Faster-whisper距离我上次分享已经过去挺长时间了,而且中间也更新了多次了,看到Faster-whisper昨天刚更新了一下,更新内容有模型更新和处理速度大幅提升,更新内容还是挺重要的,我就做了一个最新版本的一键启动包,同时我对整合包功能也做了些修改和优化。
2025-09-02
faster-whisper更新至最新1.2版,新增支持本地ollama大语言模型翻译功能
2026-04-01
源码更新到最新版,重做UI,功能及设置上一些优化
Faster-whisper语音转录工具介绍
faster-whisper是使用CTranslate2对 OpenAI 的 Whisper 模型的重新实现,是 Whisper 的一个优化版本,它是 Transformer 模型的快速推理引擎,用于实现语音识别。此实现比openai/whisper快 4 倍,且精度相同,同时占用的内存更少。在 CPU 和 GPU 上采用 8 位量化,效率可进一步提高。
主要功能
- 语音转录:
- 将语音文件(如 MP3、WAV)转换为文本。
- 支持多语言语音转录。
- 语言检测:
- 自动检测输入音频的语言,无需手动指定语言。
- 分段处理:
- 能够将长音频分成多个片段进行处理,从而提升处理效率和内存利用率。
Faster-whisper特点
- 高效优化:
- 使用 CTranslate2 后端来加速模型推理,显著提升了运行速度。
- 支持 GPU 和 CPU 加速,充分利用硬件资源。
- 轻量化:
- 更小的模型大小和更低的资源需求,适合嵌入式设备或低性能机器。
- 灵活性:
- 允许用户选择不同的模型大小(tiny、base、small、medium、large)以平衡速度和精度。
- 多语言支持:
- 支持 Whisper 所有的多语言模型,适用于不同语言的转录需求。
Faster-whisper更新说明
Faster-whisper最近发布的版本更新内容有如下方面:
1.2.0更新内容
- feat:允许通过特定修订版本进行下载
- 支持
distil-large-v3.5 - 功能:允许通过以下方式加载私有 HF 模型
- 错误修复:通过以下方式恢复时间戳时获取正确的块索引
- 通过批量转录删除静音
1.1.1更新内容
恢复原始 VAD 参数命名
使批量 suppress_tokens 行为与顺序相同
修复 OOM 错误 – VAD 的 RAM 使用率过高
将音频持续时间和 VAD 移除持续时间添加到 BatchedInferencePipeline
修复 neg_threshold
1.1.0新功能
- 新的分批推理速度提高了 4 倍,而且准确度也提高了
- 支持新
large-v3-turbo模型。 - VAD 过滤器现在在 CPU 上的运行速度提高了 3 倍。
- 特征提取速度现在提高了 3 倍。
- 已添加
log_progress到WhisperModel.transcribe打印转录进度。 - 添加了
multilingual转录选项,允许转录多语言音频。请注意,大型模型已经具有代码转换功能,因此这对medium模型或较小的模型最有益。 WhisperModel.detect_language现在可以选择使用 VAD 过滤器,并改进使用language_detection_segments和的语言检测language_detection_threshold。
问题修复
chunk_length在<30 秒时使用正确的特征填充编码器输入seek在输出中使用正确的值
Faster-whisper整合包使用说明
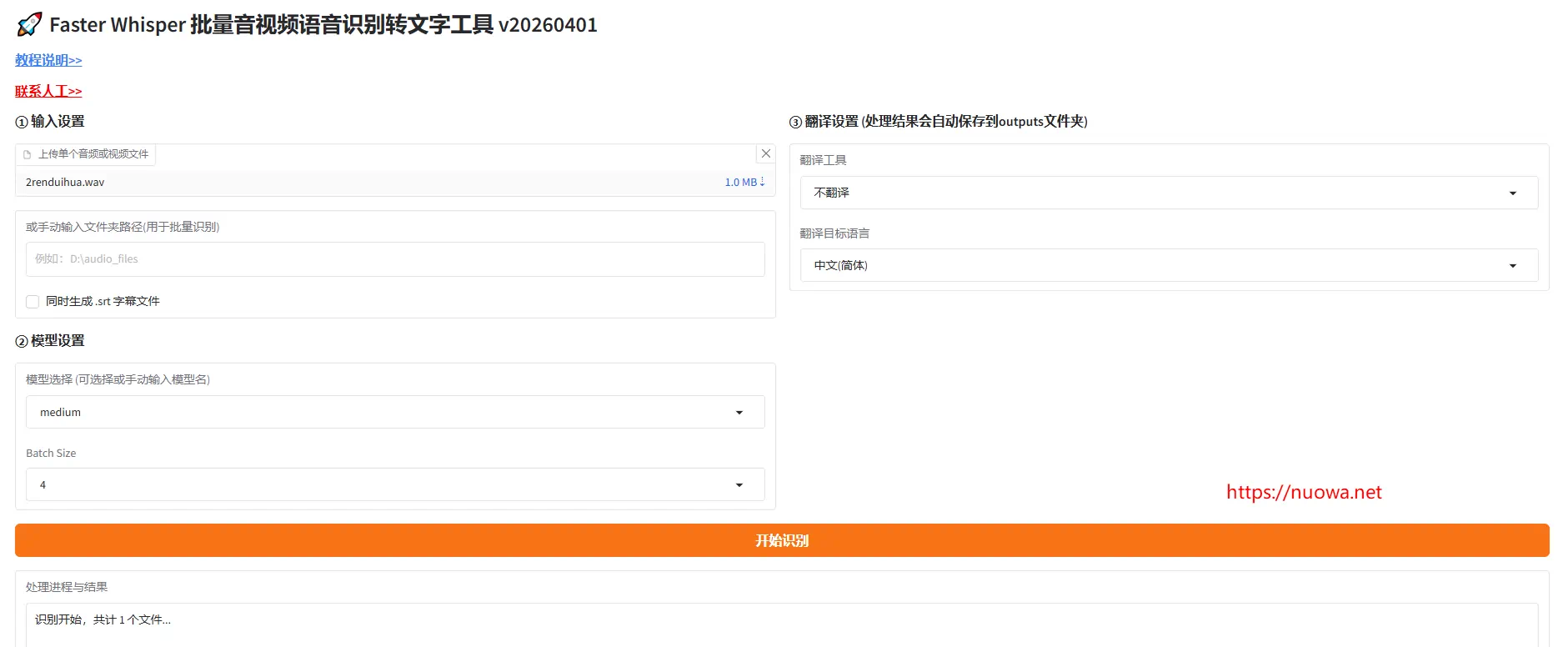
首先将网盘内的压缩包下载到电脑解压出来,然后运行【启动软件.bat】。软件支持处理多种格式音视频文件,格式如下:"*.mp3", "*.wav", "*.flac", "*.aac", "*.m4a", "*.mp4", "*.mkv", "*.avi", "*.mov"
。也支持批量处理。可以将需要处理的音视频文件鼠标左键按住拖动到软件窗口中。或是在输入框内输入需要批量处理的文件夹。
选择模型:默认使用的medium模型,如果你感觉识别效果不满意的话可以使用更大的模型,模型越大识别越精准,但是对电脑配置要求也越高。
选择其它模型软件会自动下载模型文件,如果你无法访问huggingface的话,就无法自动下载模型文件,可以到我网盘内【models】文件夹内手动下载模型压缩包文件到本地电脑项目文件夹【models】内解压,解压后的文件夹路径参考:
faster-whisper20260331–>models–>large-v3–>model.bin
文件夹不要有多余的嵌套,否则无法识别文件
batch size:就是批处理大小,值越大,处理速度越快,但是对电脑配置要求也越高。默认值为4,相对较小。可以根据你电脑显存使用情况适当调高该值。
翻译工具:如果想要把识别文本翻译成其它语言,可以选择翻译工具进行翻译,可以免费使用bing翻译,不过机器翻译效果略差。你也可以使用大语言模型翻译,不过需要申请API,如果还没有大语言模型API的话,你可以点击立即申请>>
硅基流动模型 Base URL:
https://api.siliconflow.cn/v1/API KEY 填你个人实际API KEY值
Model name填你想要使用的模型名,如:
Pro/MiniMaxAI/MiniMax-M2.5你有其他的deepseek等兼容openai API的都可以
翻译目标语言:想把识别出的文本翻译成什么语言的文本
支持识别导出为SRT字幕文件,可按需开启
点击【开始识别】按钮后软件就会开始处理选定的内容,识别结果保存在项目文件夹内的outputs文件夹内。
软件处理过程为本地电脑处理,如果不需要下载模型文件的话,可离线使用本软件
整合包更新内容:
相对于我分享的上个整合包,本次分享的整合包版本有了多处升级。
1、新增批量处理功能,直接选择文件夹,软件就会处理文件夹内的所有音视频文件。仅是MP4格式视频和音频类型文件,不要有其它类型文件。
2、新增batch size和计算精度选项,对高配电脑更加友好,处理效率更高
3、优化字幕生成算法,启用字级时间戳,生成的字幕更准确更友好。
4、增加对最新模型large-v3-turbo模型的支持
5、其它细节上的一些优化。
注意事项
整合包只支持Windows 10或11
软件运行路径中不要有非英文字符和空格
支持英伟达50X系列显卡,使用前请先将英伟达显卡驱动更新到最新版本,否则可能会报错
语音发音不标准、音频声音不干净等原因可能会导致输出繁体中文,可尝试更换更大的模型
如果选择处理文件夹,文件夹内不要有音频、视频以外的文件类型
本软件建议用于英文等外国语言识别,如果识别中文建议使用另一款:https://nuowa.net/721
语音识别转文字软件faster-whisper一键启动包下载链接
在线一键启动
相关推荐
 FunASR语音识别转文字软件区分说话人版
FunASR语音识别转文字软件区分说话人版- FunASR最新模型FunAudioLLM/Fun-ASR-Nano-2512实时语音识别转文字热词版整合包下载
- 麦克风电脑内播放声音实时识别转文字软件FunASR整合包V5下载
- 离线语音识别转文字软件Faster-whisper整合包使用说明视频教程
- 最好用的免费中文音频视频语音识别转文字软件FunASR V3版,批量音视频录音转文字提取工具下载
- 免费音频视频语音识别转文字软件SenseVoice整合包,支持批量操作可生成字幕
- 免费语音识别转文字软件faster-whisper整合包下载,音频视频文字提取工具
- 语音识别转文字软件免费下载,音频视频文字提取工具whisper一键整合包下载,openai语音转文本技术




最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
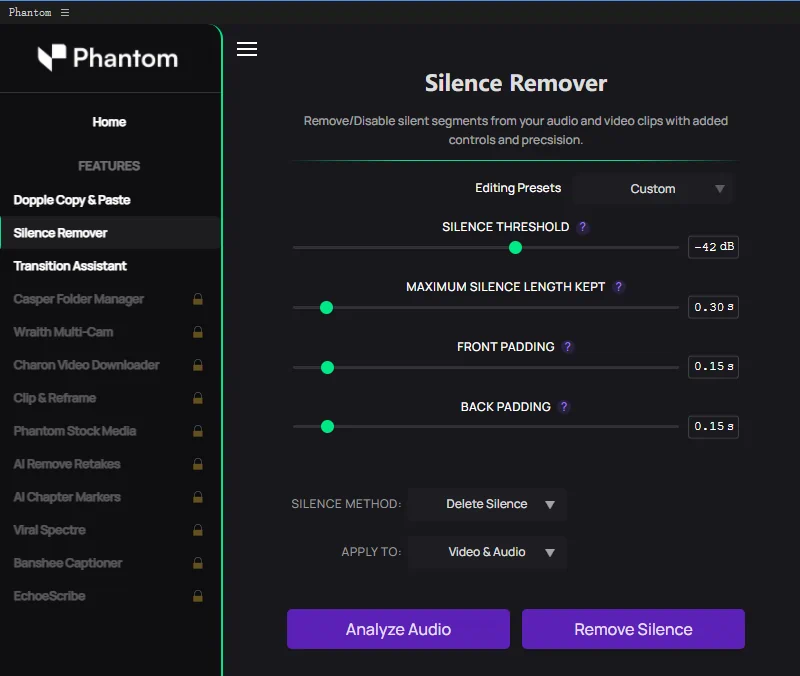
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
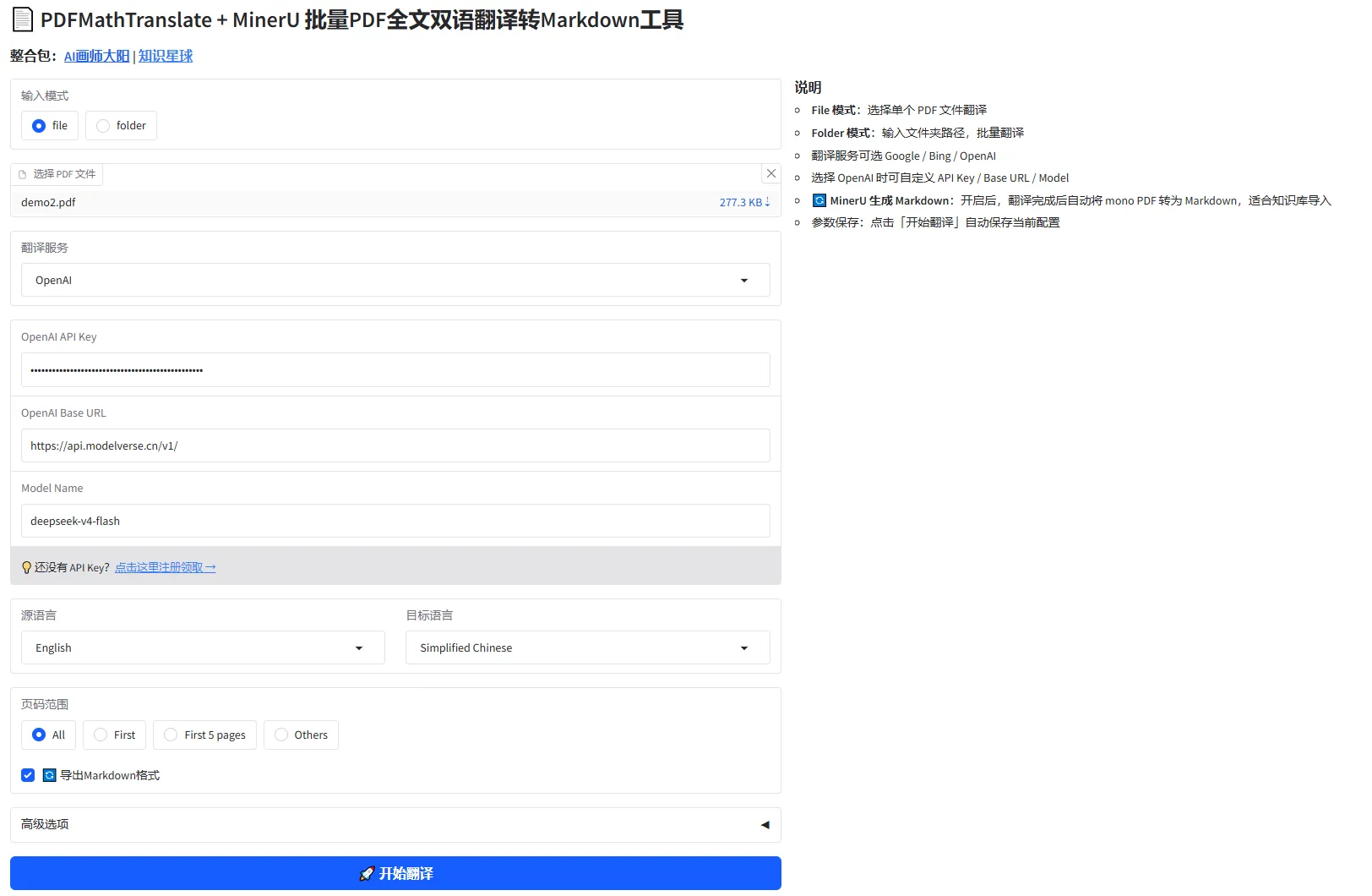
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...