Voice Changer是一款实时 AI 变声工具,允许你通过多种 AI 声音模型(如 RVC 和 Beatrice)实时转换声音。转换延迟更低,是目前社区中最受欢迎的开源实时变声方案之一。
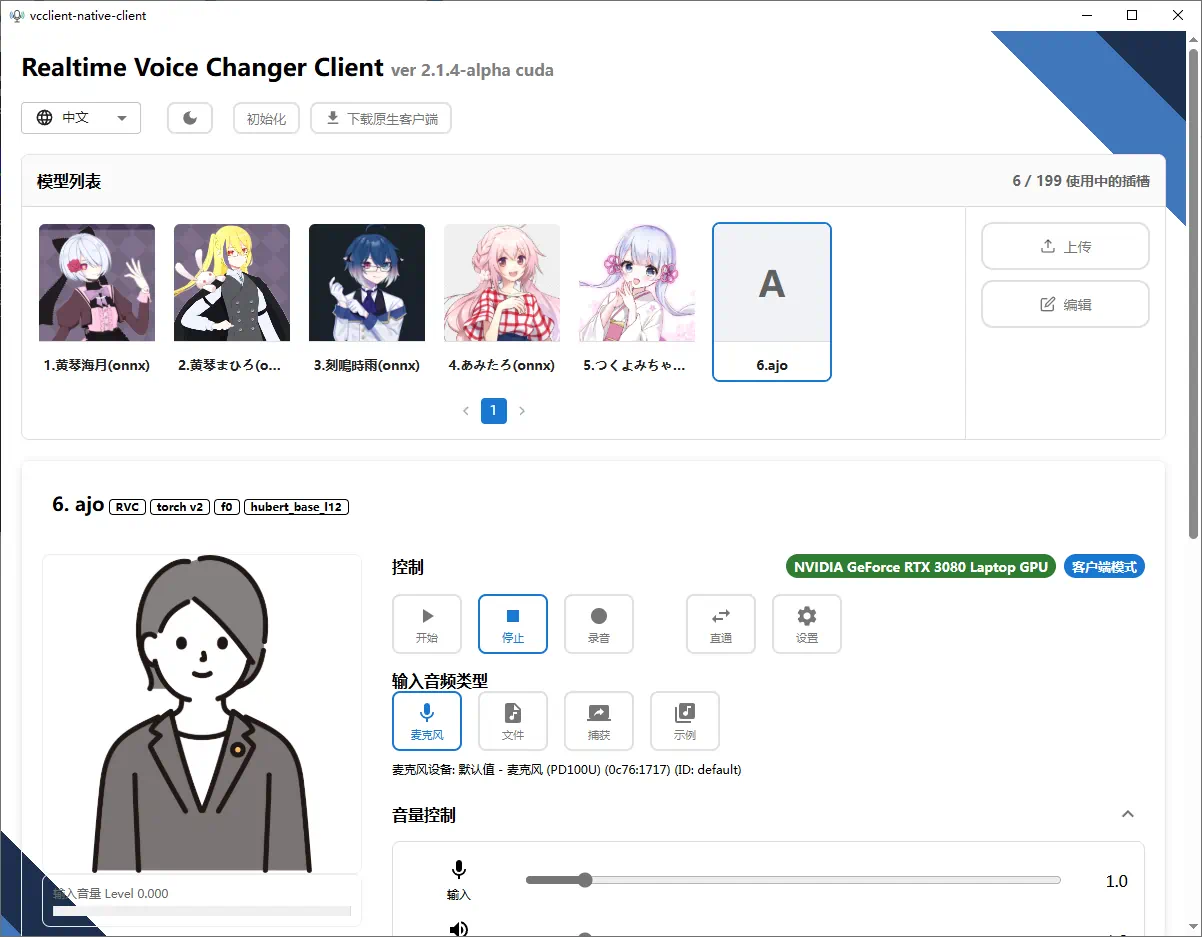
核心特点
1. 实时性
voice-changer能够实时工作,即时改变你的声音,并自动切换声音效果。延迟时间由缓冲区(buf)和处理时间(res)共同决定,可通过调整参数来优化延迟表现。
2. 多 AI 模型支持
支持的主要模型包括:RVC(Windows/Mac 均支持)、Beatrice v1(仅 Windows)、Beatrice v2、其中 RVC(Retrieval-based Voice Conversion,基于检索的语音转换)是目前最主流、效果最佳的模型。
3. 跨平台兼容
支持 Windows、Mac(含 Apple Silicon M1)、Linux 以及 Google Colaboratory。Windows 用户可直接下载可执行文件,Linux 用户需克隆仓库源码运行。
4. GPU 加速
支持多种 GPU 设备,包括 Nvidia、AMD 和 Intel GPU,可提升声音转换的速度和效率。对于 Nvidia 用户可使用 CUDA 版本,AMD/Intel 用户可使用 DirectML 版本(仅支持 ONNX 模型)。
5. 服务端-客户端架构
本应用采用服务端-客户端架构,通过在另一台 PC 上运行变声服务端,可以将变声负载转移到外部,从而将对游戏解说等高负载进程的影响降至最低。
主要功能
模型管理
通过界面加载的角色图像可直观展示状态;右侧的按钮和滑块可控制各种设置。可以对模型进行上传、下载、编辑操作,还支持通过编辑槽位来更换角色形象。
噪音抑制
可以开关噪音消除功能(仅在客户端设备模式下可用),并可通过音量阈值设置,当 RMS 低于设定值时跳过语音转换、返回静音,以减轻系统负担。
模型融合(Merge Lab)
Merge Lab 允许将多个 RVC V2 声音模型(.pth 权重文件)合并为一个全新的混合模型,用于创造独特声音。
ONNX 导出与加速
可将 PyTorch 模型导出为 ONNX 格式,部分测试表明 .onnx 文件在实时语音转换中可能比 .pth 更快。
音高与音速调整
提供音高和速度调整滑块,允许用户精细调整声音,可以使声音更高、更低、更快或更慢,增加多样性和表现力。
男变女调高音调值,一般8-12,女变男调低音调值
典型应用场景
可用于游戏、直播和日常娱乐,适合在 Windows、Linux、Google Colab 和 Mac 上使用。常见场景包括:游戏语音变声、直播主播声音伪装、二次元角色配音、在线会议隐私保护等。
voice-changer 是目前功能最全面的开源实时 AI 变声方案之一,尤其适合对 RVC 模型有需求、希望低延迟实时变声的用户。
AI实时变声器Voice Changer2.1.4 CUDA版下载链接
https://pan.quark.cn/s/d031707d8c4b
对变声效果有极致追求的用户可下载辅助软件Studio One Pro 7增强真人声音效果
同时搜集了几个高质量的RVC模型,有需要的可自行体验。
相关推荐
 AI实时变声器软件RVC下载,游戏语音直播聊天虚拟声卡变声器设置方法
AI实时变声器软件RVC下载,游戏语音直播聊天虚拟声卡变声器设置方法- 极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
- 最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
- AI实时语音聊天对话系统,外语口语陪练/虚拟好友实时语音交流
- 多人对话声音克隆语音合成工具Chatterbox TTS免安装版,AI实时文字转语音
- 阿里Qwen3-TTS高质量声音克隆语音合成系统,AI视频配音多人对话生成工具
- 多人对话有声书制作软件VoxCPM Windows版整合包,高质量声音克隆语音合成工具
- 【免安装/解压即用】支持600+语言的神级TTS!OmniVoice 零样本语音克隆一键整合包发布
最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
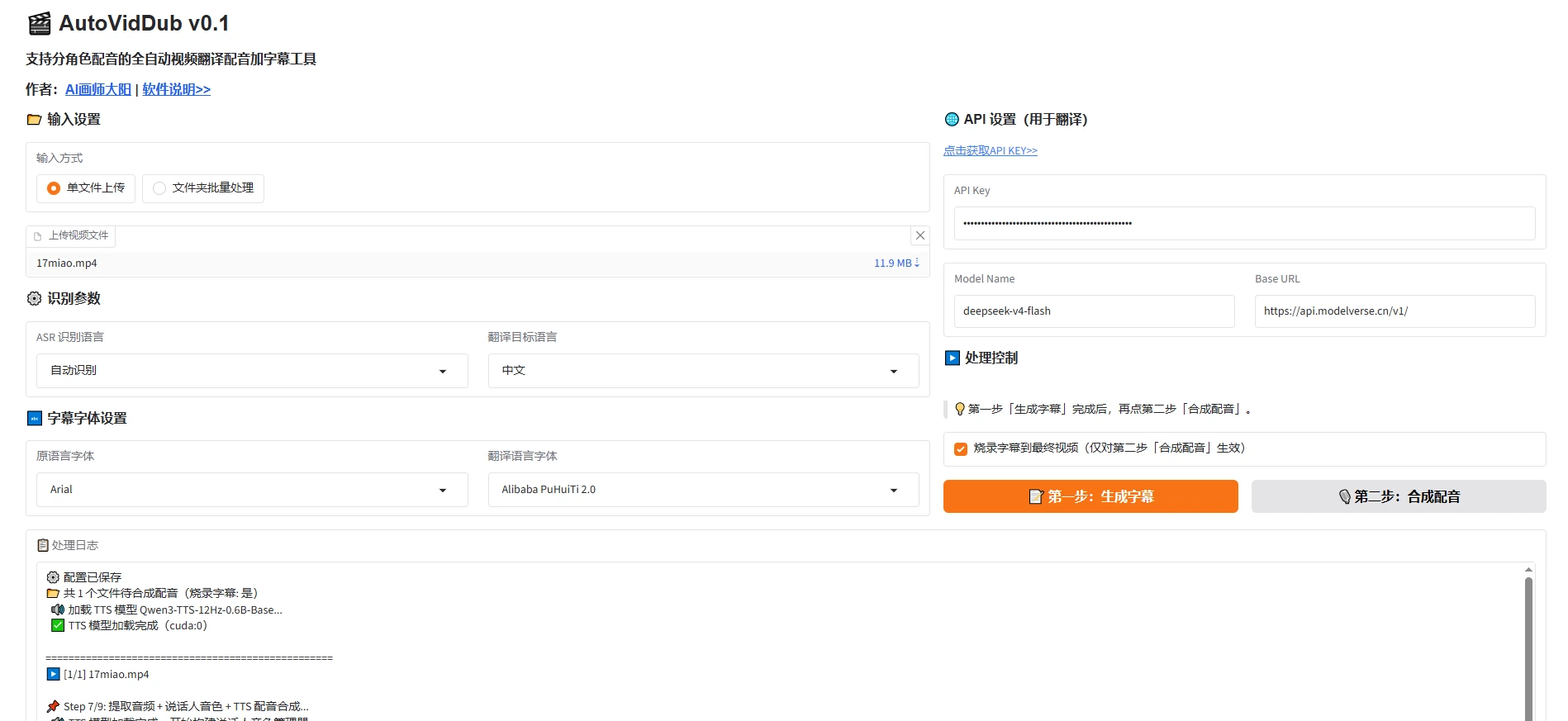
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
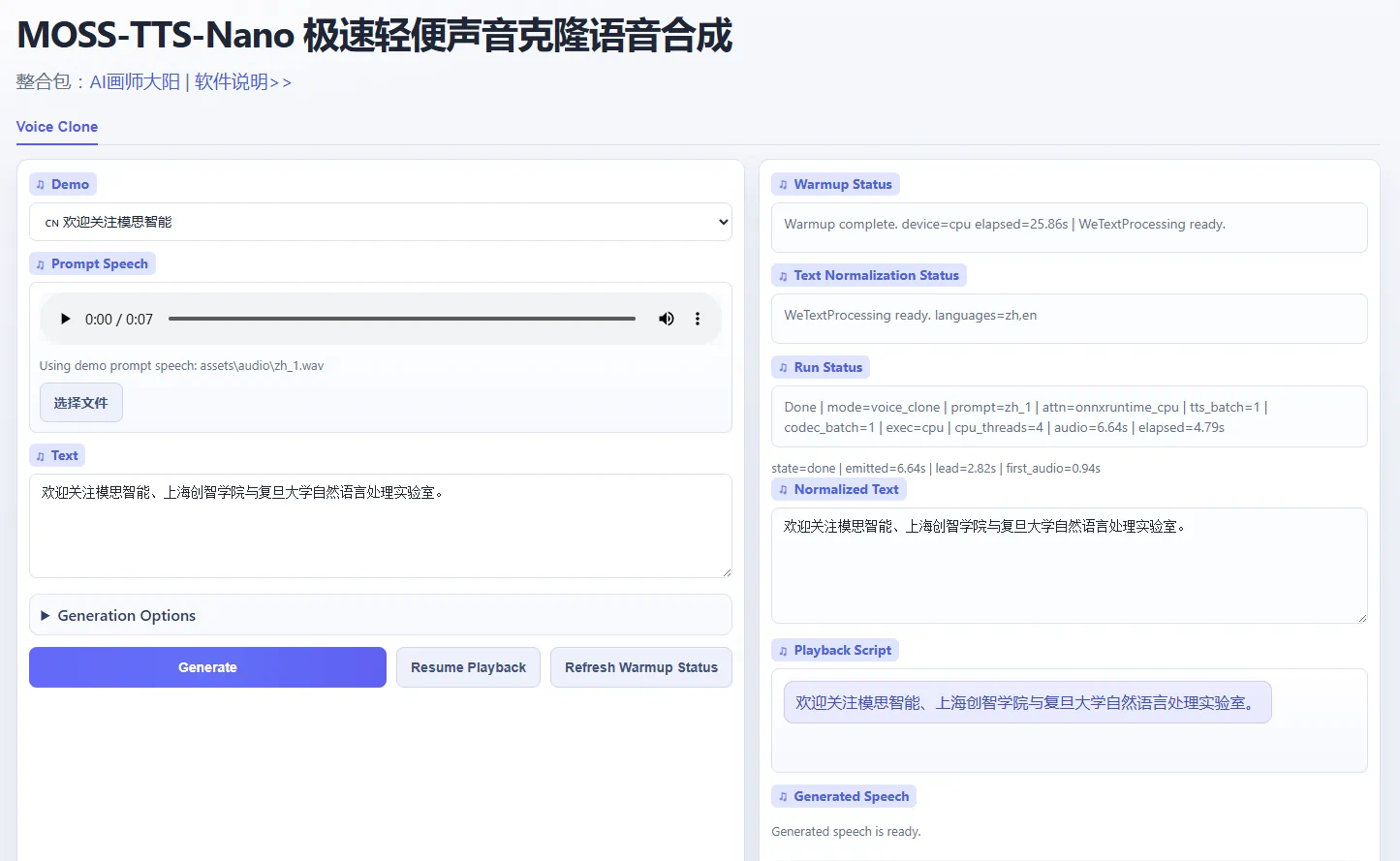
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
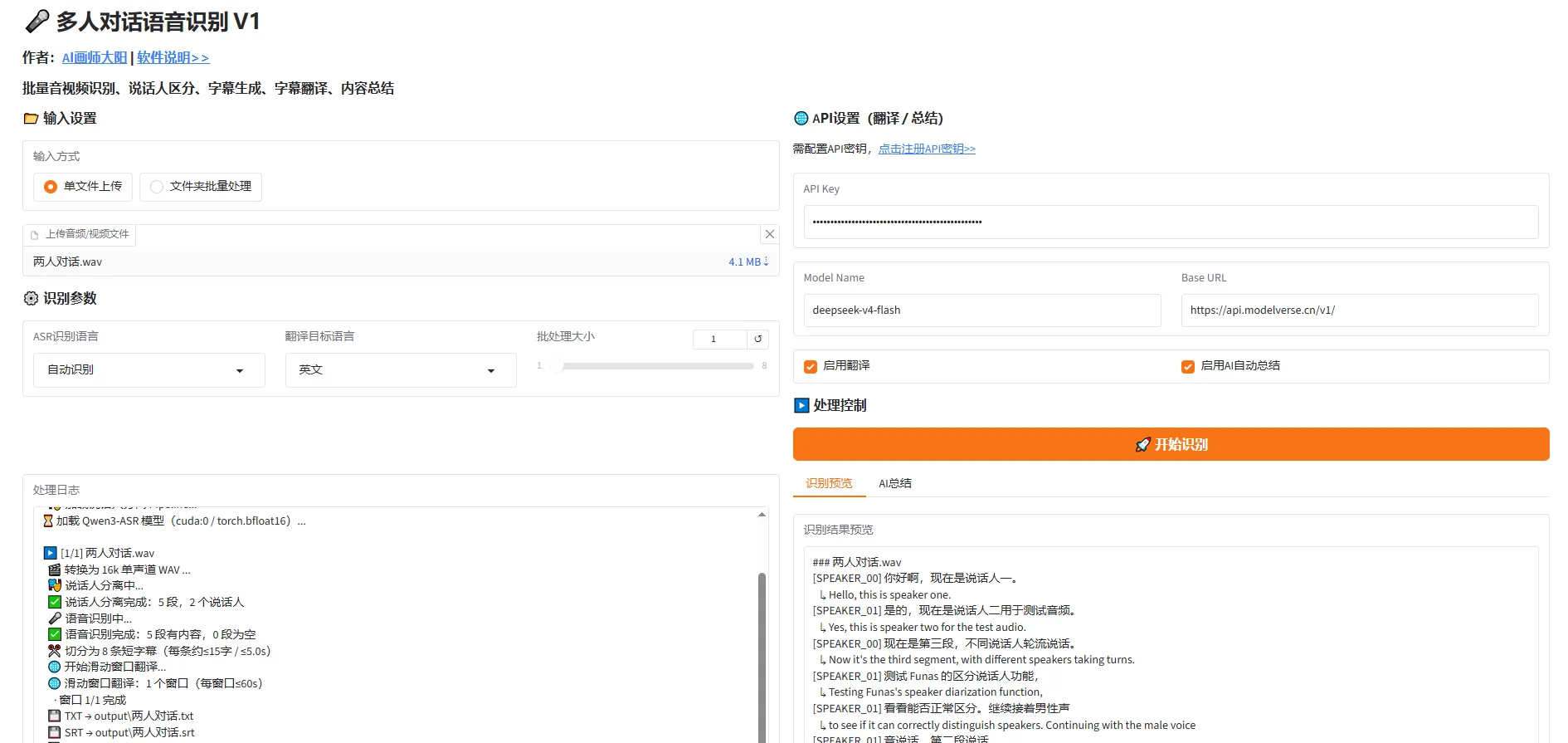
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
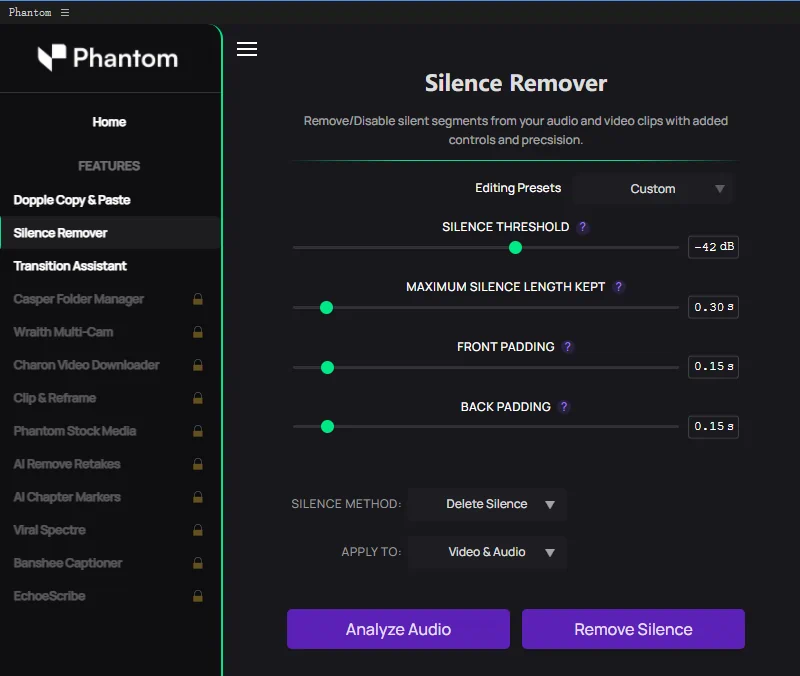
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
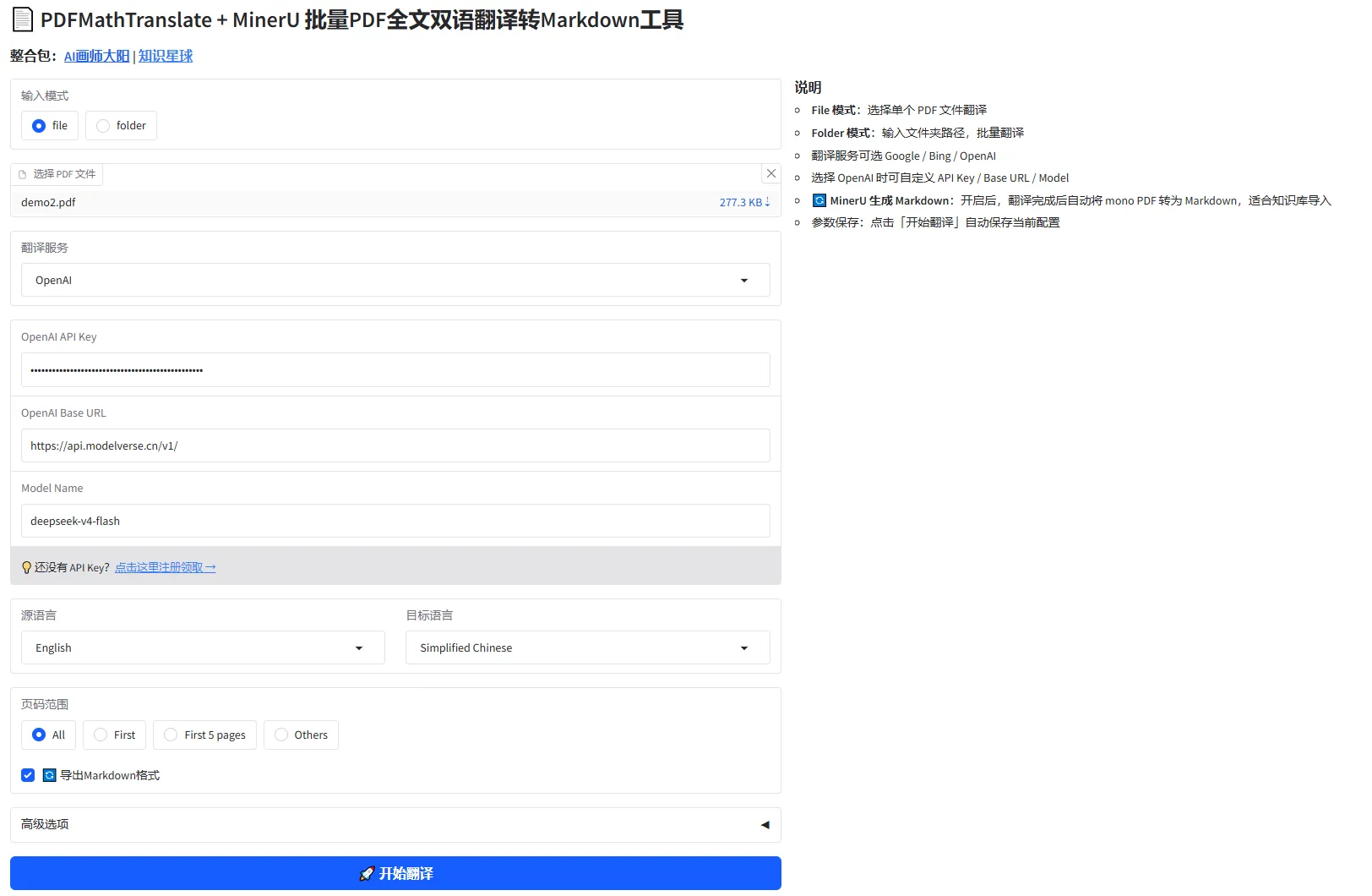
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...