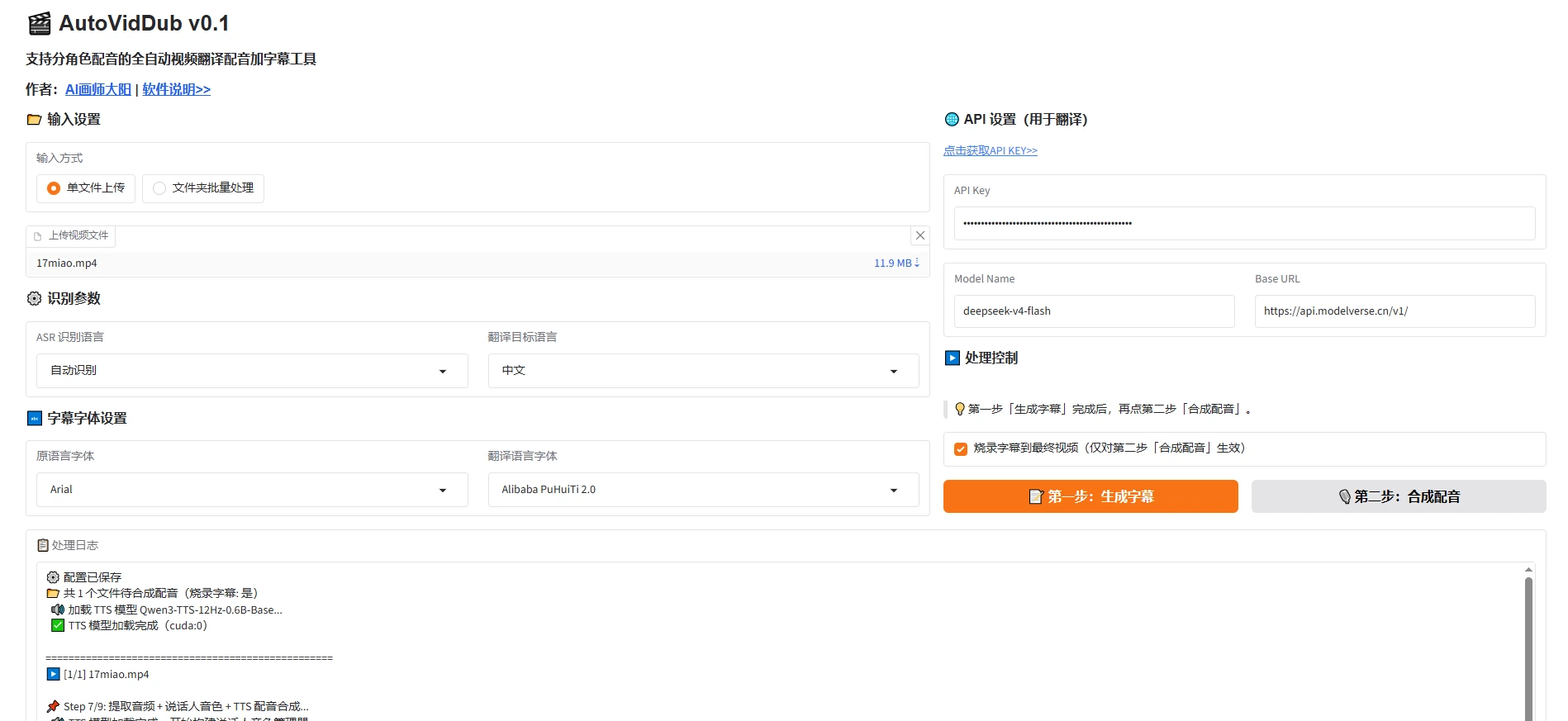
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
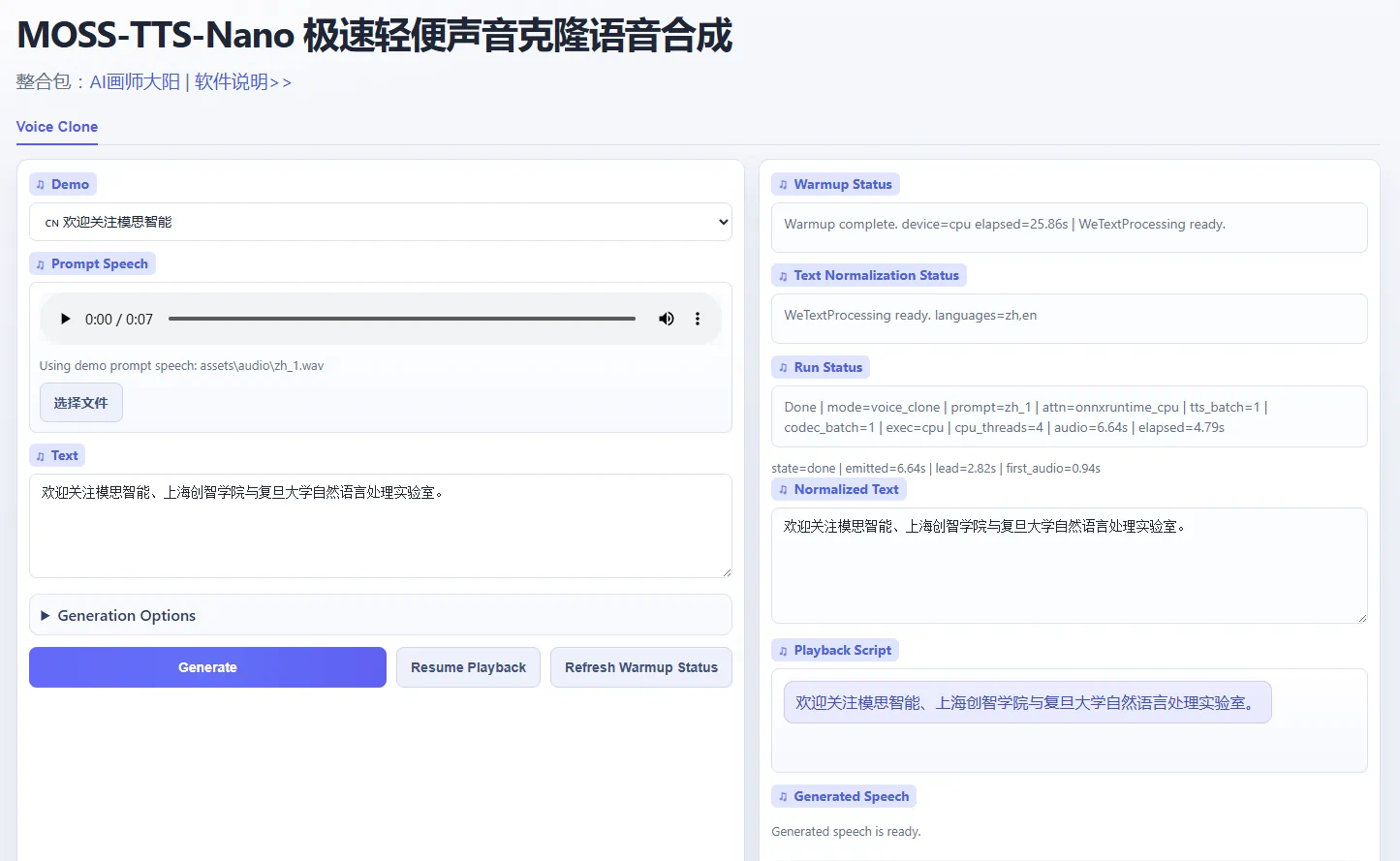
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
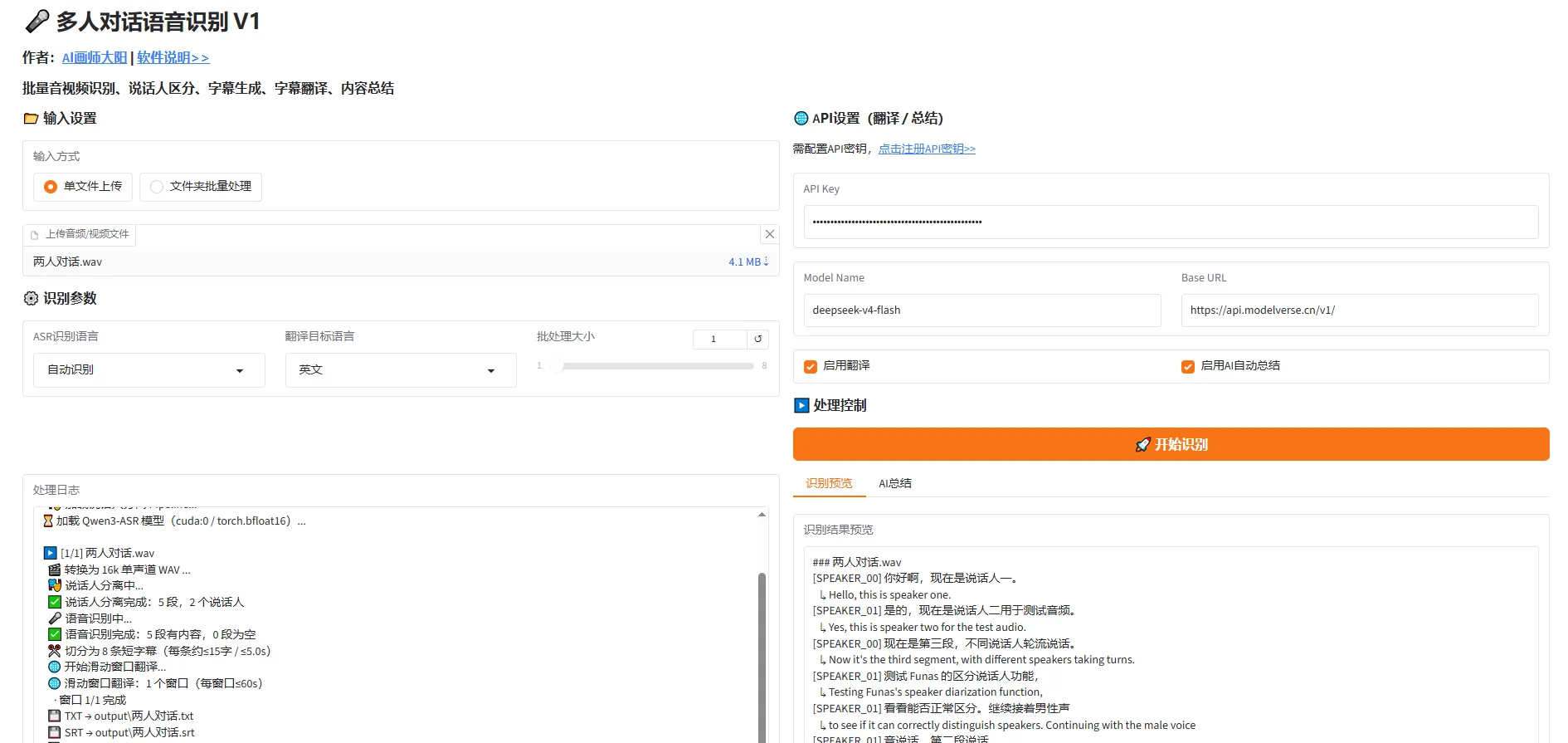
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
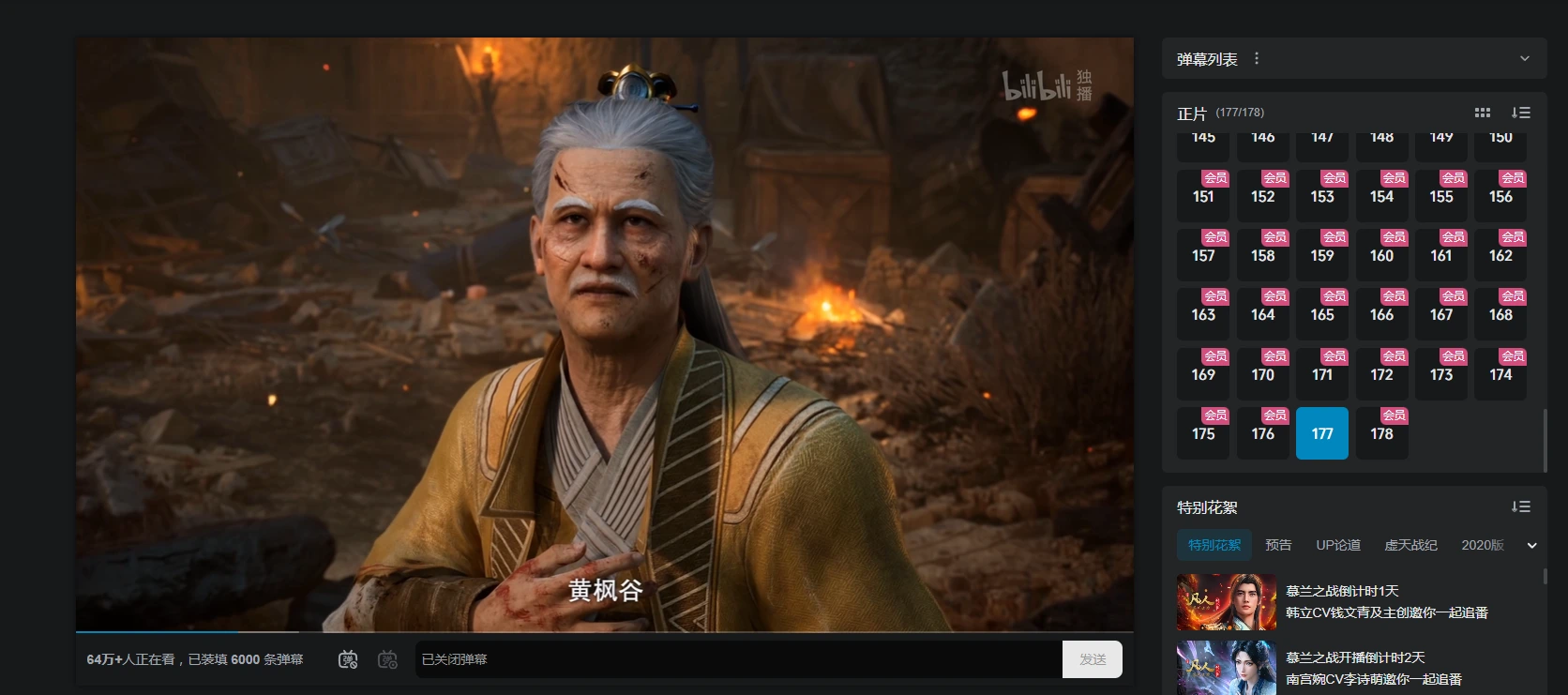
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
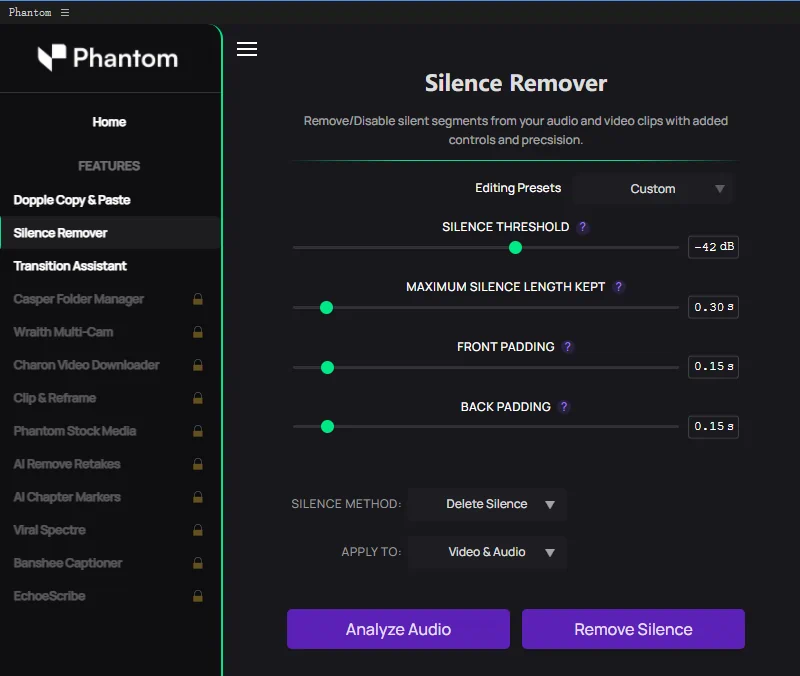
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
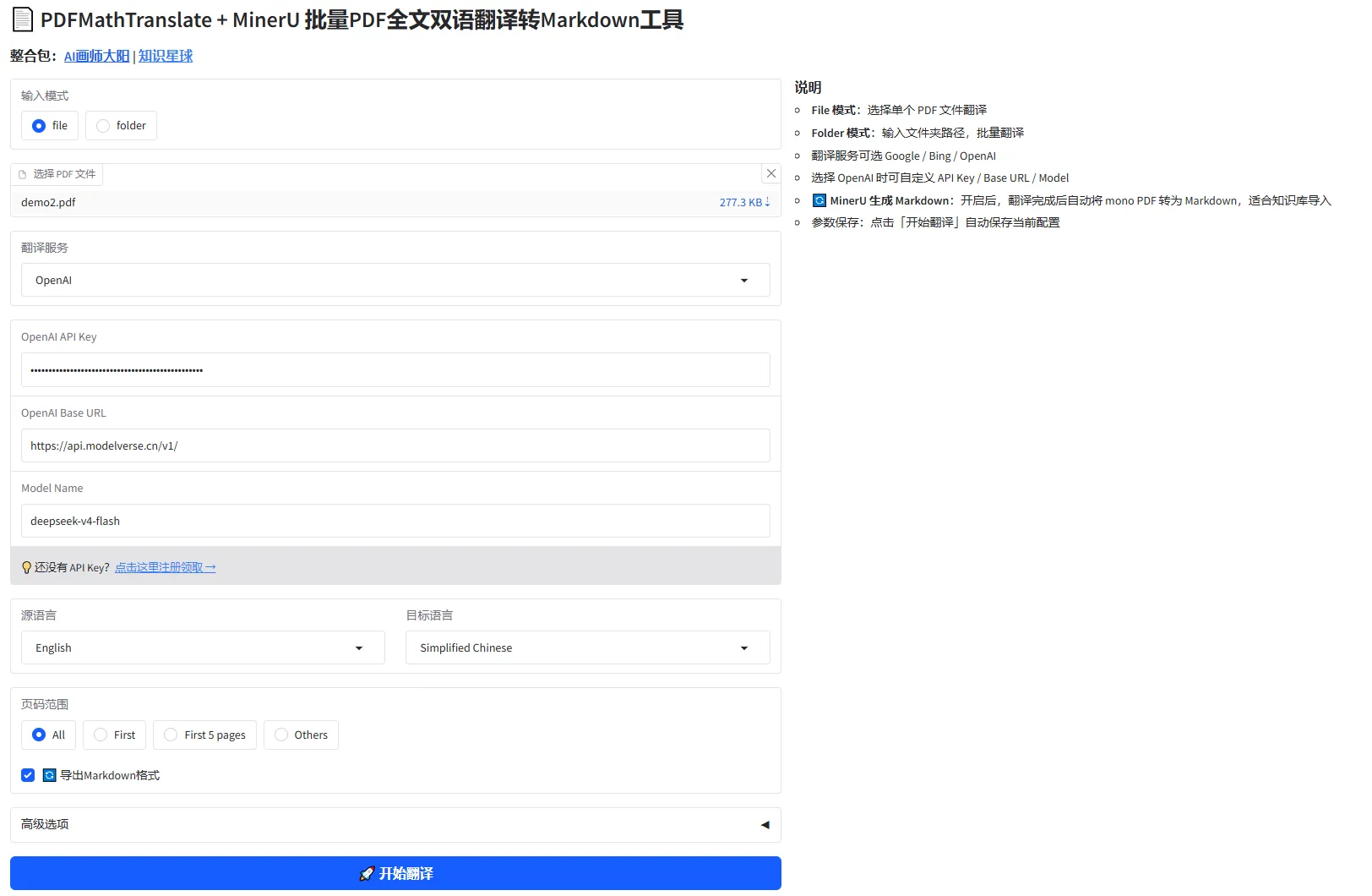
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...