github上有很多优秀的文本转语音开源程序,比如tts等,但是那些使用起来还是有些麻烦的,比如一种语言只有一个声音,虽然可以自己训练,但是操作起来也是有些麻烦的,比如我现在的需求是不需要自己定制声音,而且还能有多重声音可选,那这样的话微软edge-tts无疑是最佳选择,默认的中文就包含了14种声音,其中有普通话有粤语等。而且edge-tts安装起来也非常简单,非常适合我们新手操作。
github链接:https://github.com/rany2/edge-tts
一、安装
环境要求python>=3.7
Linux服务器先安装Python环境,这里以Python3.11.8为例,先运行安装更新命令,没有sudo先安装sudo,如果有sudo这步可以跳过。
apt-get update
apt-get install sudo
已安装有sudo,先更新,再安装相关依赖,命令如下,
sudo apt update
sudo apt install -y build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev curl libbz2-dev
然后下载Python3.11.8,命令如下
wget https://www.python.org/ftp/python/3.11.8/Python-3.11.8.tar.xz
解压压缩包
tar -xf Python-3.11.8.tar.xz
进入Python目录,编译并安装
cd Python-3.11.8
./configure –enable-optimizations
make -j `nproc`
sudo make install
安装TTS
安装命令
pip install edge-tts
输出successfully就表示安装完成了,可以输入edge-tts试试看看有没有输出相关信息。

二、使用
edge-tts –text “Hello, world!” –write-media hello.mp3 –write-subtitles hello.vtt
使用上面命令即可将文本“Hello, world”转换成语音并保存为hello.mp3文件,并生成字幕文件hello.vtt,使用的声音是默认声音,
想更换其它声音的话,可以输入
edge-tts -l
查看支持的所有声音,其中中文声音为zh开头的,
Name: zh-CN-XiaoxiaoNeural
Gender: Female
Name: zh-CN-XiaoyiNeural
Gender: Female
Name: zh-CN-YunjianNeural
Gender: Male
Name: zh-CN-YunxiNeural
Gender: Male
Name: zh-CN-YunxiaNeural
Gender: Male
Name: zh-CN-YunyangNeural
Gender: Male
Name: zh-CN-liaoning-XiaobeiNeural
Gender: Female
Name: zh-CN-shaanxi-XiaoniNeural
Gender: Female
Name: zh-HK-HiuGaaiNeural
Gender: Female
Name: zh-HK-HiuMaanNeural
Gender: Female
Name: zh-HK-WanLungNeural
Gender: Male
Name: zh-TW-HsiaoChenNeural
Gender: Female
Name: zh-TW-HsiaoYuNeural
Gender: Female
Name: zh-TW-YunJheNeural
Gender: Male
比如我们使用zh-CN-XiaoxiaoNeural这个女性角色声音生成中文语音,语速,音量都为默认,音调为50Hz,可以使用如下命令:
edge-tts –voice zh-CN-XiaoxiaoNeural –rate=-0% –volume=-0% –pitch=-50Hz –text “大家好,这里是微软文本转语音测试” –write-media 123.mp3
生成语音的同时还会生成字幕,对于做视频的人来说真的是太方便了。
三、API调用
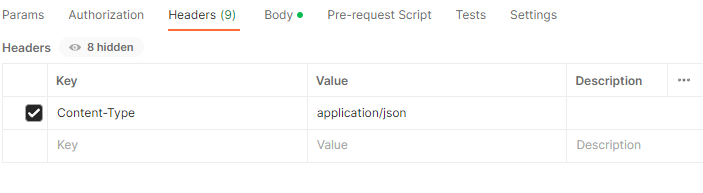
使用Python的fastapi库做一个post接口,如下tts.py文件:
import uvicorn import edge_tts import asyncio from fastapi import FastAPI, Request, Body app = FastAPI() @app.post(“/api/tts”) async def post_data(text: str = Body(”, title = ‘文本内容’, embed = True), voice: str = Body(”, title = ‘选择声音’, embed = True), name: str = Body(”, title = ‘文件名’, embed = True), rate: str = Body(”, title = ‘语速’, embed = True), pitch: str = Body(”, title = ‘音调’, embed = True), volume: str = Body(”, title = ‘音量’, embed = True)): output = “/home/work/tts/result/” + name + “.mp3” tts = edge_tts.Communicate(text = text, voice = voice, rate = rate, pitch = pitch , volume=volume) await tts.save(output) return {“message”: output} if __name__ == ‘__main__’: uvicorn.run(‘tts:app’, host = ‘0.0.0.0’, post = 80)
注意,你需要先查看一下你服务器上是否安装了uvicorn ,asyncio, fastapi等库,以及单独的ffmpeg功能
sudo apt-get install ffmpeg
output = “/home/work/tts/result/” + name + “.mp3″这句是生成最后的音频文件,注意你服务器上有没有/home/work/tts/result/这些文件夹,或是有没有权限创建,否则会报错。
创建启动文件 tts.sh:
使用nohup后台启动运行服务
–host 0.0.0.0表示允许任何用户可以访问这个api服务,
–port80是访问端口(可以修改,但是注意你服务器是否开放该端口)
nohup uvicorn tts:app –host 0.0.0.0 –port 8080>../tts/tts.log &
修改tts.sh文件为可执行文件:
chmod 777 tts.sh
启动服务
./tts.sh
API测试
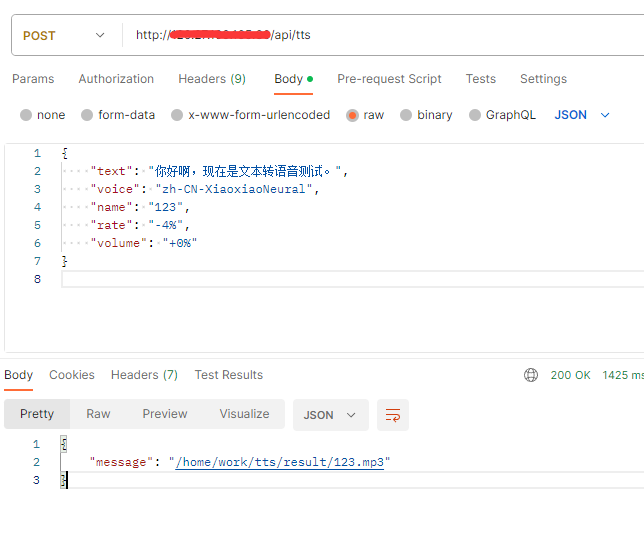
OK了,成功搭建了一个自己的微软文本转语音服务器
(文章是我原本发布在知乎上的,知乎文章删除了,这里做个备份)
相关推荐


最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
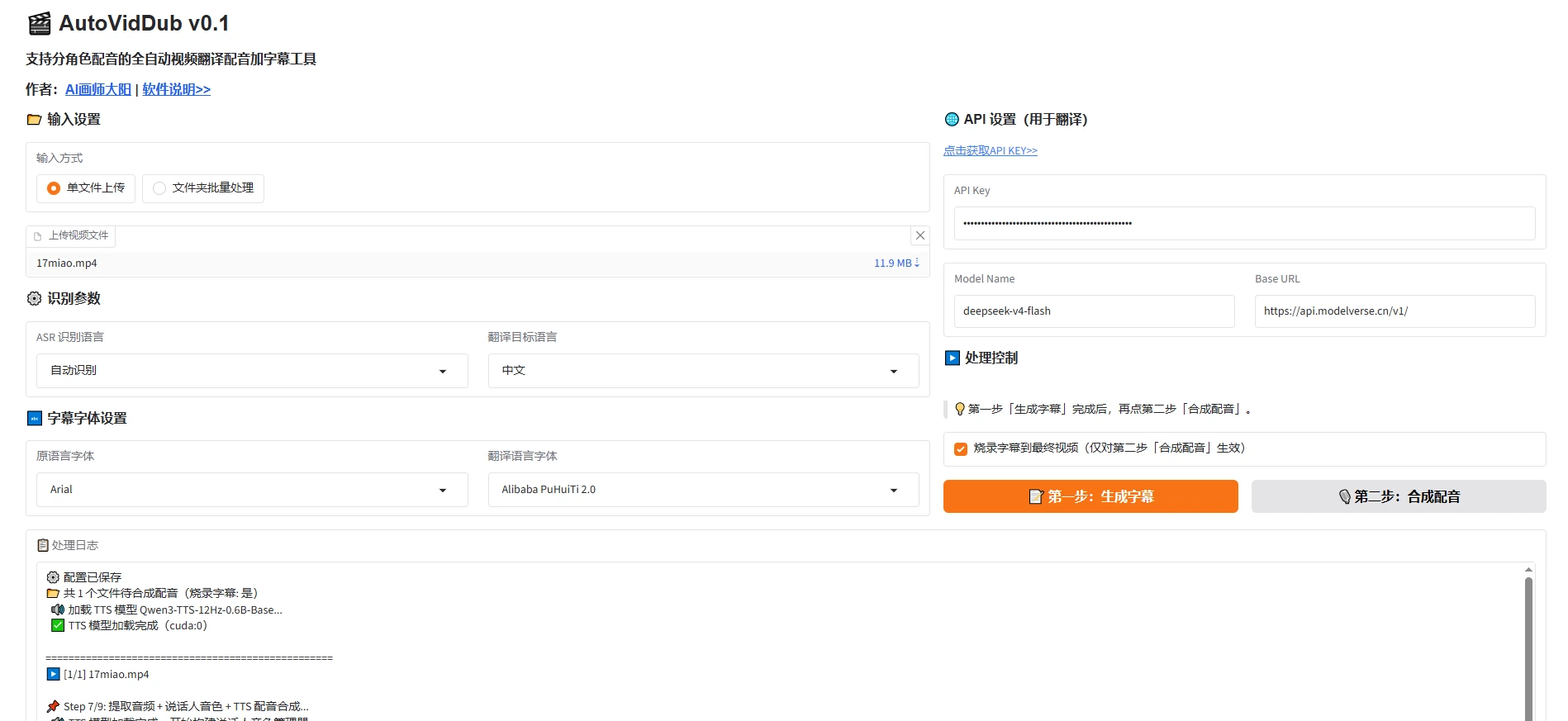
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
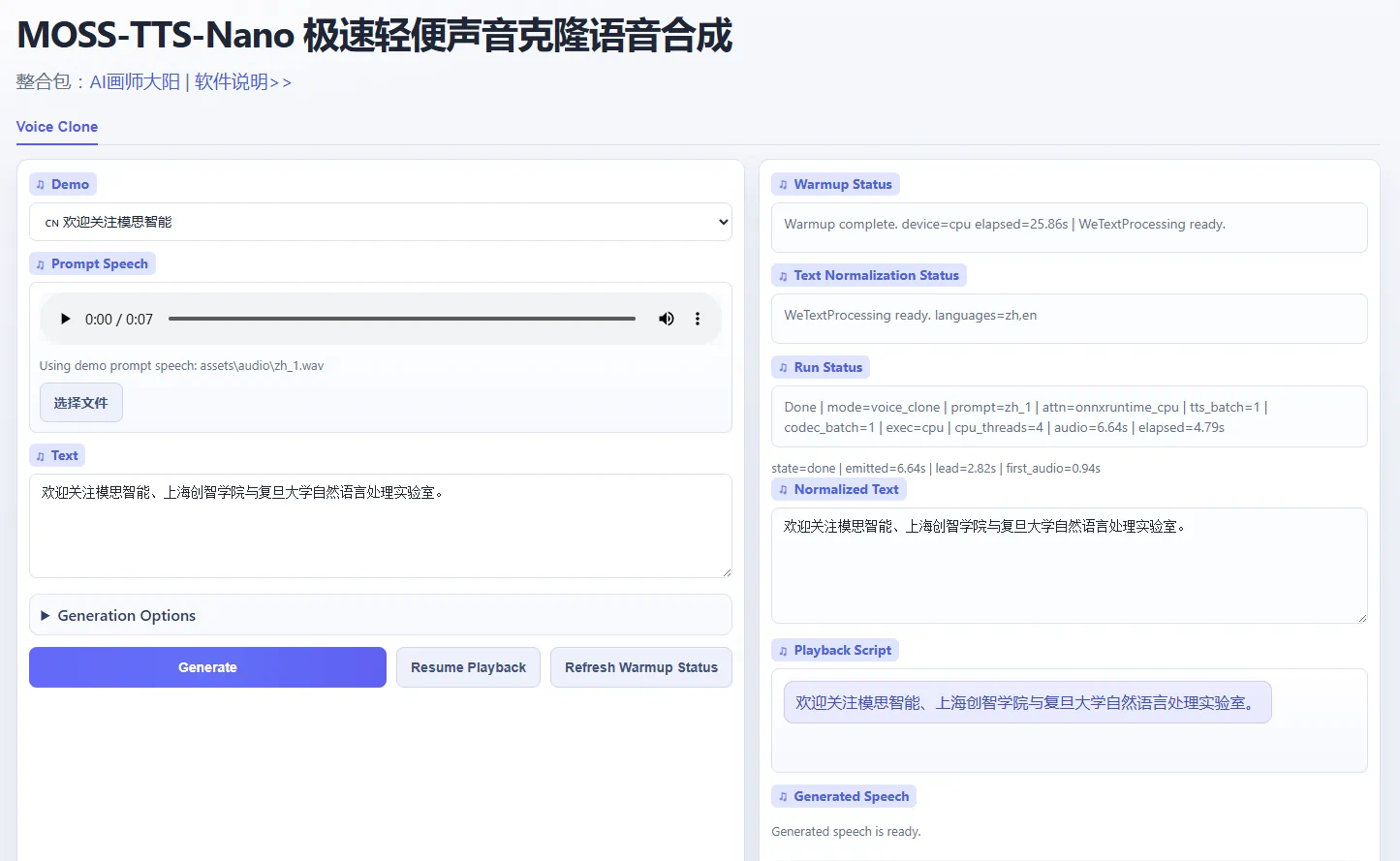
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
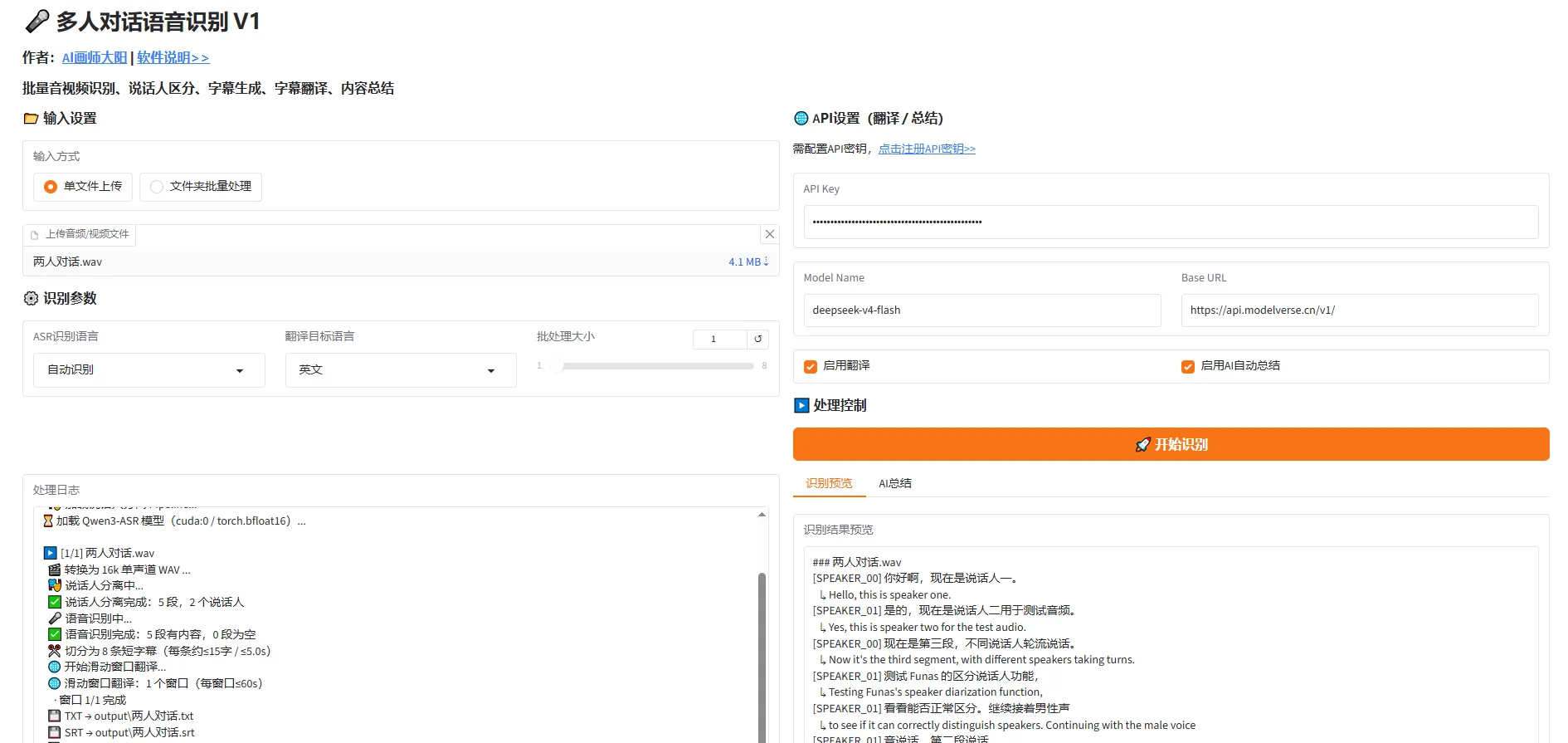
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
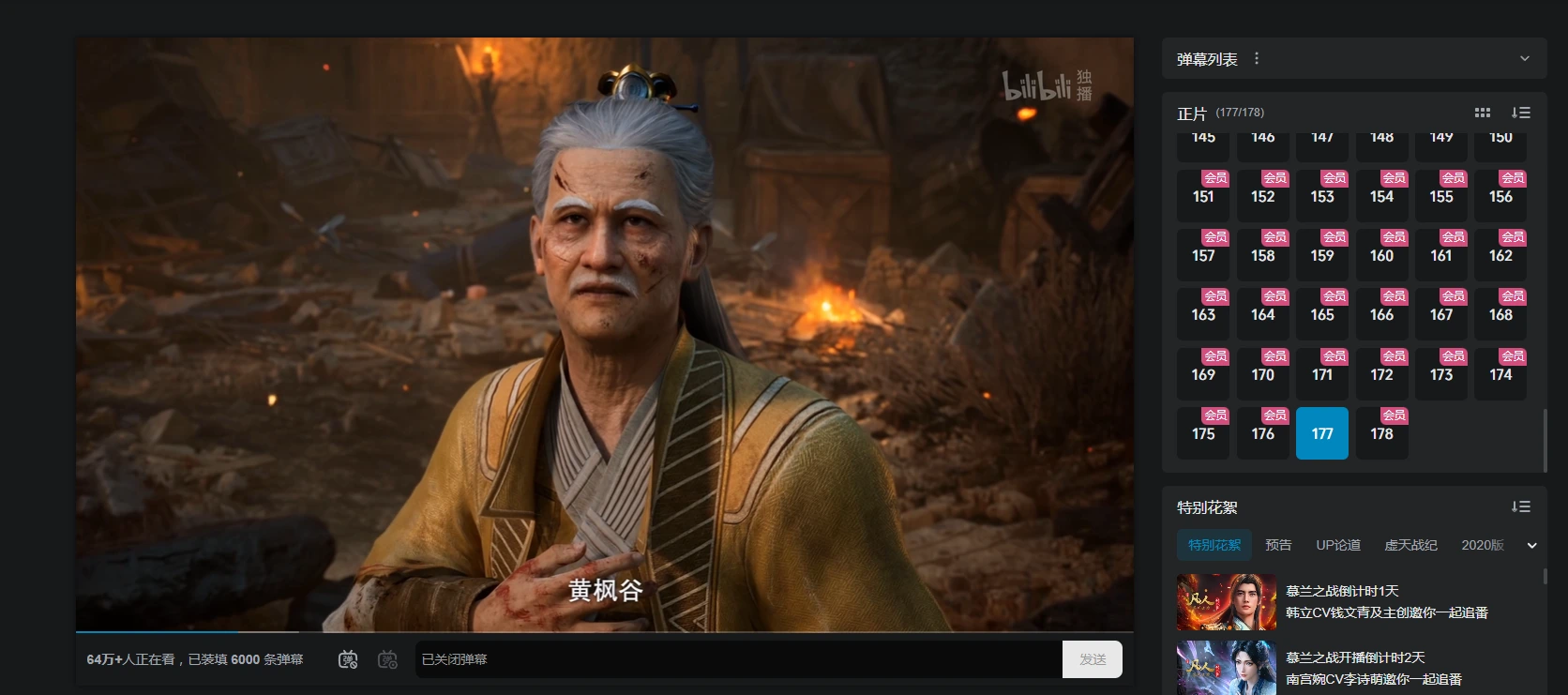
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
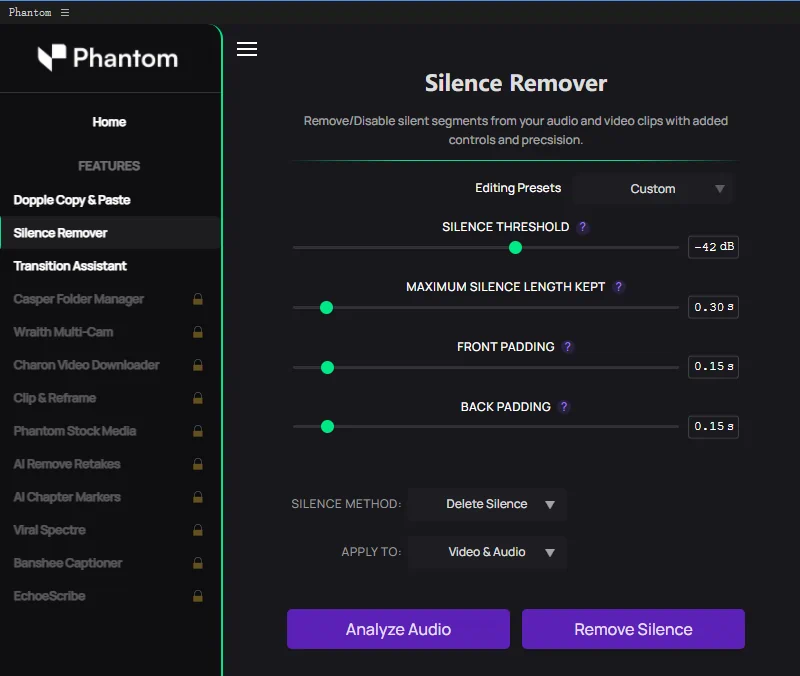
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
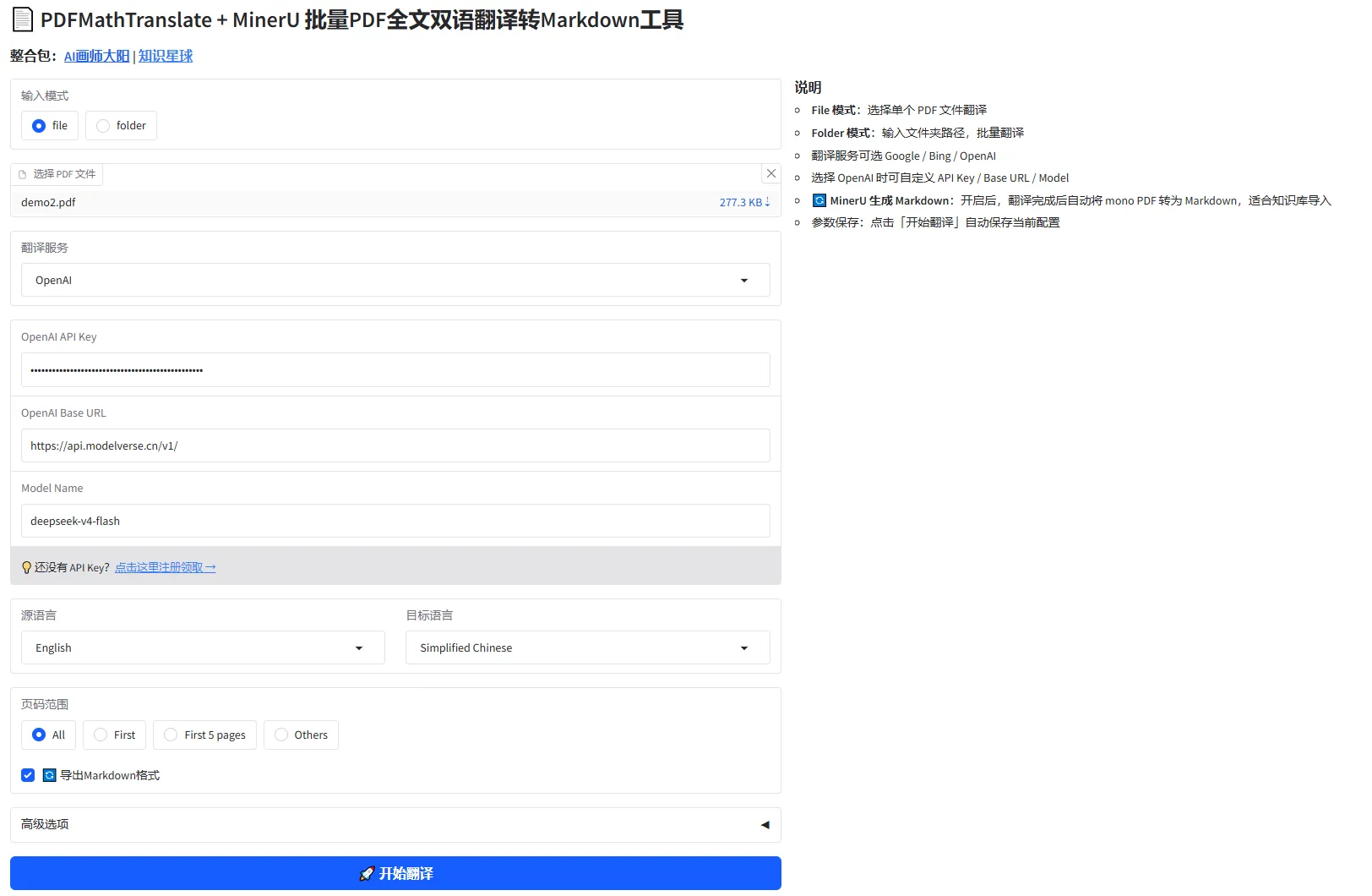
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...