MinerU是一款免费开源的PDF转Markdown格式软件,从MinerU软件刚开始发布我就和大家分享了,到现在很多人在用这款软件,而且MinerU功能也越来越强大,前天MinerU又将版本更新到了0.10.0版,而且更新了比较重要的功能。最近这一个月MinerU更新了4次,很多人都让我更新一下整合包,今天我做了最新版的MinerU一键启动整合包,大家有用得到PDF转Markdown场景的话,可以下载MinerU试一试。
MinerU介绍
一款用于将PDF转换为Markdown和JSON的高质量工具。开源数据导出工具,将PDF转换成Markdown和JSON格式。
MinerU更新日志
- 2024/11/22 0.10.0 发布。引入混合 OCR 文本提取功能,
- 显著提升密集公式、不规则跨区域、文本以图片表示等复杂文本分布场景的解析性能。
- 兼具文本模式下精准内容提取、速度更快的双重优势,以及OCR模式下更精准的跨度/行区域识别。
- 2024/11/15 发布 0.9.3 版本,集成RapidTable进行表格识别,单表解析速度提升10倍以上,准确率更高,GPU内存占用更低。
- 2024/11/06 0.9.2 发布。集成StructTable-InternVL2-1B模型,实现表格识别功能。
- 2024/10/31 0.9.0 发布。这是一个重要的新版本,进行了广泛的代码重构,解决了许多问题,提高了性能,降低了硬件要求并增强了可用性:
- 重构sorting模块代码,使用layoutreader进行读取顺序排序,保证在各种布局下都有较高的准确率。
- 重构段落拼接模块,在跨列、跨页、跨图、跨表的场景下达到良好效果。
- 重构列表及目录识别功能,大幅提升列表块和目录块的准确率以及对应文本段落的解析。
- 重构图表、表格及说明性文字的匹配逻辑,大幅提升图表图注及脚注匹配准确率,说明性文字的丢失率接近于零。
- 增加OCR多语言支持,支持84种语言的检测和识别。支持语言列表请参见OCR语言支持列表。
- 增加内存回收逻辑等内存优化措施,大幅降低内存占用,除表格加速(布局/公式/OCR)外所有加速特性开启内存需求由16GB降低至8GB,所有加速特性开启内存需求由24GB降低至10GB。
- 优化配置文件功能开关,增加独立公式检测开关,在不需要公式检测的情况下,大幅提升速度和解析结果。
- 集成PDF-Extract-Kit 1.0:
- 增加了自主研发的模型,在保持解析效果相似的前提下,处理速度比原方案提高10倍以上,并可通过配置文件
doclayout_yolo自由切换。layoutlmv3 - 公式解析升级为
unimernet 0.2.1,提高公式解析准确率的同时大幅降低内存占用。 - 由于 的仓库变更
PDF-Extract-Kit 1.0,您需要重新下载模型。详细步骤请参阅如何下载模型。
- 增加了自主研发的模型,在保持解析效果相似的前提下,处理速度比原方案提高10倍以上,并可通过配置文件
MinerU主要特点
- 删除页眉、页脚、脚注、页码等,以确保语义一致性。
- 以人类可读的顺序输出文本,适用于单列、多列和复杂布局。
- 保留原始文档的结构,包括标题、段落、列表等。
- 提取图像、图像描述、表格、表格标题和脚注。
- 自动识别文档中的公式并转换为 LaTeX 格式。
- 自动识别文档中的表格并转换为HTML格式。
- 自动检测扫描的 PDF 和乱码 PDF 并启用 OCR 功能。
- OCR支持84种语言的检测和识别。
- 支持多种输出格式,如多模式和 NLP Markdown、按阅读顺序排序的 JSON 以及丰富的中间格式。
- 支持多种可视化结果,包括布局可视化、跨度可视化,可有效确认输出质量。
- 支持 CPU 和 GPU 环境。
- 兼容 Windows、Linux 和 Mac 平台。
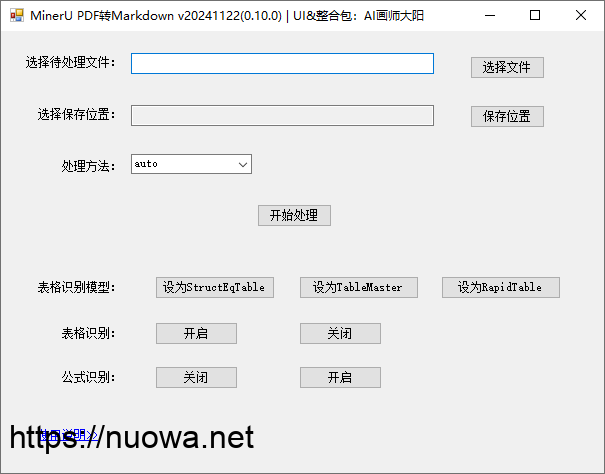
MinerU一键启动整合包使用说明:
首先到我网盘里将主程序压缩包MinerU_20241124.7z下载到电脑上解压,然后将模型文件PDF-Extract-Kit-1.0.7z下载到MinerU_20241124文件夹内并解压,这个最新版本和以前分享的老版本的模型是不兼容的,所以你得下载这个最新版的模型才行。
如果你以前用过MinerU这个软件的话,防止你以前用的版本和最新版本不兼容,先删除C:\Users\你的电脑用户名\magic-pdf.json文件。注意你的电脑用户名不能是中文及特殊字符,最好使用英文字符命名,否则程序会报错。
打开MinerU项目文件夹找到【0启动软件.exe】,双击即可启动应用。
待处理文件一栏里可以是单个PDF文件名,也可以是包含多个PDF文件的文件夹名,可以直接拖动待处理文件或文件夹到程序窗口会自动填入路径输入框。
处理方法有auto,ocr,txt三种方式,ocr:使用ocr技术从pdf中提取信息。txt:仅适用于基于文本的pdf,效果优于ocr。auto:自动从ocr和txt中选择最佳方法解析pdf。如果未指定方法,则默认使用auto。
表格识别模型默认为rapid_table,你也可以改为”tablemaster” 或 “struct_eqtable”
表格识别功能默认是关闭的,开启这个功能的话会比较吃电脑配置,如果你PDF中没有表格的话,那么就不要开启这个功能了。
公式识别功能默认是开启的,如果你的PDF中没有公式的话,那么你可以关闭这个功能,以节省计算量。
最终识别结果在你选择的保存位置文件夹中,程序自动为每个文件夹以文件名命名,其中包含了md,json格式文件,还有提取到的图片等内容,具体可自行查看。
注意事项
软件程序运行路径中请不要有非英文字符及空格
如果PDF文档内容比较复杂,如有很多表格和公式或是PDF文件比较大,处理时间就会比较长,建议将PDF文档用分割工具分割成多个体积较小文档进行处理,每个文档处理时间请在400秒内完成。
使用软件前请先将英伟达显卡驱动更新到最新版本,否则软件会报错显存不足的错误
本整合包软件为Windows电脑版软件,需要有英伟达独立显卡4G或是更高显存,不支持手机和MAC系统。
PDF转Markdown软件MinerU一键启动包v0.10.0下载链接
相关推荐
 PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具- Mineru PDF转markdown软件局域网版
- PDF转Markdown软件MinerU 3.1.11整合包(高性能版)
- 图片/PDF转HTML/Markdown/JSON软件Chandra—— Windows 版一键启动包,免安装部署,可离线
- 字节跳动Dolphin图片文档解析工具免安装一键启动整合包下载,PDF转JSON/Markdown软件
- 一句话编辑图片工具OmniGen2整合包下载,输入文本快速P图
- PDF/图片转markdown软件MonkeyOCR整合包,文档图片解析工具下载
- 微软PDF/WORD/HTML文档转Markdown格式软件markitdown整合包下载


最近更新
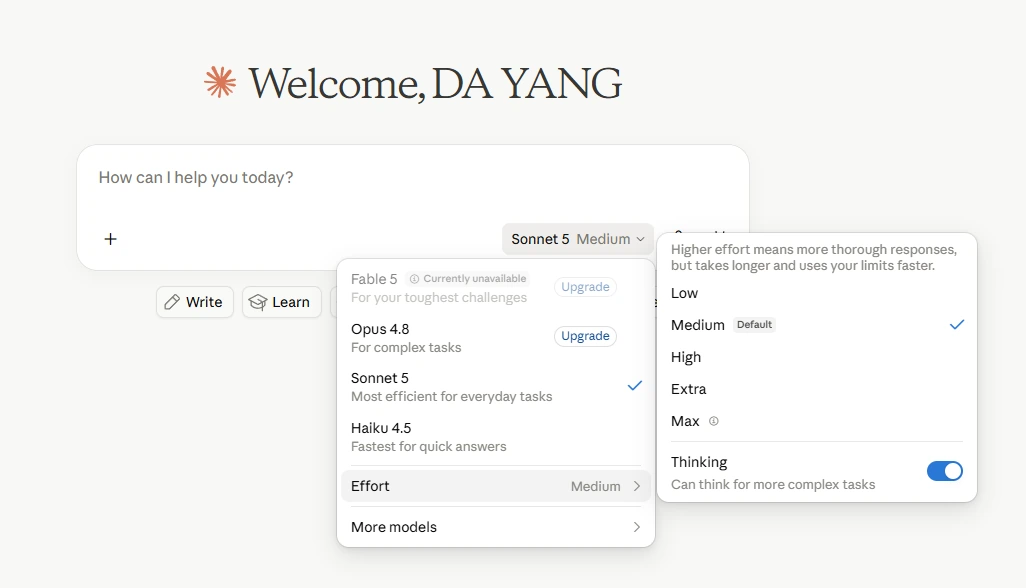
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
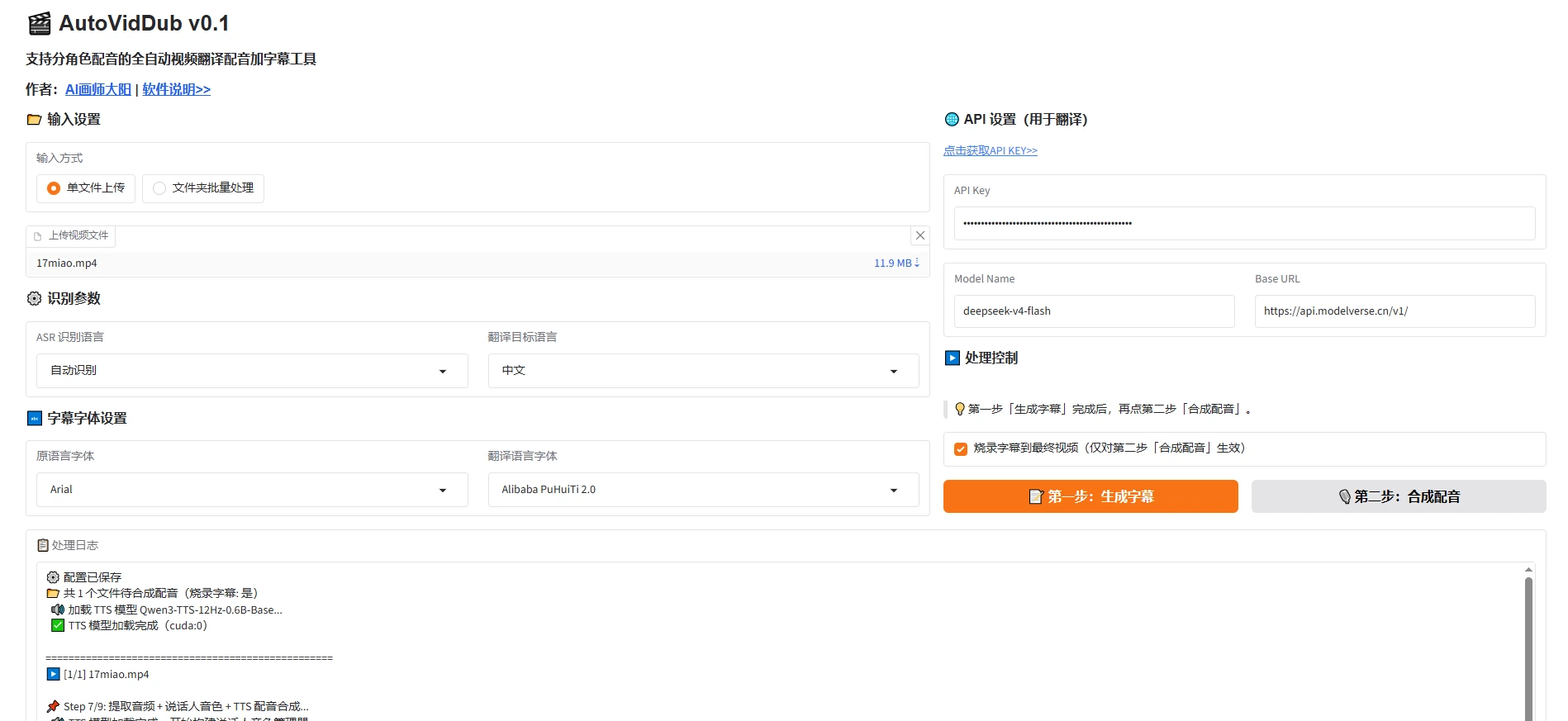
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
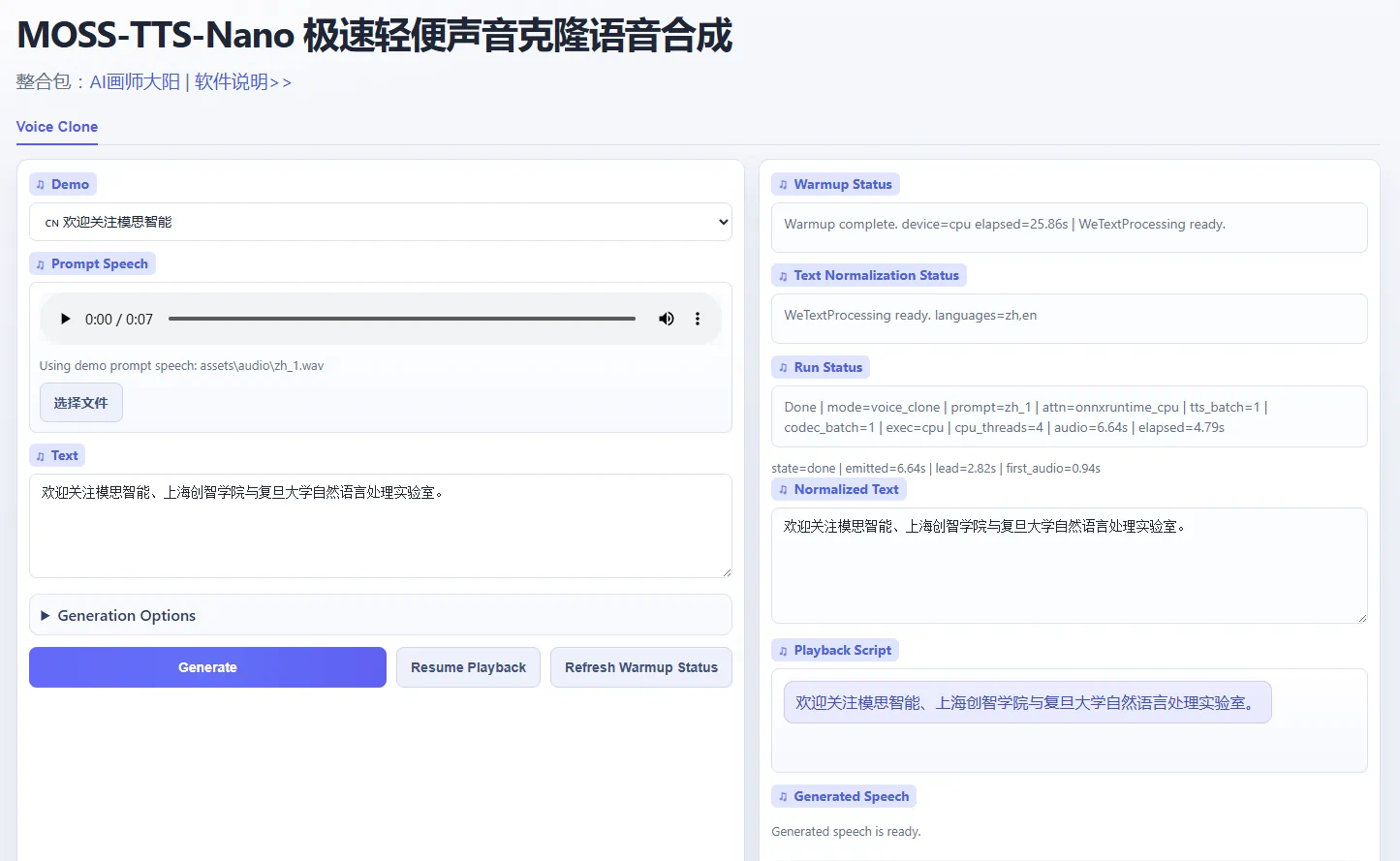
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
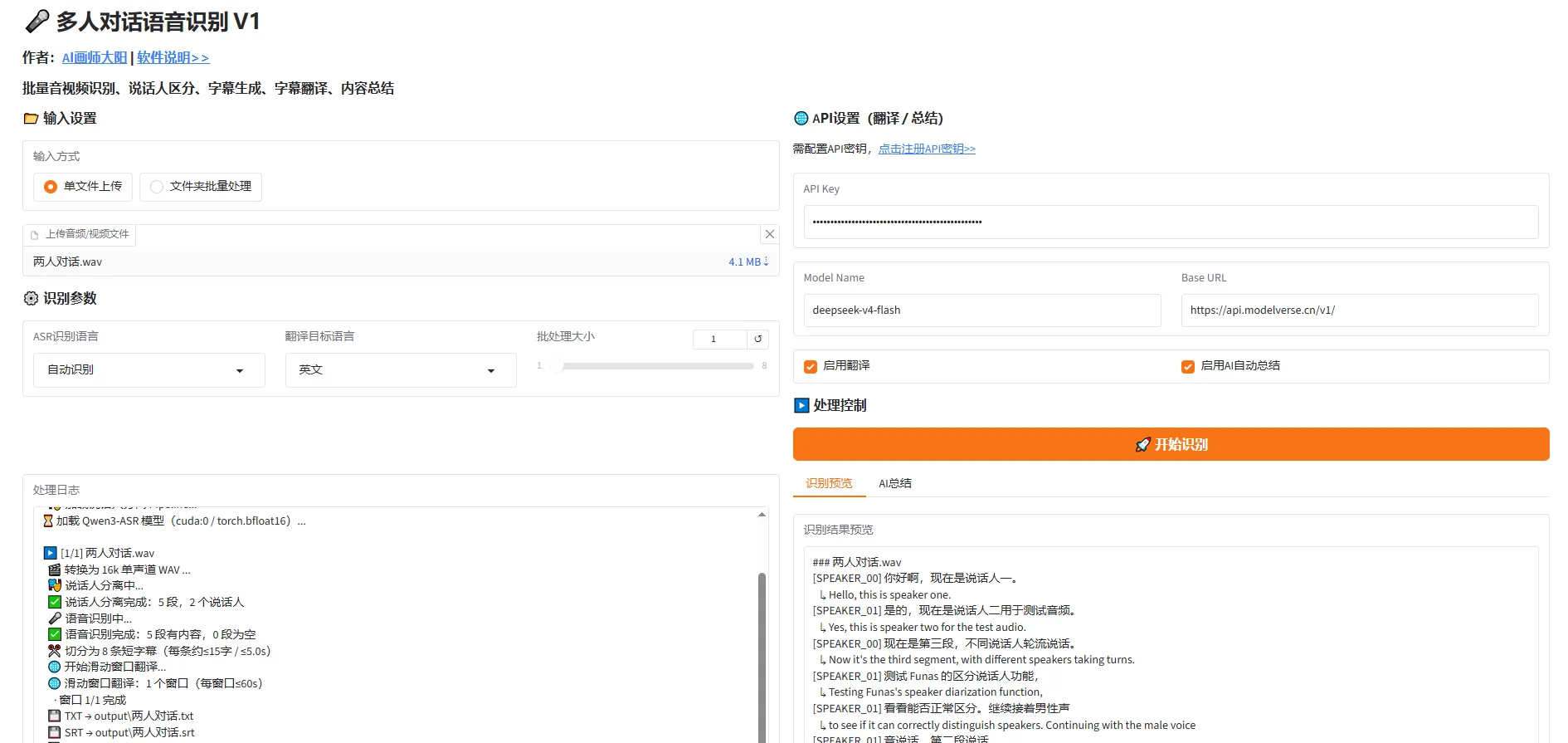
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
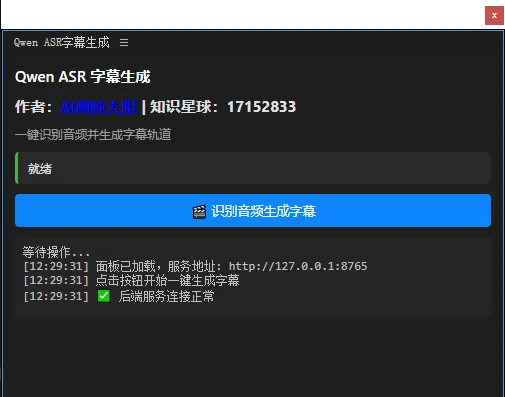
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
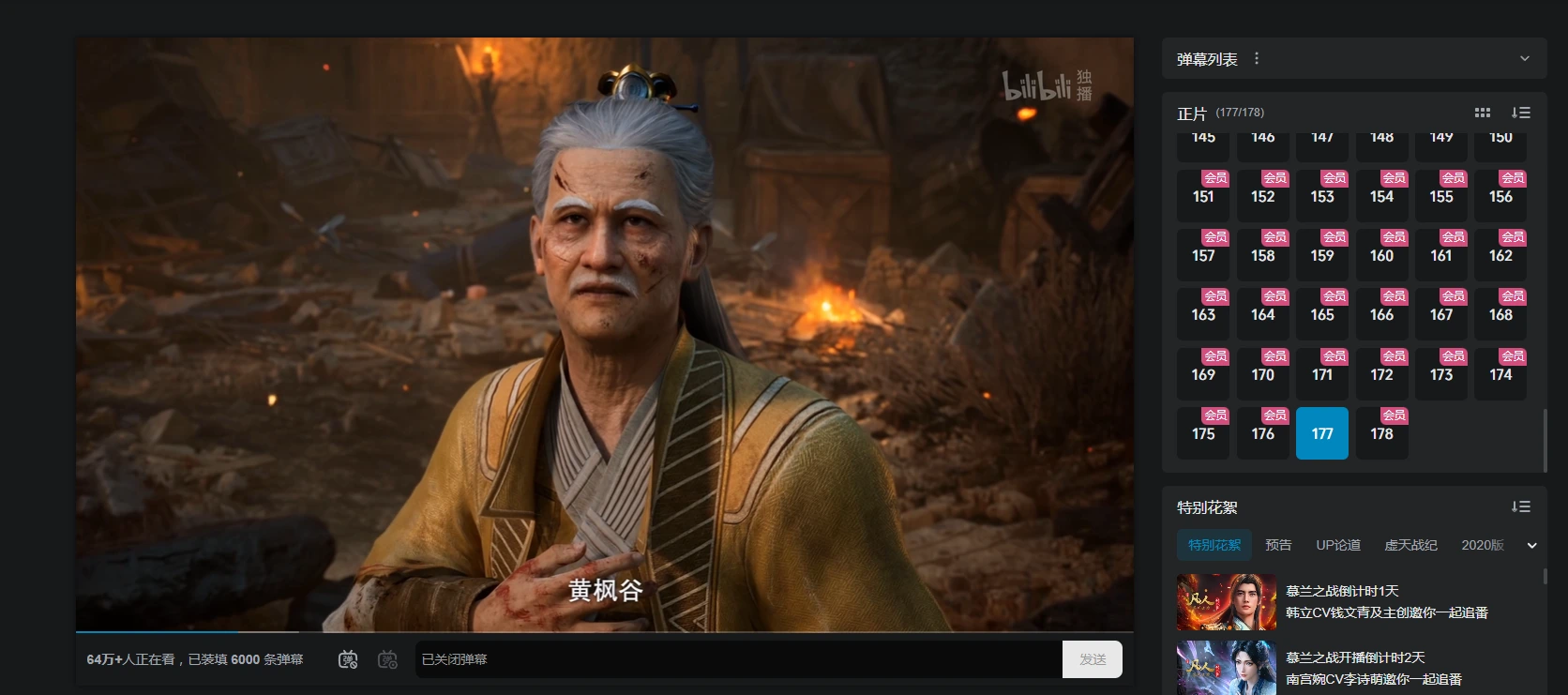
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
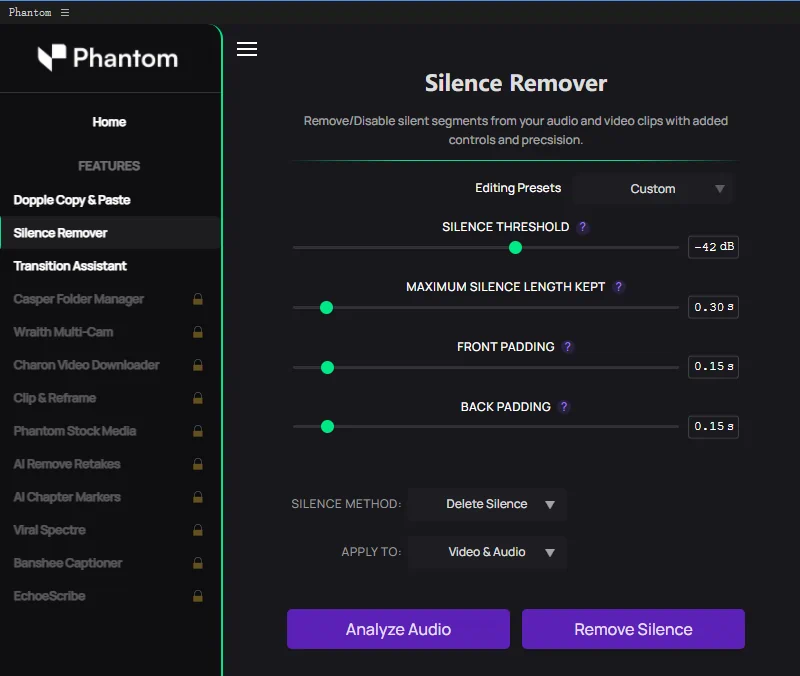
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
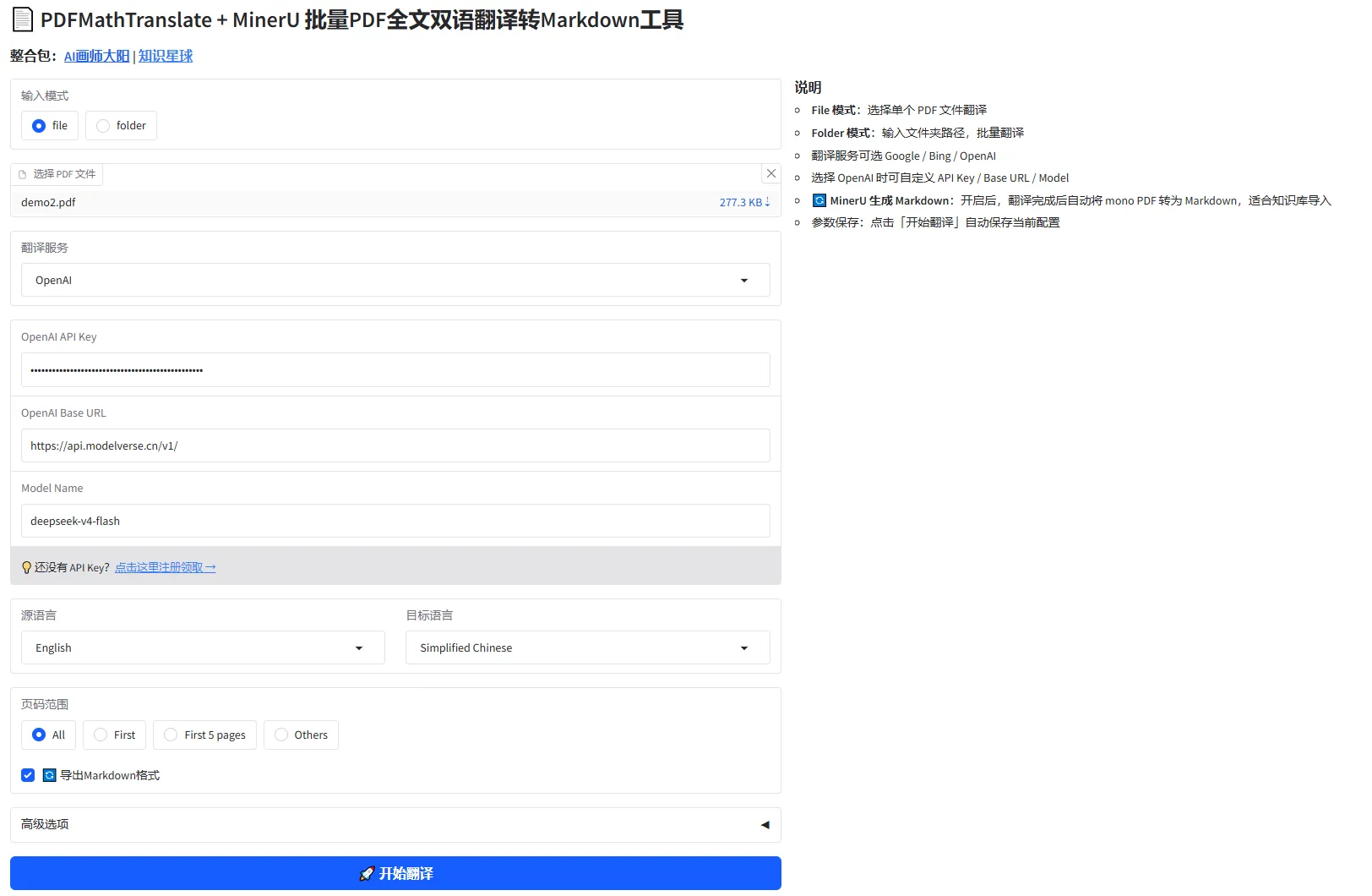
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...