windows系统原生环境下运行openclaw多少还是会遇到点问题,虽然windows原生环境支持使用,但是WSL2仍是官方最推荐的方式。下面是windows系统电脑安装WSL2及OpenClaw详细教程。
安装 WSL2
以管理员身份打开 Windows 上的 PowerShell(右键开始菜单 -> Windows PowerShell (管理员)),输入以下命令:
wsl --install这会自动安装 WSL2 和默认的 Ubuntu 发行版。系统提示需要重启电脑,我们重启电脑。
重启电脑后,打开开始菜单,找到 Ubuntu 应用,点击打开它,等待几分钟初始化。
系统会提示你创建一个UNIX username用户名,随便填
然后会让你输入密码,输入密码时,不会显示,输入完成后按键盘回车
提示重复输入新密码,输入,回车继续,创建完成,然后就会进入等待输入状态。
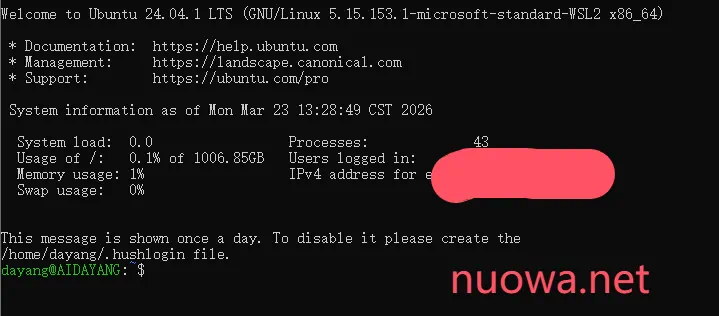
在终端里输入以下命令,确保系统是最新的:
sudo apt update && sudo apt upgrade -y更新时会提示要输入密码,先输入密码确认,然后开始自动更新。
安装OpenClaw
先安装 Node.js,在 Ubuntu 终端里依次运行下面命令:
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash -
sudo apt install -y nodejs
安装浏览器,如果不做浏览器自动化任务的话,可以不用装
npm install playwright
npx playwright install chromium如果在以后执行浏览器自动化任务时报错缺少libXXX.so库,直接运行下面命令自动补全:
npx playwright install-deps安装 OpenClaw
依次运行下面命令安装openclaw,
npm install -g openclaw@latest
openclaw onboard --install-daemon如果上面命令无法安装的话,运行下面官方推荐一键安装命令:
curl -fsSL https://openclaw.ai/install.sh | bash或从 GitHub 主仓库安装实时最新版
npm install -g github:openclaw/openclaw#main如果终端窗口长时间没有变化,打开任务管理器,看看网卡流量,是不是正在下载文件中
如果无法安装的话,先解决你的网络问题。
顺利安装的话,稍后会自动启动引导流程,可以看我另外一篇文章:
《openclaw AI助手windows电脑安装部署及微信聊天配置详细教程》
引导流程配置完成就可以顺利使用了。
如果想要实现开机自动启动的话,下载我写的一个启动脚本startopenclaw.vbs,https://pan.quark.cn/s/c92ff770effd
鼠标右键单击选择编辑,打开脚本文件,修改最后一行代码:
ws.run "wsl -d Ubuntu -- bash -lc '/home/用户名/.npm-global/bin/openclaw gateway > ~/openclaw.log 2>&1'", 0, False把【用户名】这几个字,改成上面安装WSL2时你创建的UNIX username用户名,修改完保存关闭
按电脑win+R键,输入:shell:startup,打开启动文件夹后,把这个vbs文件复制进去即可。每次重启电脑时,Openclaw 网关会自动运行。
我CPU是I7,不处理任务时后台虚拟机进程vmmem占用CPU约0.1%,占用内存约2.4G。
相关推荐





最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
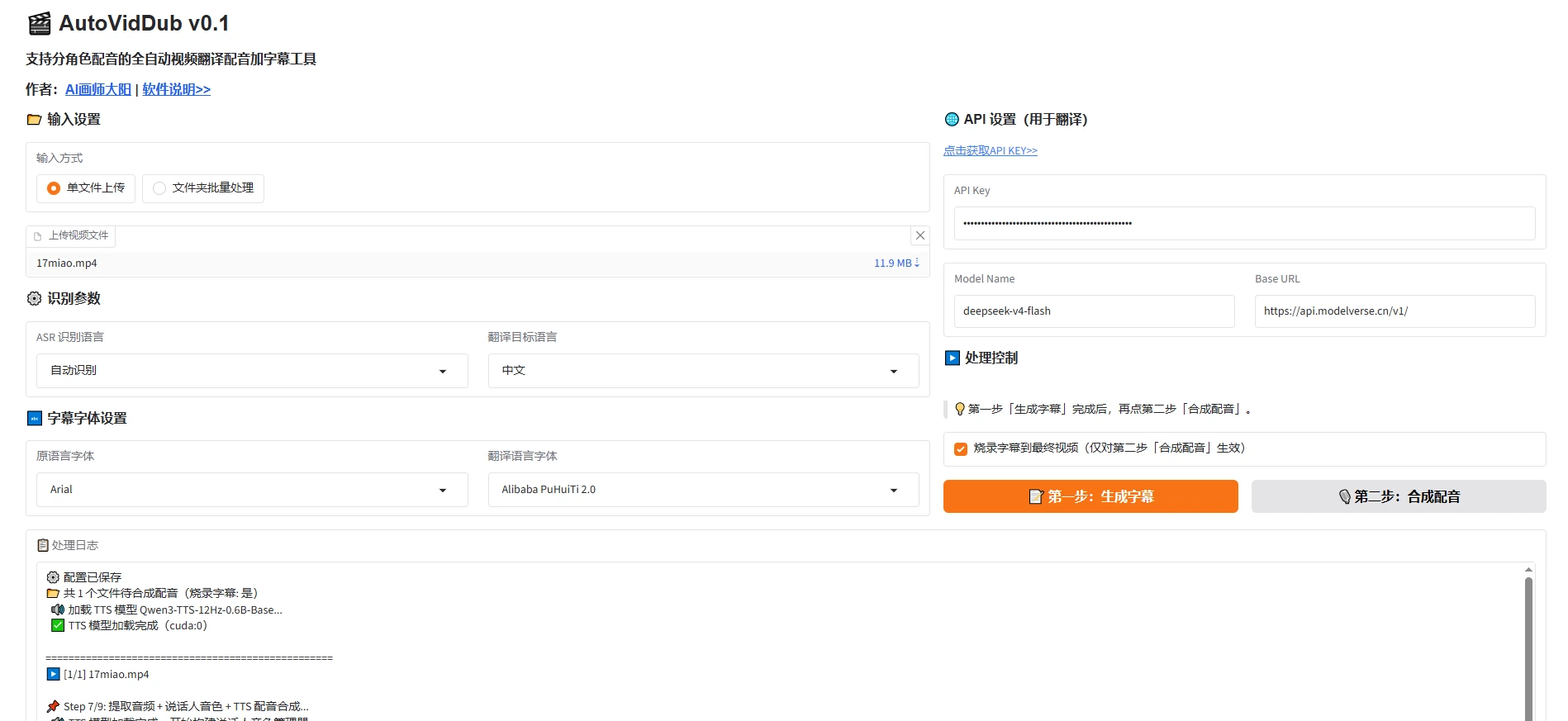
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
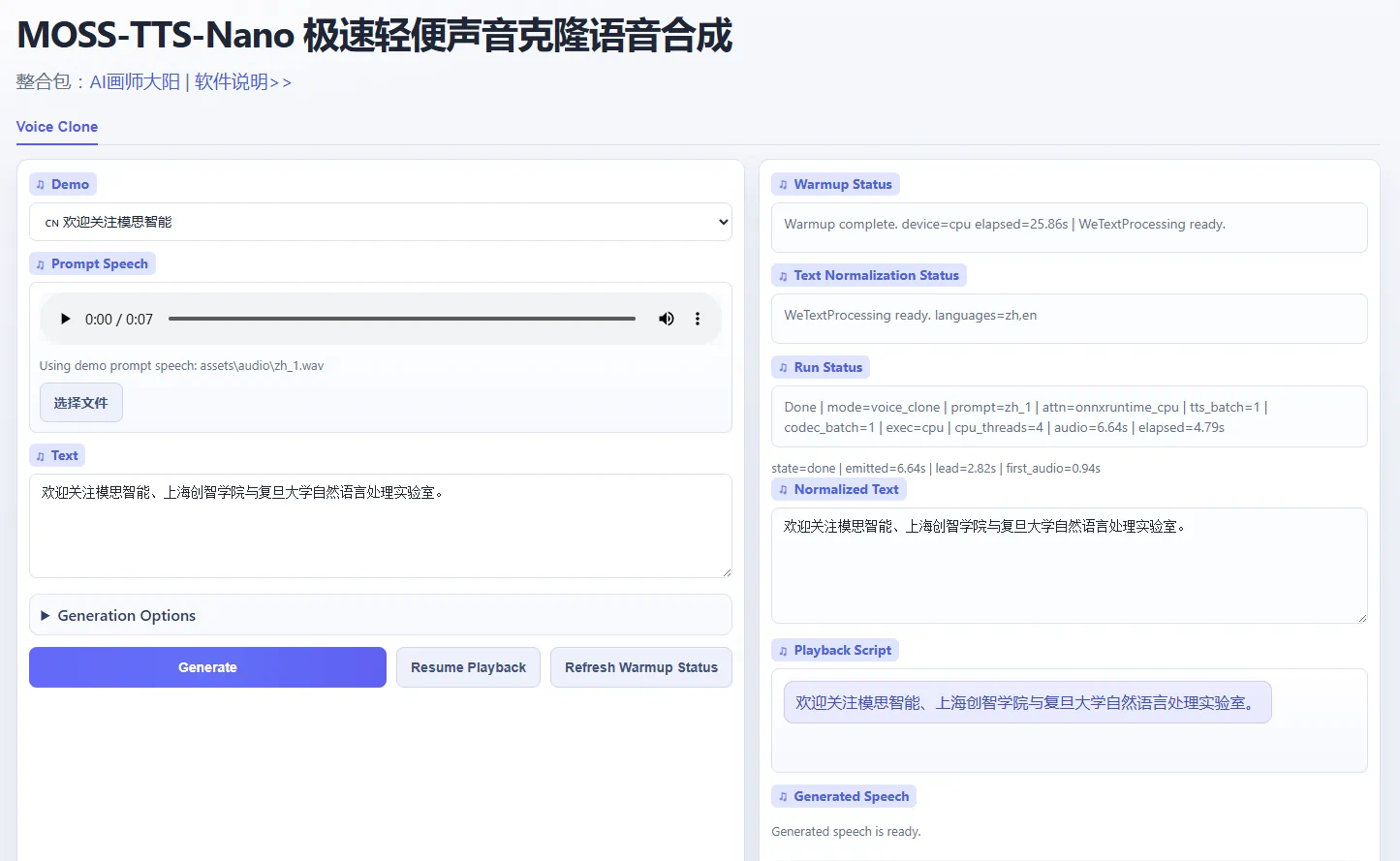
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
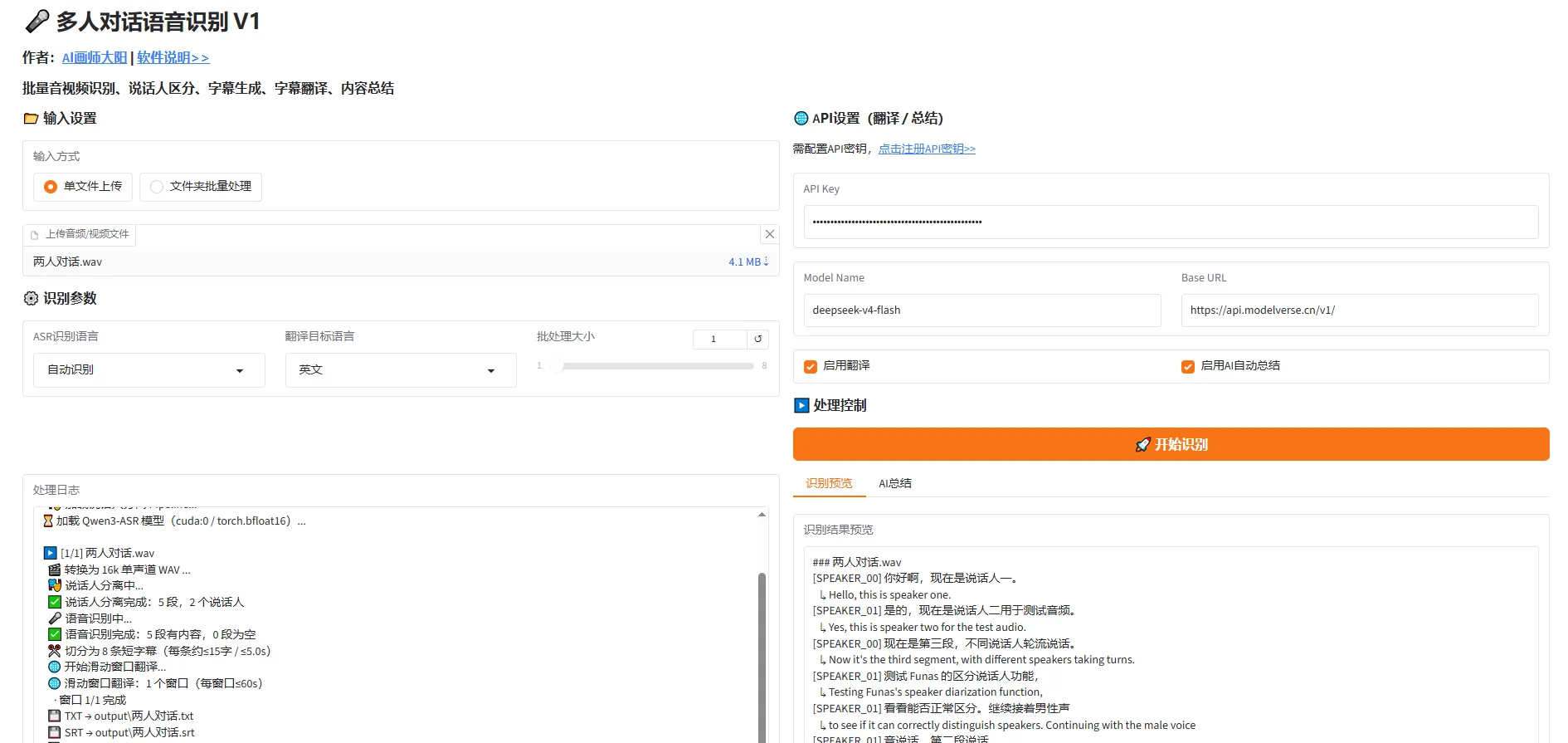
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
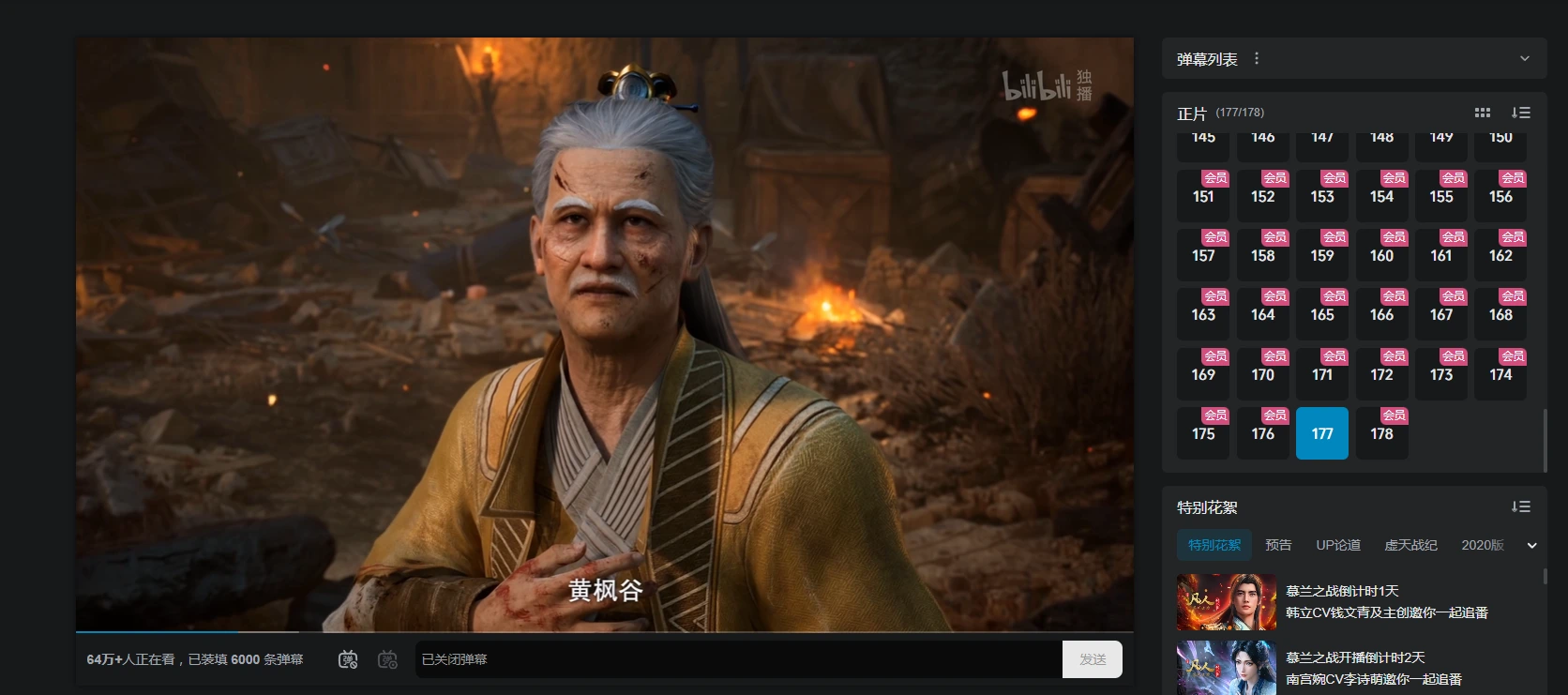
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
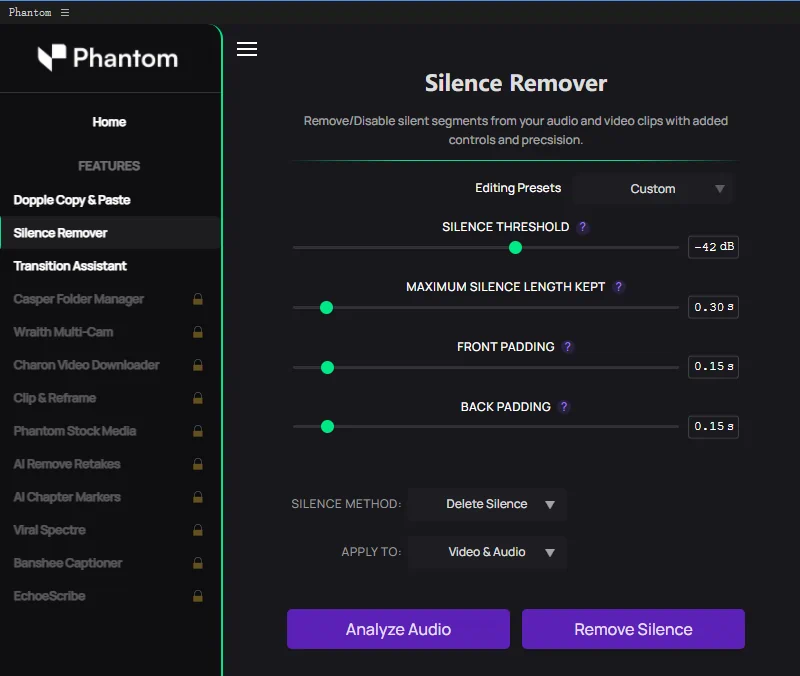
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
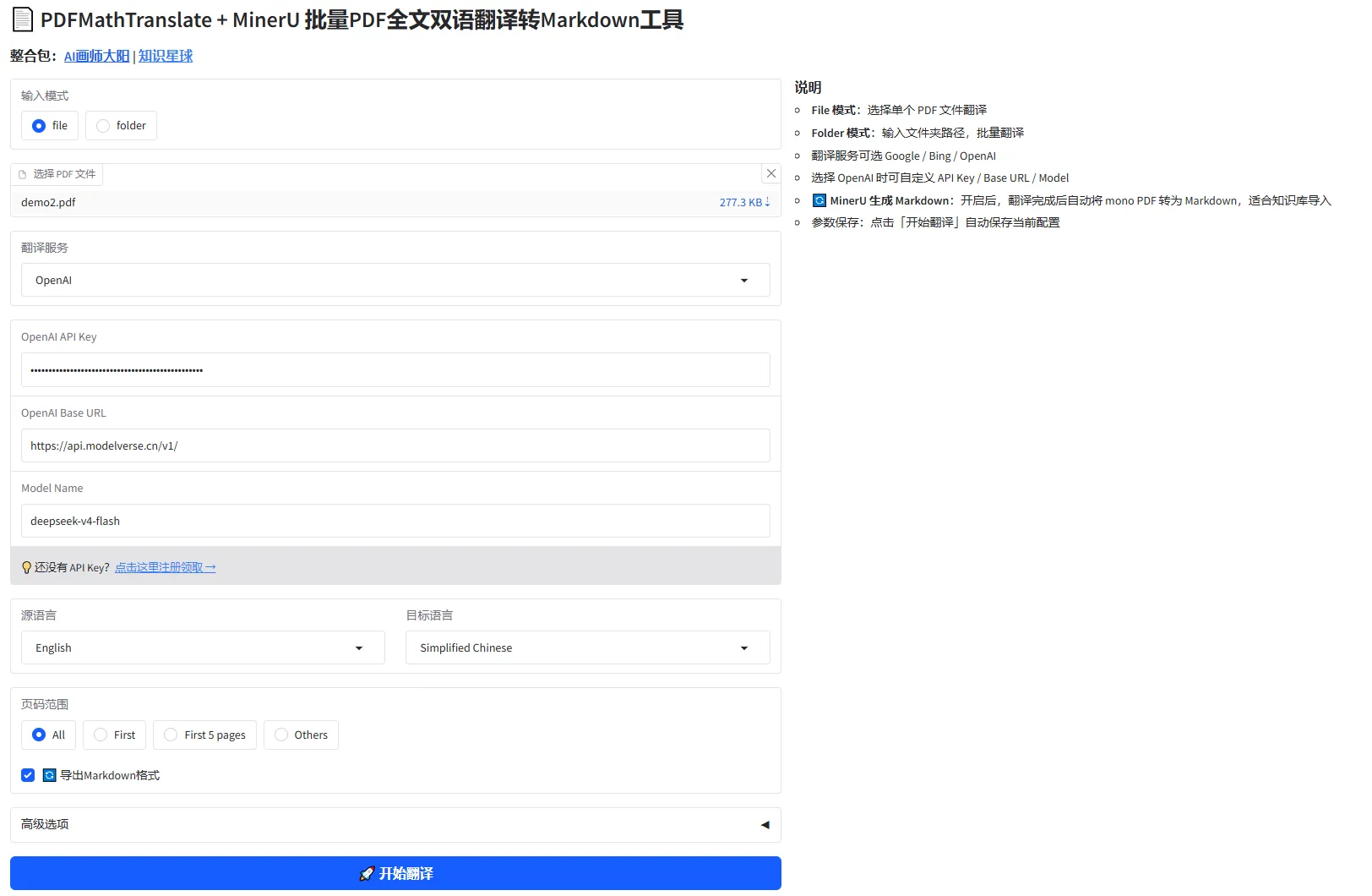
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...