又一款AI歌曲创作利器:ACE-Step,ACE-Step是刚发布不久的AI自动谱曲AI自动演唱软件,软件在歌曲生成速度、音乐连贯性和可控性上相对同类软件有了较大提升。ACE-Step在3小时前刚发布了新版本,我基于当前最新版本制作了免安装一键启动整合包。
ACE-Step介绍
官方说明:
我们推出 ACE-Step,这是一个用于音乐生成的全新开源基础模型,它克服了现有方法的关键局限性,并通过整体架构设计实现了最佳性能。当前的方法在生成速度、音乐连贯性和可控性之间面临着固有的权衡。例如,基于 LLM 的模型(例如 Yue、SongGen)在歌词对齐方面表现出色,但推理速度慢且存在结构性伪影。另一方面,扩散模型(例如 DiffRhythm)虽然能够实现更快的合成速度,但通常缺乏长距离的结构连贯性。
ACE-Step 通过将基于扩散的生成与 Sana 的深度压缩自动编码器 (DCAE) 和轻量级线性变换器相结合,弥补了这一差距。它进一步利用 MERT 和 m-hubert 在训练过程中对齐语义表征 (REPA),从而实现快速收敛。因此,我们的模型在 A100 GPU 上仅需 20 秒即可合成长达 4 分钟的音乐,比基于 LLM 的基线快 15 倍,同时在旋律、和声和节奏指标上实现了卓越的音乐连贯性和歌词对齐。此外,ACE-Step 保留了细粒度的声学细节,支持语音克隆、歌词编辑、混音和音轨生成(例如,歌词到人声、歌唱到伴奏)等高级控制机制。
我们的愿景并非构建另一个端到端的文本到音乐流程,而是为音乐 AI 构建一个基础模型:一个快速、通用、高效且灵活的架构,使其能够轻松地在其上训练子任务。这为开发强大的工具铺平了道路,这些工具可以无缝集成到音乐艺术家、制作人和内容创作者的创作工作流程中。简而言之,我们的目标是为音乐构建一个稳定的传播时刻。
- 🎸 支持所有主流音乐风格,提供多种描述格式,包括短标签、描述性文字或用例场景
- 🎷 能够使用适当的乐器和风格创作不同类型的音乐
- 🗣️ 支持 19 种语言,其中表现最好的 10 种语言包括:
- 🇺🇸 英语、🇨🇳 中文、🇷🇺 俄语、🇪🇸 西班牙语、🇯🇵 日语、🇩🇪 德语、🇫🇷 法语、🇵🇹 葡萄牙语、🇮🇹 意大利语、🇰🇷 韩语
- ⚠️由于数据不平衡,不太常见的语言可能表现不佳
- 🎹 支持不同流派和风格的各种器乐生成
- 🎺 能够为每种乐器制作具有适当音色和表现力的逼真的乐器曲目
- 🎼 可以使用多种乐器进行复杂的编曲,同时保持音乐的连贯性
- 🎙️ 能够高质量地呈现各种声音风格和技巧
- 🗣️ 支持不同的声音表达,包括各种歌唱技巧和风格
- ⚙️ 使用无需训练、推理时间优化技术实现
- 🌊 流匹配模型生成初始噪声,然后使用 trigFlow 的噪声公式添加额外的高斯噪声
- 🎚️ 可调节原始初始噪声和新高斯噪声之间的混合比,以控制变化程度
- 🖌️ 通过在目标音频输入中添加噪声并在 ODE 过程中应用掩码约束来实现
- 🔍 当输入条件与原始生成不同时,只能修改特定方面,同时保留其余方面
- 🔀 可以与变体生成技术结合,在风格、歌词或人声上创造局部变化
- 💡 创新性地运用流程编辑技术,实现歌词的局部修改,同时保留旋律、人声和伴奏
- 🔄 可与生成的内容和上传的音频配合使用,大大增强了创作可能性
- ℹ️ 当前限制:一次只能修改歌词的一小部分以避免失真,但可以连续应用多个编辑
- 🔊 基于对纯语音数据进行微调的 LoRA,可直接从歌词生成语音样本
- 🛠️ 提供众多实用应用,如人声演示、指南曲目、歌曲创作辅助和人声编排实验
- ⏱️ 提供一种快速测试歌词演唱效果的方法,帮助歌曲创作者更快地进行迭代
- 🎛️ 与 Lyric2Vocal 类似,但针对纯乐器和样本数据进行了微调
- 🎵 能够根据文本描述生成概念音乐制作样本
- 🧰 有助于快速创建乐器循环、音效和音乐元素以供制作
- 🔥 基于纯说唱数据进行微调,打造专门用于说唱生成的 AI 系统
- 🏆 预期功能包括 AI 说唱对决和通过说唱进行叙事表达
- 📚 Rap 具有出色的叙事和表达能力,具有非凡的应用潜力
- 🎚️ 一个基于多轨数据进行训练的控制网-lora,用于生成单独的仪器词干
- 🎯 以参考音轨和指定乐器(或乐器参考音频)作为输入
- 🎹 输出与参考音轨互补的乐器主干,例如为长笛旋律创建钢琴伴奏或为主音吉他添加爵士鼓
- 🔄 StemGen 的逆过程,从单个声乐音轨生成混合主音轨
- 🎵 以声乐曲目和指定风格作为输入,产生完整的声乐伴奏
- 🎸 创建完整的乐器伴奏来补充输入的人声,从而可以轻松地为任何声音录音添加专业的伴奏
ACE-Step整合包使用说明
首先将网盘内的软件压缩包下载到本地电脑上并解压,然后双击启动软件.exe。
高配英伟达显卡选正常模式,低配英伟达显卡选低显存模式。
软件成功启动后会自动打开webui界面。
【Select previous generated input params】选择以前生成的音频使用的参数设置。
【Audio Duration】生成的歌曲时长,最大240秒,-1为随机。
【Format】输出歌曲的音频格式,支持wav,mp3,ogg,flac4种。
【Enable Audio2Audio】启用使用参考音频功能,生成歌曲时长会以参考音频时长为准。
【Preset】音乐风格流派,如流行,嘻哈,古典等。
【Tags】输入想要生成歌曲的描述性标签、类型或场景描述(以逗号分隔),使用关键词female女性和male男性来指定歌曲为女声或男声。
【Lyrics】歌词,支持使用 [verse]、[chorus] 和 [bridge] 等歌词结构标签来区分歌词的不同部分。
使用 [instrumental] 或 [inst] 来生成器乐。不支持在歌词中使用流派结构标签。
【Basic Settings】基本设置,如推理步数,种子
【Advanced Settings】高级设置,调度器类型,如euler,heun,pingpong。2025.05.14更新的功能:新增 Stable Audio Open Small 采样器的pingpong。使用SDE实现更好的音乐一致性和质量,包括歌词对齐和风格对齐。使用更好的方法重新实现Audio2Audio
其它更多设置有感兴趣的可以自行研究测试。
点击【Generate】按钮开始生成歌曲。
还可以对生成的或现有歌曲进行二次修改。
【Retake】使用不同的种子重新生成略有变化的音乐
调整差异,以控制重拍与原作的差异程度
【Repainting】 有选择地重新生成音乐的特定部分
指定要重新绘制的部分的开始和结束时间
选择源音频(text2music输出、上次重新绘制或上传)
【Edit】通过更改标签或歌词修改现有音乐
在“only _ lyrics”模式(保留旋律)或“remix”模式(更改旋律)之间进行选择
调整编辑参数以控制保留多少原始内容
【Extend】在现有乐曲的开头或结尾添加音乐
指定左右延伸长度
选择要扩展的源音频
视频教程及效果演示:https://nuowa.net/1916
注意事项
英伟达显卡显存不低于6G
支持英伟达50系列显卡
英伟达20系列或是英伟达显卡显存较低(如12G以下)电脑建议使用低显存模式
使用前请将英伟达显卡驱动更新到最新版本
只支持Windows 10或11
软件运行路径中不要有非英文字符和空格,待处理文件素材也要注意
AI歌曲生成软件ACE-Step一键启动整合包下载链接
相关推荐
 AI歌曲创作软件DiffRhythm一键启动包,自定义风格AI谱曲演唱
AI歌曲创作软件DiffRhythm一键启动包,自定义风格AI谱曲演唱- 阿里文本转音乐软件InspireMusic整合包下载,免费AI歌曲生成工具
- 极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
- 最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
- AI实时语音聊天对话系统,外语口语陪练/虚拟好友实时语音交流
- 多人对话声音克隆语音合成工具Chatterbox TTS免安装版,AI实时文字转语音
- AI实时变声器Voice Changer2.1.4 CUDA版下载,高质量RVC变声软件
- 阿里Qwen3-TTS高质量声音克隆语音合成系统,AI视频配音多人对话生成工具

最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
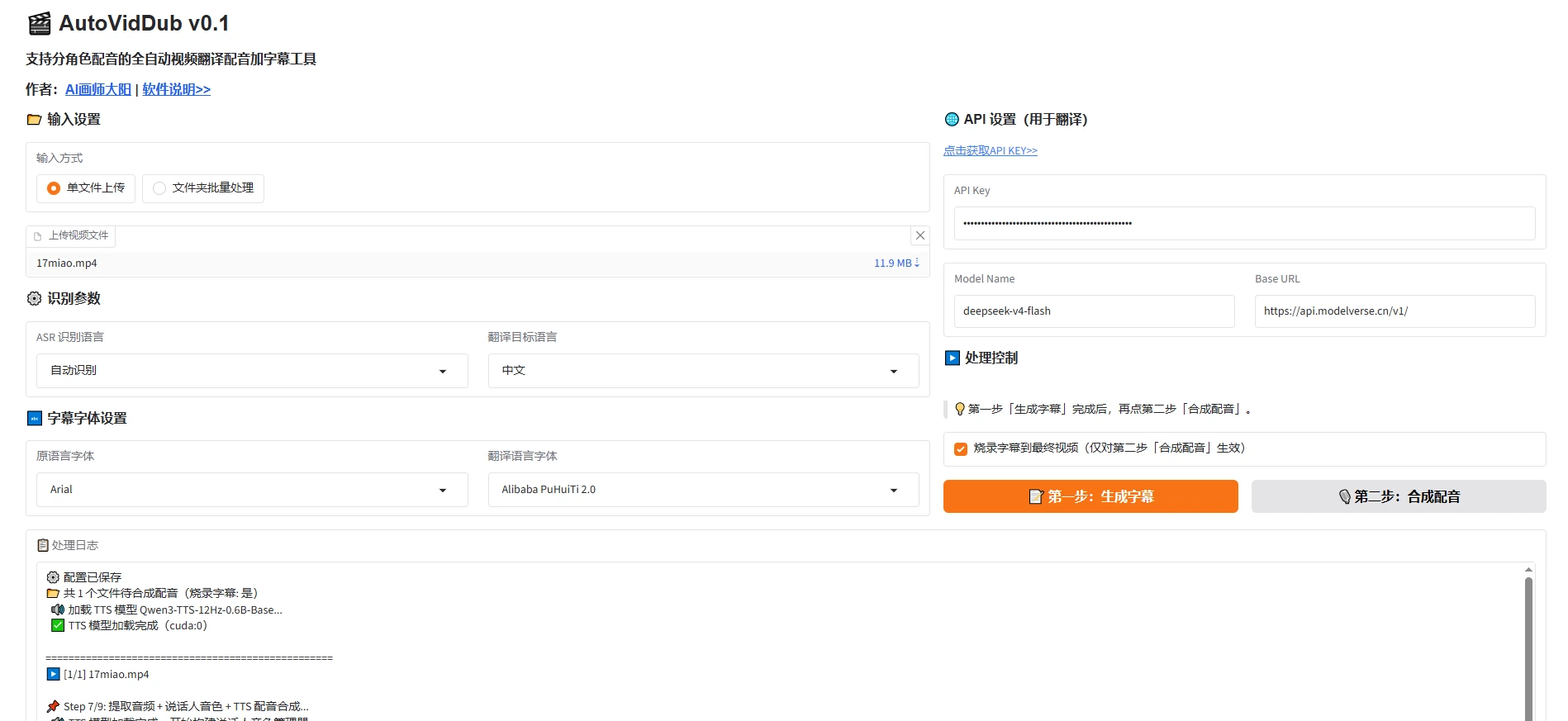
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
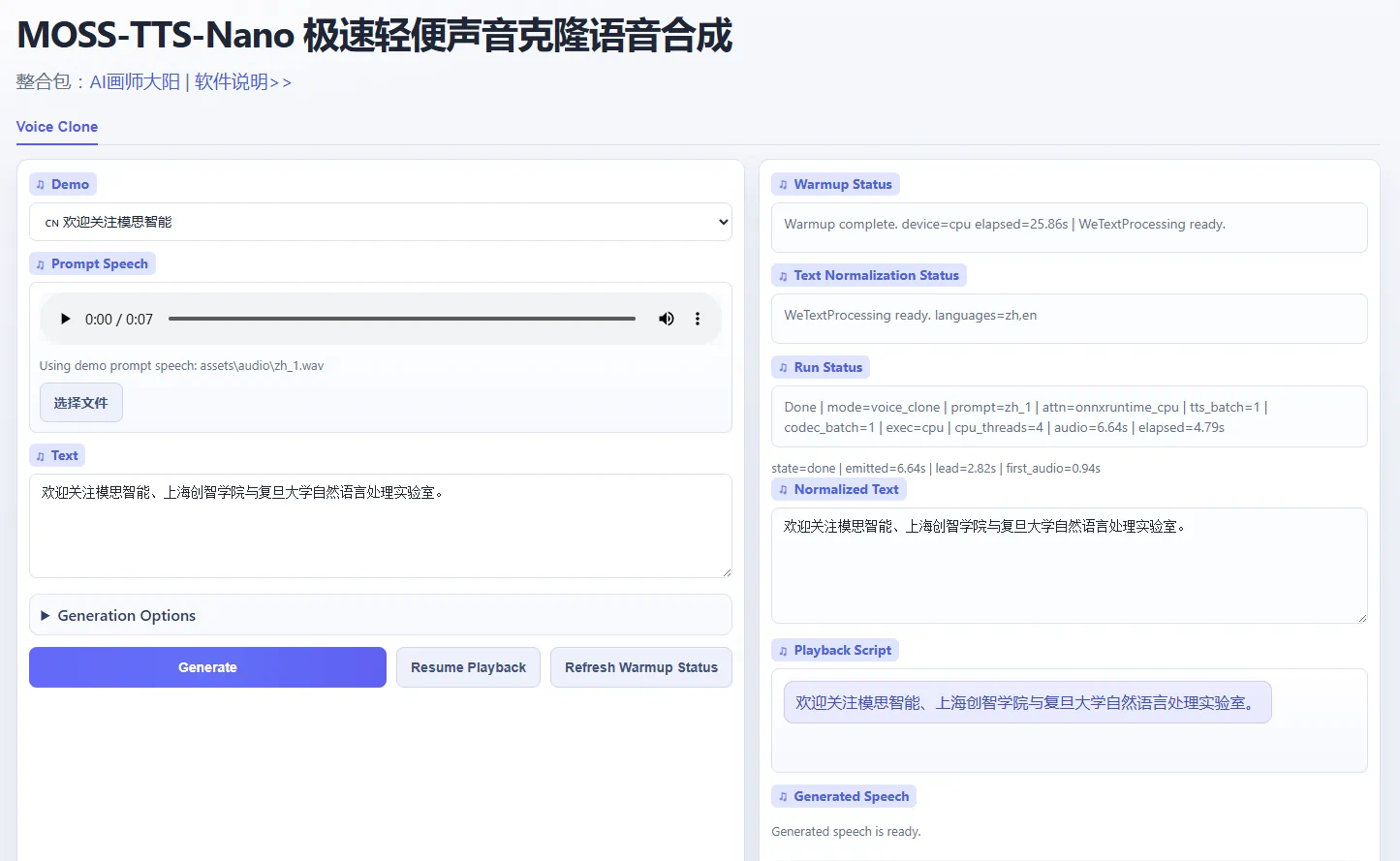
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
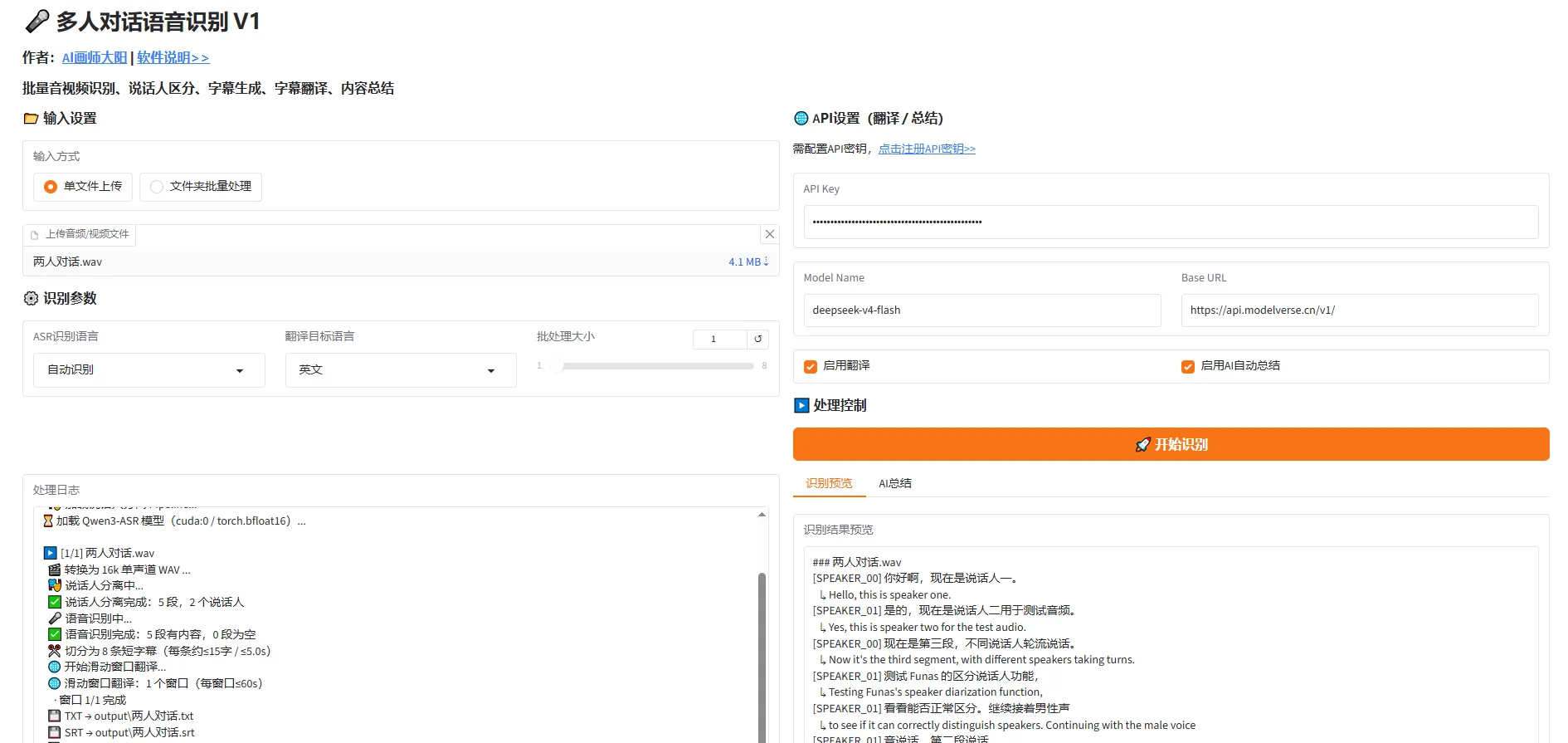
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
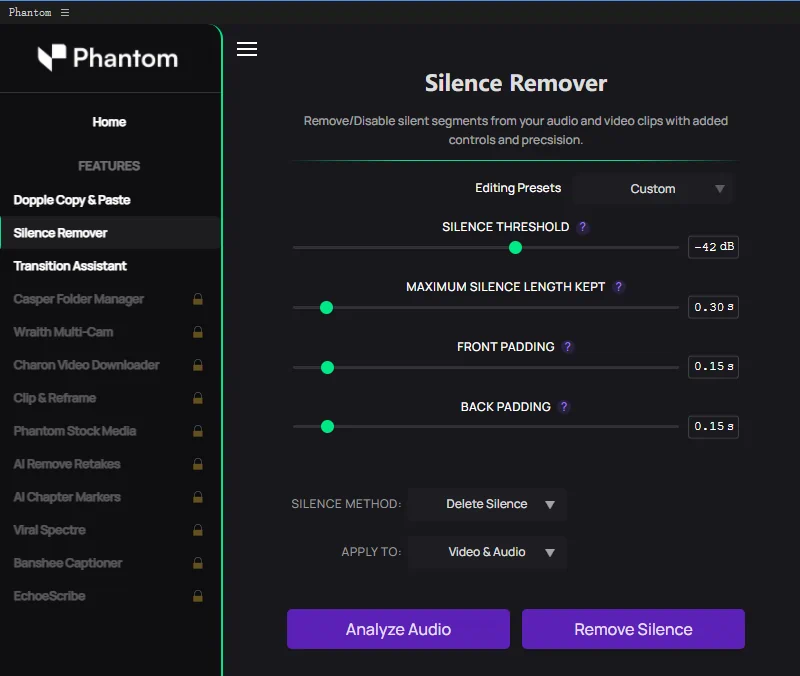
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
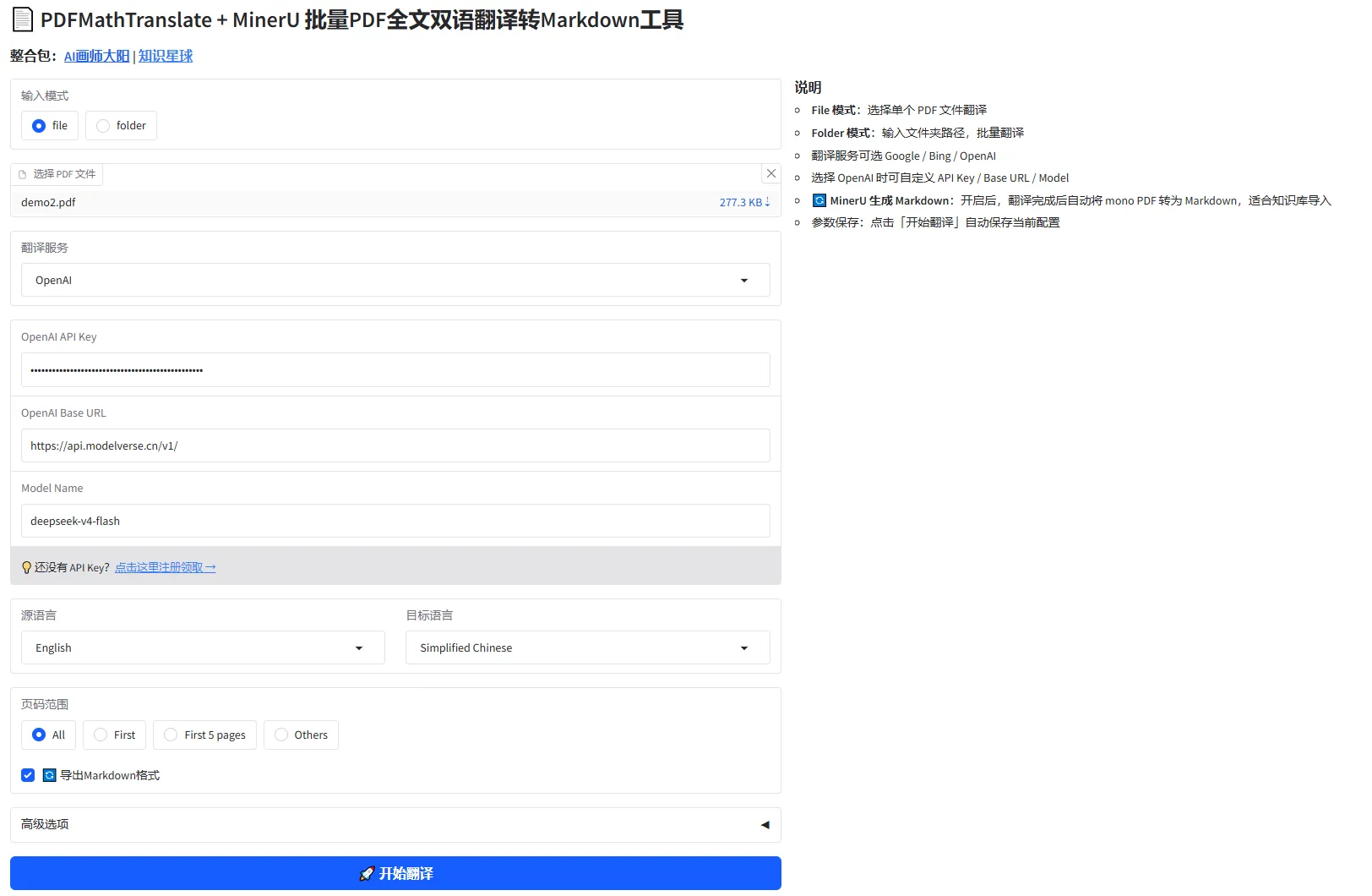
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...