建站十几年建了十几个网站了,小到每日几个十几个访客,大到每日上万访客,黑客攻击是任何一个有流量的网站都避免不了的,一般网站流量越大被攻击频率越高。虽然说我网站现在流量也不大,但是也免不了被攻击。虽然说阿里云也有很多云安全产品,购买之后防黑客这点小小攻击很简单,但是我服务器一年还不到100块钱,那些安全服务一年得大几百块钱。再说现在黑客攻击频率不大,能用免费方法自己抗就自己抗了,抗不过去再花钱买额外服务。本次记录一下通过python脚本记录黑客在WordPress网站暴力破解登录次数过多就自动拉黑IP的方法,方便以后查看。
首先服务器用的是阿里云ECS,系统是Debian
先创建 RAM 用户的 AccessKey:
- 为了安全,不要使用阿里云主账号的 AccessKey。
- 进入 RAM 访问控制 控制台(找不到就搜RAM),创建一个新用户(例如命名为
waf-bot),访问配置里勾选【使用永久 AccessKey 访问】 - 创建成功后,保存好 AccessKey ID 和 AccessKey Secret,不然就找不到了。
- 在左侧导航权限管理-权限策略-创建权限策略。服务里选择“云服务器ECS”,“指定操作”里搜“securityGroup”,把读操作,写操作,列表操作都勾选上,然后点击确定创建完成。
- 再到用户列表里给这个用户waf-bot授权,在“权限管理”-“新增授权”,找到刚才新增的这个自定义策略“securityGroup”,确定授权
新建安全组“Auto-Block-SG”,删除里面的默认所有规则,然后把服务器实例添加进这个安全组去,之后的所有操作都在这个安全组内进行,这样就算误操作也不会影响原安全组和网站运行。
服务器安装阿里云最新的 Python SDK
pip3 install alibabacloud_ecs20140526 alibabacloud_tea_openapi服务器创建python脚本
import os
import re
import json
import time
from collections import defaultdict
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_ecs20140526.client import Client as EcsClient
from alibabacloud_ecs20140526 import models as ecs_models
# ================= 配置区 =================
ACCESS_KEY_ID = 'XXXXX'
ACCESS_KEY_SECRET = 'XXXXX'
REGION_ID = 'cn-heyuan' # 你的ECS所在地域,如 cn-hangzhou, cn-beijing
SECURITY_GROUP_ID = 'sg-xxx' # 你的安全组ID (专门用于拦截的安全组)
# 使用字典为不同的路径配置独立的阈值 (1分钟内的 POST 次数)
TARGET_RULES = {
'/login': 4,
'/wp-login.php': 4,
'/xmlrpc.php': 1
}
LOG_FILE = '/var/log/nginx/access.log' # Nginx 日志路径
STATE_FILE = '/root/blocked_ips.json' # 本地缓存账本路径
HIGH_WATERMARK = 490 # 高水位线:规则数达到此值触发清理
BATCH_DELETE_COUNT = 30 # 每次清理释放的旧 IP 数量
# =========================================
def init_aliyun_client():
"""初始化阿里云客户端"""
config = open_api_models.Config(
access_key_id=ACCESS_KEY_ID,
access_key_secret=ACCESS_KEY_SECRET,
region_id=REGION_ID
)
return EcsClient(config)
def load_state():
"""读取本地 JSON 账本"""
if not os.path.exists(STATE_FILE):
return {}
try:
with open(STATE_FILE, 'r') as f:
return json.load(f)
except json.JSONDecodeError:
return {} # 如果文件损坏,返回空字典重置
def save_state(state):
"""保存状态到本地 JSON 账本"""
with open(STATE_FILE, 'w') as f:
json.dump(state, f, indent=4)
def revoke_ip_in_aliyun(client, ip):
"""调用 API:在安全组中删除拦截规则 (解封)"""
request = ecs_models.RevokeSecurityGroupRequest(
region_id=REGION_ID,
security_group_id=SECURITY_GROUP_ID,
ip_protocol='all',
port_range='-1/-1',
source_cidr_ip=f"{ip}/32",
policy='Drop'
)
client.revoke_security_group(request)
def block_ip_in_aliyun(client, ip):
"""调用 API:在安全组中添加拦截规则 (封禁)"""
request = ecs_models.AuthorizeSecurityGroupRequest(
region_id=REGION_ID,
security_group_id=SECURITY_GROUP_ID,
ip_protocol='all',
port_range='-1/-1',
source_cidr_ip=f"{ip}/32",
policy='Drop',
priority=1,
description='Auto blocked by Python Script'
)
client.authorize_security_group(request)
def check_and_clean_capacity(client, state):
"""容量管理:高低水位线机制批量清理最老IP"""
current_count = len(state)
if current_count >= HIGH_WATERMARK:
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] [大扫除] 规则数达 {current_count},触发批量清理...")
# 按照时间戳从小到大(从老到新)排序
sorted_ips = sorted(state.items(), key=lambda item: item[1])
ips_to_remove = sorted_ips[:BATCH_DELETE_COUNT]
for ip, _ in ips_to_remove:
try:
revoke_ip_in_aliyun(client, ip)
del state[ip]
print(f" [-] 已释放最老 IP: {ip}")
except Exception as e:
print(f" [x] 释放 IP {ip} 失败: {e}")
save_state(state)
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] [大扫除] 结束,当前规则数: {len(state)}")
return state
return state
def analyze_logs_and_block():
state = load_state()
# 升级:使用嵌套字典记录每个IP对各个路径的访问次数
# 结构类似: { '8.8.8.8': { '/login': 3, '/xmlrpc.php': 1 } }
ip_path_counts = defaultdict(lambda: defaultdict(int))
try:
log_lines = os.popen(f"tail -n 2000 {LOG_FILE}").readlines()
except Exception as e:
print(f"读取日志失败: {e}")
return
log_pattern = re.compile(r'^(\d+\.\d+\.\d+\.\d+).*?"(POST|GET) (.*?) HTTP')
# 3. 统计恶意动作
for line in log_lines:
match = log_pattern.search(line)
if match:
ip = match.group(1)
method = match.group(2)
url = match.group(3)
# 匹配不同的目标路径并分别计数
if method == 'POST':
for target_path in TARGET_RULES.keys():
if target_path in url:
ip_path_counts[ip][target_path] += 1
break # 匹配到一个路径就跳出,提高执行效率
# 4. 判断并执行封禁
client = None
need_save = False
# 遍历所有出现过的 IP 及其各路径访问次数
for ip, counts in ip_path_counts.items():
# 遍历该 IP 访问过的每个路径
for path, count in counts.items():
# 查表对比:当前路径的访问次数,是否达到该路径对应的封禁阈值
if count >= TARGET_RULES[path]:
if ip not in state:
if not client:
client = init_aliyun_client()
state = check_and_clean_capacity(client, state)
try:
# 打印日志时,精确定位是因为哪个路径被封的
print(f" [!] 发现恶意 IP: {ip} (请求 {path} 达 {count} 次),准备拦截...")
block_ip_in_aliyun(client, ip)
state[ip] = time.time()
need_save = True
print(f" [+] IP: {ip} 封禁成功。")
except Exception as e:
print(f" [x] 封禁 IP {ip} 失败 (可能已在安全组或遇到限流): {e}")
# 只要该 IP 触发了任意一条路径的拉黑规则,就不用再检查它的其他路径了
break
if need_save:
save_state(state)
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 检查完毕。\n" + "-"*40)
if __name__ == '__main__':
analyze_logs_and_block()创建定时任务,让服务器每分钟执行一次
crontab -e假设脚本路径是 /root/auto_block_ip.py
* * * * * /usr/bin/python3 /root/auto_block_ip.py >> /root/auto_block.log 2>&1
按ctrl + o ,回车,保存,ctrl +x 退出。
只要发现有 IP 在疯狂 POST /login,脚本就会悄无声息地调用阿里云接口,在安全组的最外围直接把这个 IP 屏蔽。黑客的后续请求连 Nginx 服务器都碰不到,更不用说消耗 WordPress 的数据库资源了。
部署完成后,你可以通过查看日志来监控脚本的工作情况
tail -f /root/auto_block.log如果平时没有被攻击,日志里只会安静地打印“开始检查…”和“检查完毕。”。当黑客开始爆破时,你会看到它迅速执行拦截
相关推荐



最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
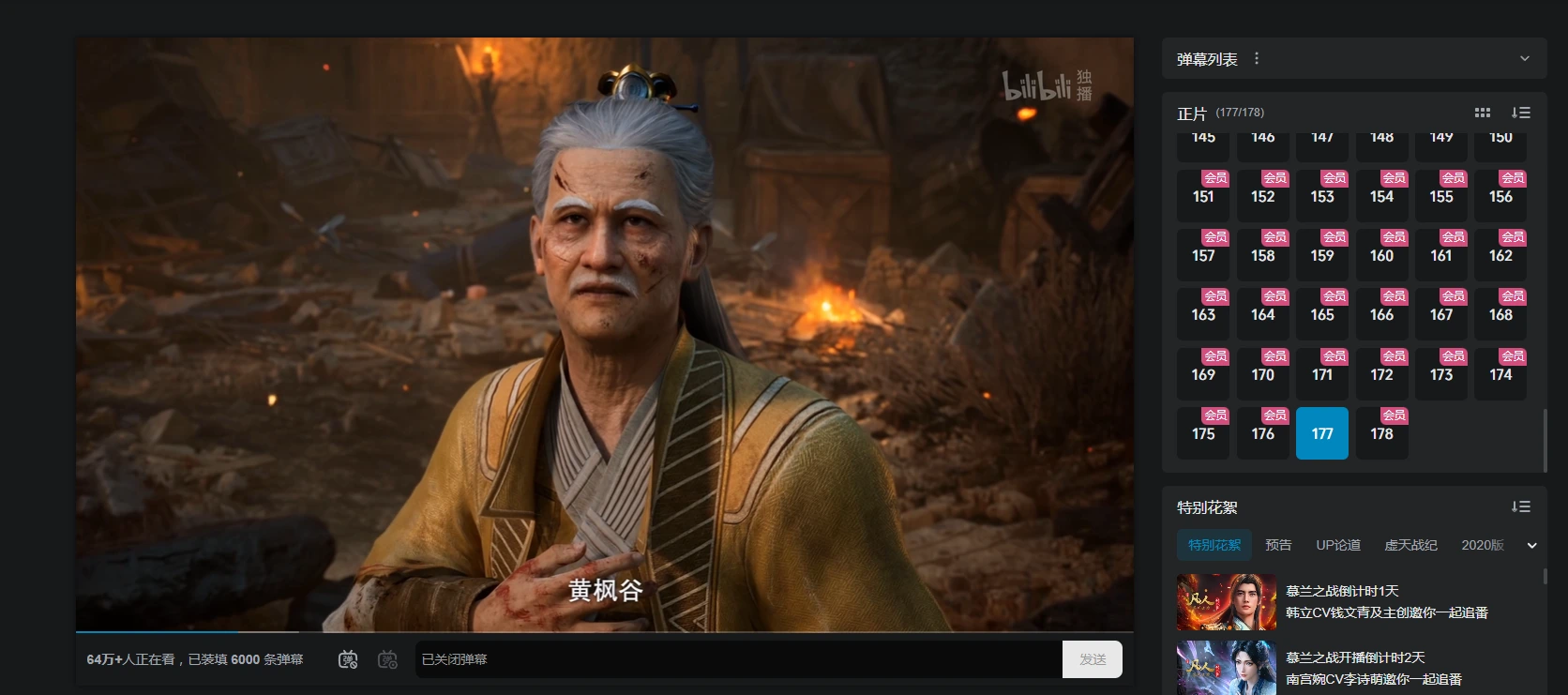
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
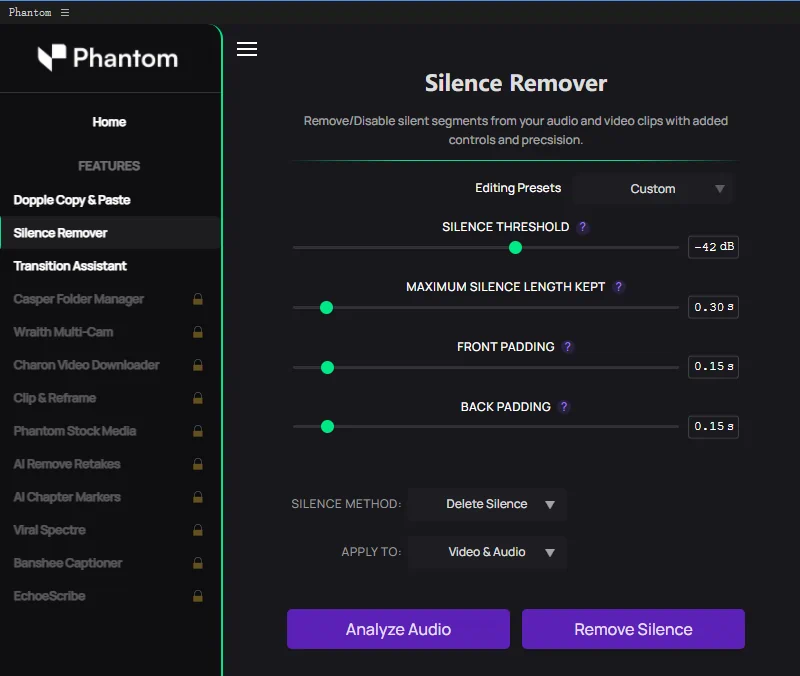
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
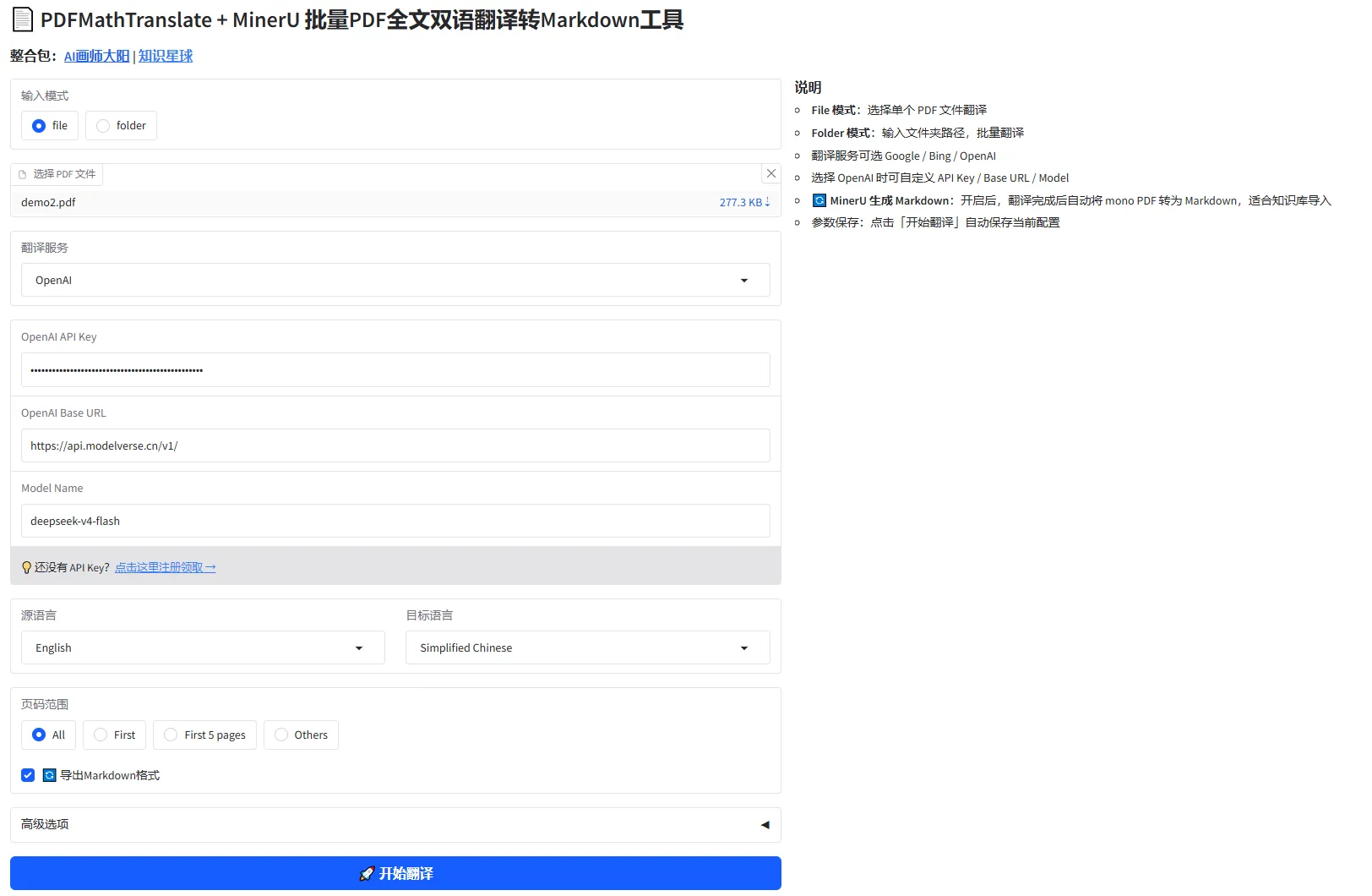
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...