Qwen3-TTS 是由阿里 Qwen 团队开发的新一代语音合成系统,基于自研的 Qwen3-TTS-Tokenizer-12Hz 编解码器和离散多码本 LM 架构,实现了端到端的全信息语音建模。它突破了传统级联架构的信息瓶颈,支持音色克隆、音色设计、预设音色合成等多种语音生成能力,覆盖 10 种主要语言,可广泛应用于内容创作、有声读物、语音助手、游戏配音等场景。
我基于当前最新版制作了免安装一键启动整合包,重做UI界面,并增加多人对话功能,取消Flash-Attention改为xformers实现了对低端显卡的友好支持,开箱即用。
核心技术亮点
- Qwen3-TTS-Tokenizer-12Hz 编码器:高效声学压缩与高维语义建模,完整保留副语言信息和声学环境特征。
- 离散多码书 LM 架构:真正的端到端架构,完全绕过传统 LM+DiT 方案的信息瓶颈和级联误差。
- 双轨混合流式生成架构:同时支持流式与非流式生成,首包延迟最低 97ms。
- 自然语言指令控制:通过文字描述即可控制音色、情感、语速、语调等多维声学属性。
模型系列与功能特点
Qwen3-TTS 提供三个核心模型,各自承担不同的语音合成任务:
| 模型 | 功能 | 支持尺寸 | 流式生成 | 指令控制 |
|---|---|---|---|---|
| CustomVoice(预设音色) | 使用预定义的 9 种高品质音色进行语音合成,支持风格指令 | 0.6B / 1.7B | ✅ | ✅ |
| VoiceDesign(音色设计) | 通过自然语言描述创造全新的定制音色 | 1.7B 仅 | ✅ | ✅ |
| Base(音色克隆) | 基于 3 秒参考音频快速克隆任意音色 | 0.6B / 1.7B | ✅ | ❌ |
支持的 10 种语言
中文、英语、日语、韩语、法语、德语、西班牙语、葡萄牙语、俄语、意大利语。
9 种预设音色(CustomVoice)
| 说话人 | 音色描述 | 母语 |
|---|---|---|
| Vivian | 明亮、略带锋芒的年轻女声 | 中文 |
| Serena | 温暖、温柔的年轻女声 | 中文 |
| Uncle_Fu | 低沉稳重的成熟男声 | 中文 |
| Dylan | 北京男声,清晰自然 | 中文(京腔) |
| Eric | 成都男声,略带沙哑明亮 | 中文(川渝) |
| Ryan | 动感男声,节奏感强 | 英语 |
| Aiden | 阳光美式男声,中音清晰 | 英语 |
| Ono_Anna | 俏皮日系女声,轻快灵动 | 日语 |
| Sohee | 温暖韩系女声,情感丰富 | 韩语 |
每位说话人均可使用模型支持的所有语言进行合成,但以其母语表现最佳。
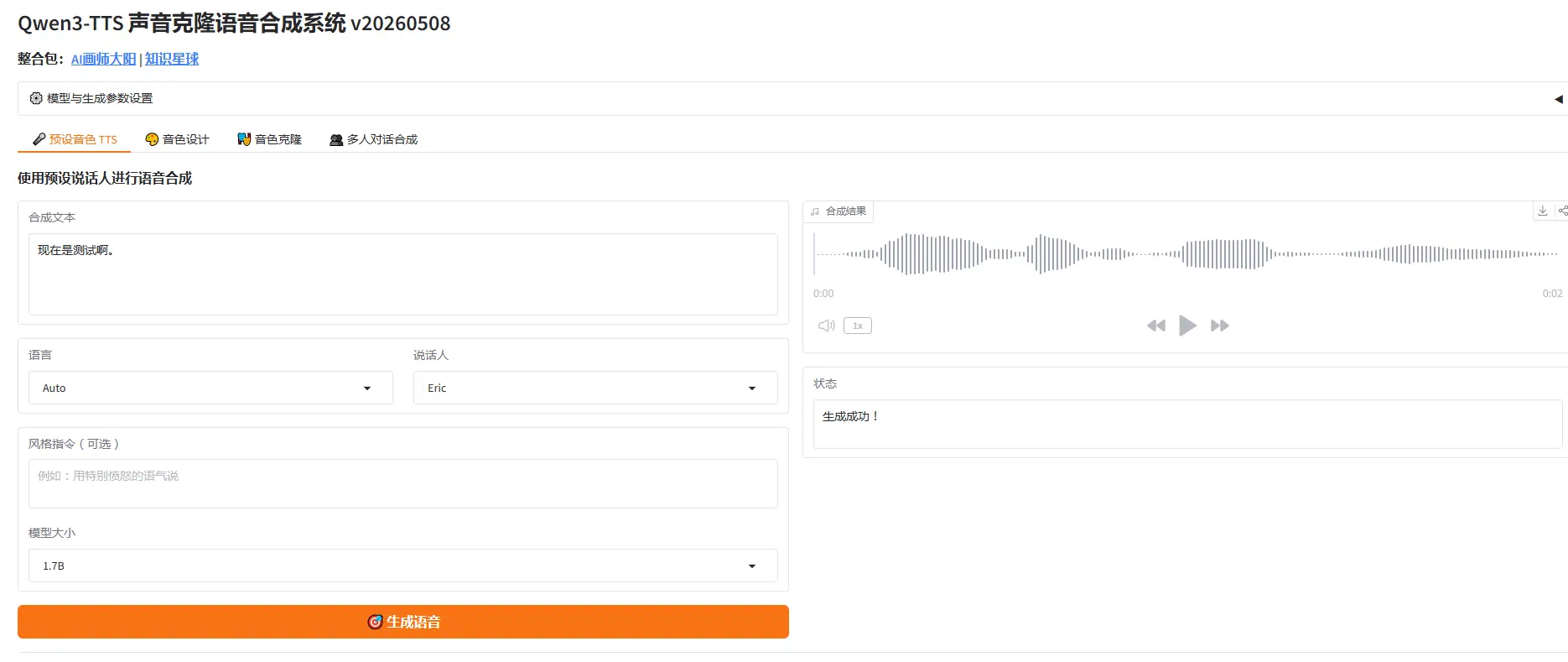
WebUI界面功能详解
软件启动后会自动打开 http://127.0.0.1:7860 WEBUI操作界面。界面共分为 4 个功能标签页和一个设置面板。
⚙️ 模型与生成参数设置(可折叠面板)
在页面顶部,可展开进行全局参数配置:
- 模型路径:分别设置 CustomVoice、VoiceDesign、Base(音色克隆)三个模型的路径(支持 Hugging Face 模型 ID 或本地目录)。
- 设备选择:cuda:0 / cuda:1 / cpu,GPU 显存不足时可切换到 CPU(速度较慢)。
- 精度选择:bfloat16(推荐)、float16、float32。低精度节省显存,高精度质量更稳。
- 生成参数:
max_new_tokens(最大生成 Token 数):控制输出音频长度,值越大可生成越长音频。Temperature:温度值,越高随机性越强,越低越稳定(推荐 0.9)。Top-K:采样时仅考虑概率最高的 K 个 token,越小越稳定。Top-P:核采样累积概率阈值。重复惩罚系数:抑制词语重复,值越大重复越少。
- 保存设置:修改参数后点击保存,下次生成时自动加载新配置。
标签页 1:🎤 预设音色 TTS
功能:使用预设说话人合成语音,适合快速生成高质量朗读内容。
操作步骤:
- 在”合成文本”框中输入要合成的文字。
- 选择语言(建议明确选择以获最佳效果,或选 Auto 自动识别)。
- 选择说话人(从 9 种预设音色中挑选)。
- (可选)填写风格指令,例如:”用特别愤怒的语气说”、”温柔地、轻声细语地念”。
- 选择模型大小(0.6B 更快省显存,1.7B 质量更高)。
- 点击 生成语音,稍后在右侧音频播放器中试听结果。
典型用例:有声书朗读、语音提示、多风格配音。
标签页 2:🎨 音色设计
功能:用自然语言描述你想要的音色,模型直接生成符合描述的语音。这是 Qwen3-TTS 最具创新性的功能之一。
操作步骤:
- 在”合成文本”框中输入要合成的文字内容。
- 选择语言。
- 填写音色描述(关键输入),例如:
- “体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显”
- “低沉沙哑的磁性男声,语速较慢,带有沧桑感”
- “用难以置信的语气说话,但语气中要开始流露出一丝恐慌”
- 点击 生成语音。
典型用例:游戏角色配音、动画配音、创意内容制作,无需真实录音即可创造全新音色。
标签页 3:🎭 音色克隆
功能:上传一段参考音频,克隆其音色后合成任意新内容。包含两个子标签页。
子标签页 3.1:克隆并合成
操作步骤:
- 上传参考音频(WAV/MP3 等格式,建议 3-30 秒清晰录音)。
- 填写参考文本(参考音频的准确转录文字)。
- 或勾选 “仅使用说话人向量”(无需参考文本,但克隆效果略差)。
- 在”待合成文本”中输入要生成的内容。
- 选择语言和模型大小。
- 点击 克隆并生成。
子标签页 3.2:保存 / 加载音色
功能:将音色克隆的提示(Prompt)保存为 .pt 文件,便于重复使用,避免每次合成都重新提取特征。
保存音色:上传参考音频 → 填写参考文本 → 点击保存 → 下载 .pt 文件。
加载并合成:上传之前保存的 .pt 文件 → 输入待合成文本 → 点击生成语音。
典型用例:为固定角色批量配音、保护隐私(只需提供音色文件不需要保留原始音频)。
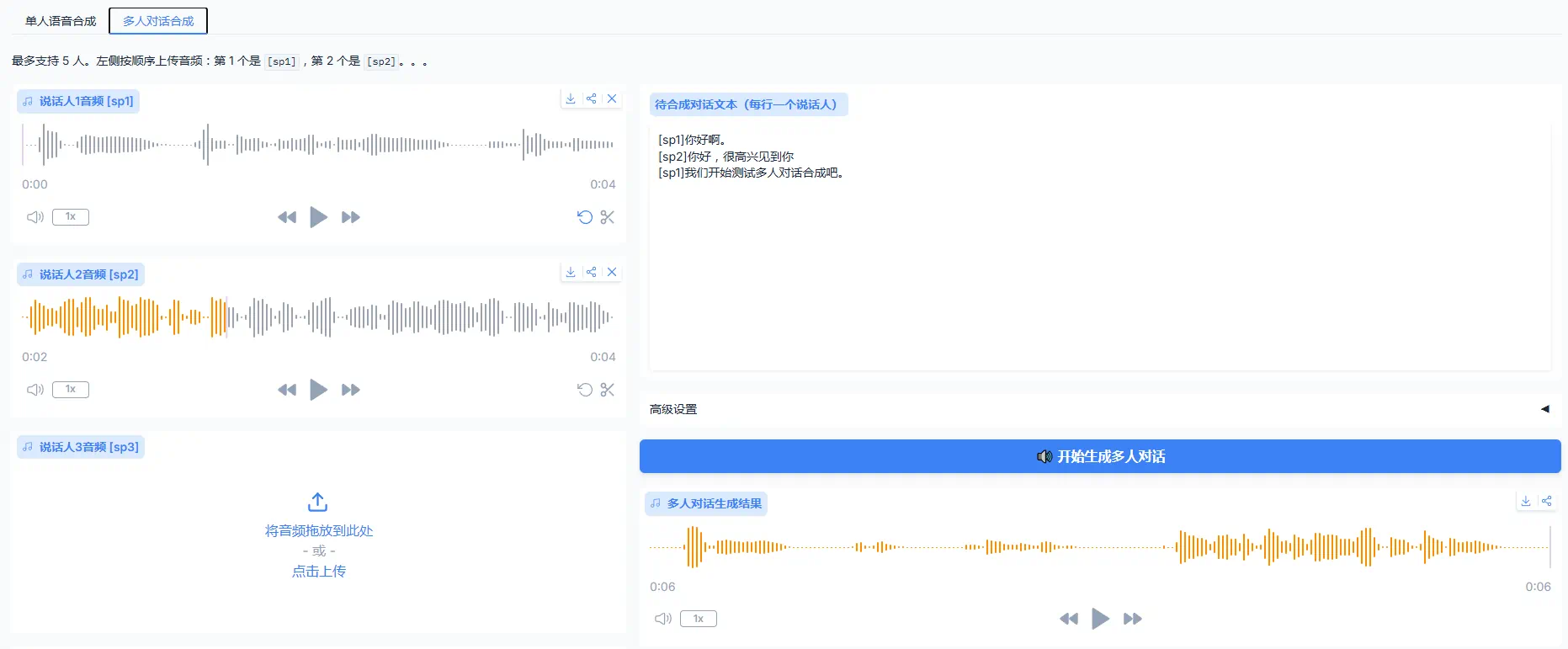
标签页 4:👥 多人对话合成
功能:一次合成包含多个角色的对话音频,自动拼接。
操作步骤:
- 在”对话文本”框中按格式编写剧本,使用
[sp1]~[sp5]标签标记不同说话人:[sp1]你好啊,[sp2]今天天气不错, [sp3]我们一起去玩吧,[sp4]好啊,[sp5]太棒了! - 选择语言。
- 在下方发音人参考音频设置区域,为每个用到的 sp 标签上传对应的参考音频。
- 点击 生成多人对话,系统自动分段合成并拼接为完整对话音频。
典型用例:广播剧制作、播客对谈、动画配音、语言教学对话示例。
使用注意事项
硬件要求
| 模型 | 最低显存(bfloat16) | 推荐显存 |
|---|---|---|
| 0.6B 系列 | 约 2GB | 4GB+ |
| 1.7B 系列 | 约 4GB | 6GB+ |
- 显存不足时可尝试 float16 精度或切换到 CPU 模式(速度会显著变慢)。
- 若使用多人对话功能,需额外预留显存空间。
参考音频要求(音色克隆)
- 时长:建议 3~10 秒,过短则音色特征提取不充分,过长则冗余。
- 清晰度:尽量使用干净、无背景噪音的录音。
- 内容:参考音频应包含说话人自然的音色特征,建议覆盖多种发音。
- 格式:程序自动处理常见音频格式(WAV、MP3、FLAC 等)。
语言选择建议
- 明确选择目标语言可获得最佳合成效果。
- 若不确定文本语言,可选 “Auto” 让模型自动识别。
- 预设说话人以母语表现最佳,但也可用于其他语言。
合成文本注意事项
- 文本不宜过短(少于 5 个字效果可能不理想)。
- 过长文本建议分批次生成,避免 max_new_tokens 不足截断。
- 标点符号会影响韵律,合理使用逗号、句号、问号等。
- 暂时不支持 SSML(语音合成标记语言)。
音色文件使用
- 保存的
.pt音色文件包含了说话人向量和可选的参考编码,不含原始音频,可安全分发。 - 音色文件与特定 Base 模型版本相关,大版本更新后可能需要重新生成。
免责声明
本软件生成的音频由 AI 模型自动合成,仅供体验与展示模型效果。用户应自行评估并承担使用、传播或依赖该音频所产生的一切风险与责任。严禁利用本服务生成违法、有害、诽谤、欺诈、深度伪造或侵犯他人权益的内容。
Qwen3-TTS声音克隆语音合成软件下载链接
https://pan.quark.cn/s/e0374d90ef7a
相关推荐





最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
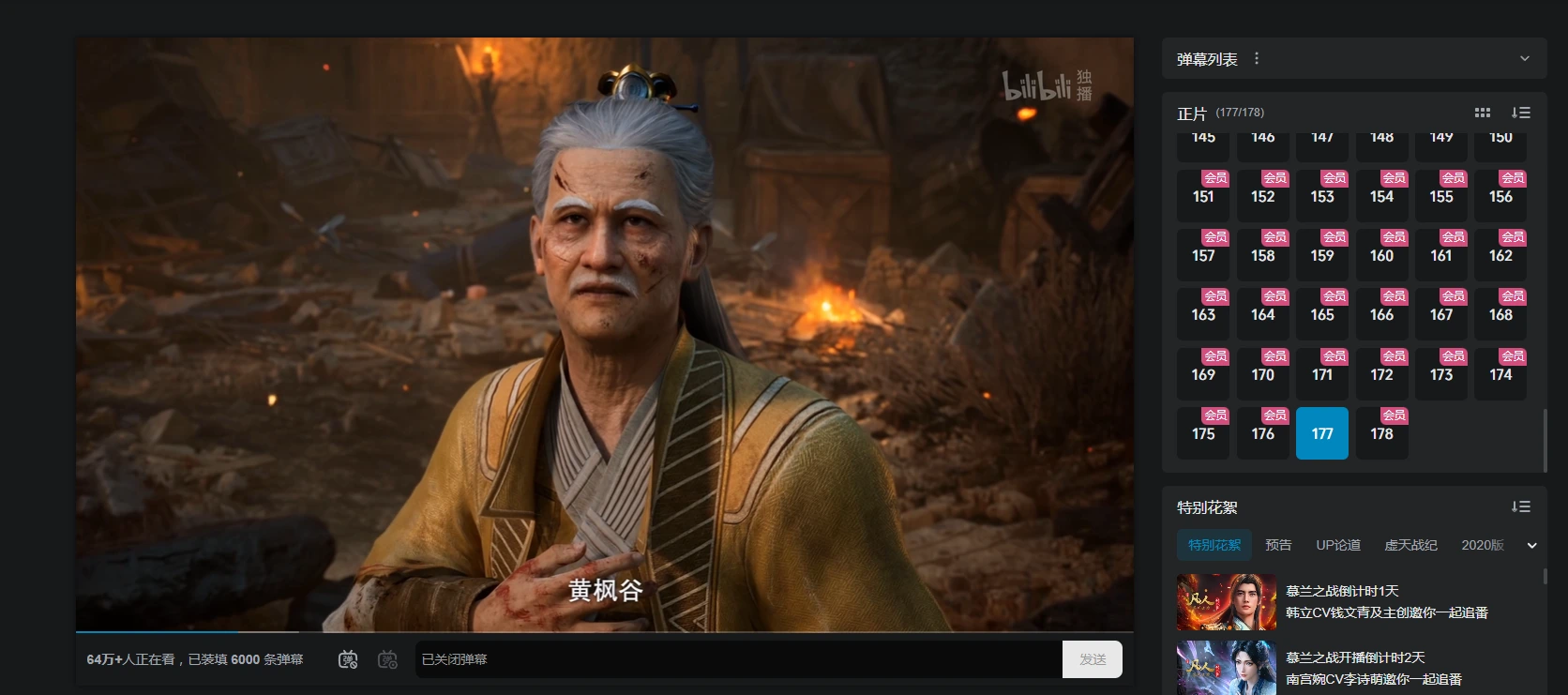
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
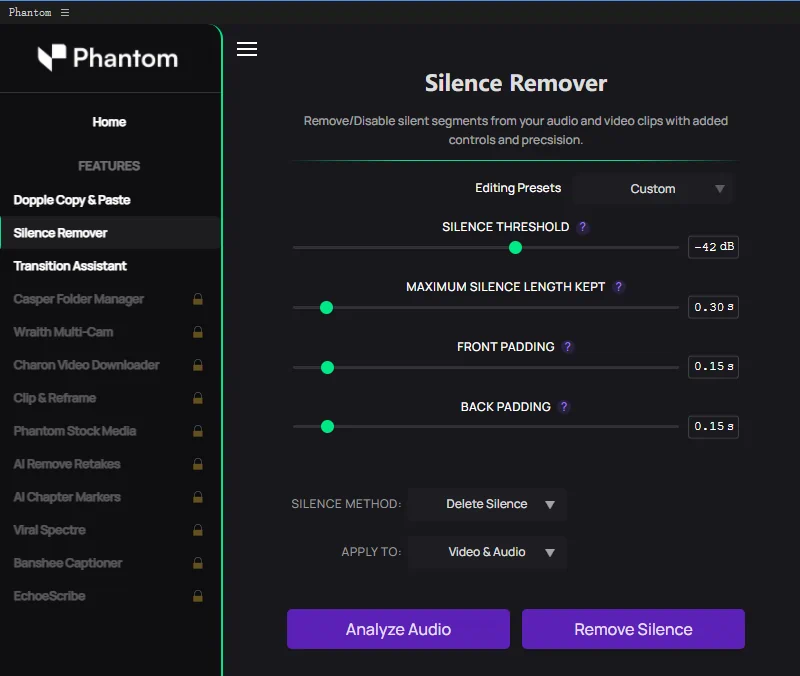
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
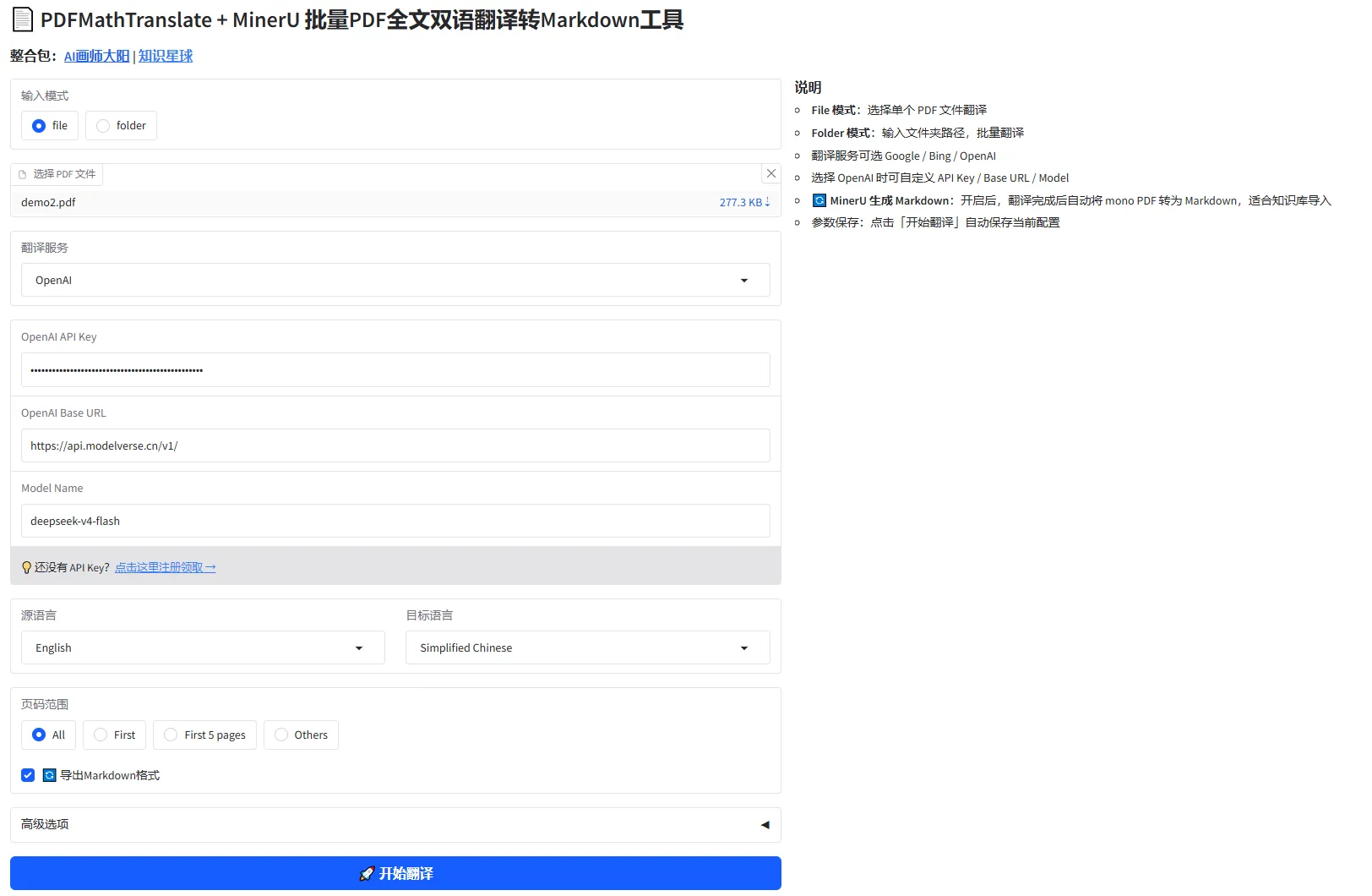
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...