本次和大家分享一个字节跳动开发的强大的音频驱动口型数字人视频制作软件LatentSync,我以前也分享过不少类似软件了,比如:EchoMimic、VideoReTalking、hallo。字节的推出的这个效果稍微更好一点,我制作了最新版的一键启动整合包。
————————————————
2025-03-19更新V1.5版本
2025-06-13更新v1.6版本
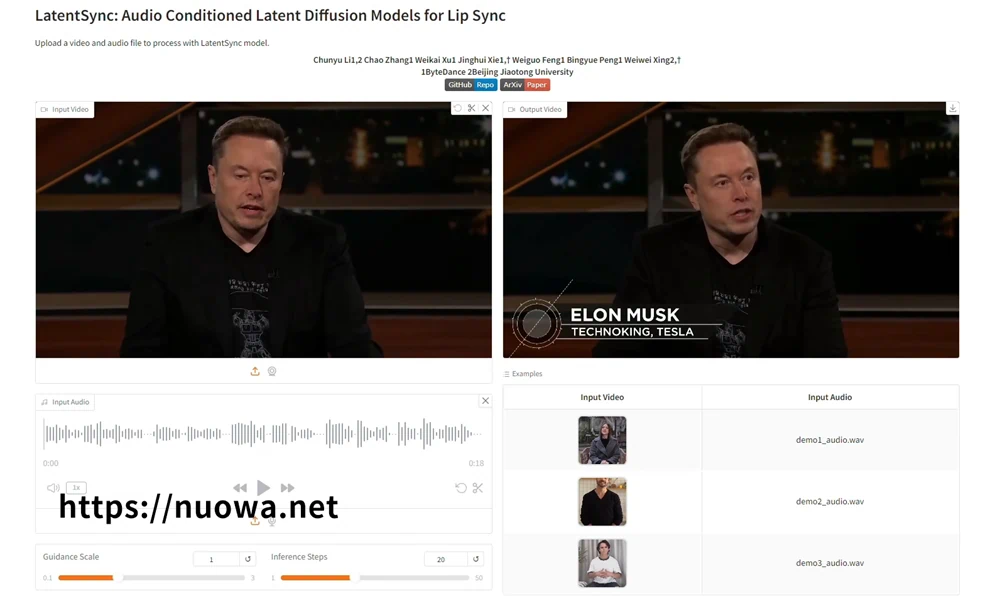
LatentSync官方说明
LatentSync:嘴唇同步的音频条件潜在扩散模型。我们提出了LatentSync,这是一种基于音频条件潜在扩散模型的端到端唇形同步框架,没有任何中间运动表示,与之前基于像素空间扩散或两阶段生成的基于扩散的唇形同步方法不同。我们的框架可以利用Stable Diffusion的强大功能来直接模拟复杂的视听相关性。此外,我们发现基于扩散的唇形同步方法由于不同帧间扩散过程的不一致性而表现出较差的时间一致性。我们提出了时间再现对齐(TREPA)来提高时间一致性,同时保持唇形同步的准确性。TREPA使用由大规模自监督视频模型提取的时间表示来将生成的帧与地面真实帧对齐。
LatentSync使用Whisper将融合频谱图转换为音频嵌入,然后通过交叉注意力层将其集成到U-Net中。参考帧和掩码帧与噪声延迟按信道连接,作为U-Net的输入。在训练过程中,我们使用一步法从预测的噪声中得到估计的干净延迟,然后对其进行解码以获得估计的干净帧。TREPA、LPIPS和SyncNet损耗被添加到像素空间中。
V1.5版本更新说明:
(1)通过添加时间层提高了时间一致性,(2)提高了中文视频的性能,(3)通过一系列优化将stage2训练的VRAM要求降低到20 GB。
V1.6版本更新说明:
它在 512×512 分辨率的视频上训练所得,可以缓解模糊问题。
LatentSync整合包使用说明
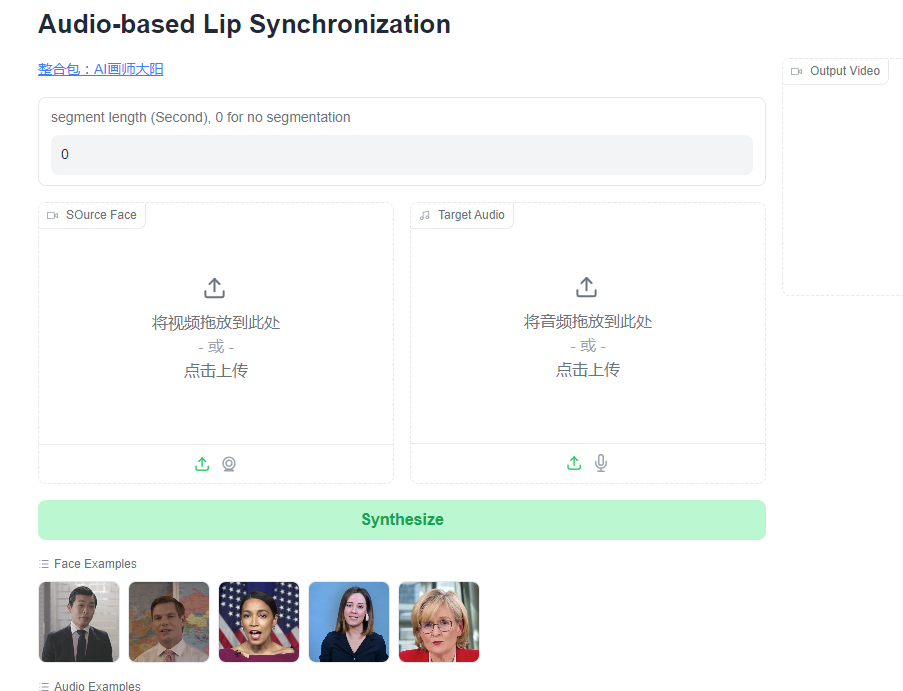
首先将软件压缩包下载到本地电脑并解压,双击【启动软件.exe】,稍等一会加载模型,完成后会自动打开webUI界面。
操作界面比较简单,左上部分上传视频素材,左下部分上传驱动音频,然后点击按钮Process Video即可开始合成视频。所需时间由电脑配置决定,建议英伟达显卡显存4G以上用户使用。
合成完成后右侧可播放视频或下载视频,在软件项目文件夹内的temp文件夹内也可以找到合成视频。
注意事项
使用前先更新英伟达显卡驱动到最新版
如果视频素材和音频素材时长不一致,最终合成视频时长由最短的那个决定。
音频素材末尾最好增加0.5到1秒的静音片段,以防最终视频结尾不完整。
整合包只支持Windows 10或11系统
软件运行路径中不要有非英文字符和空格
支持英伟达50系列显卡
1.0版本电脑英伟达显存不低于6G
1.5版本电脑英伟达显存不低于8G,支持RTX50系列
1.6版本电脑英伟达显存不低于12G,支持RTX50系列
数字人视频制作对口型软件LatentSync本地整合包下载链接
在线一键启动链接
数字人对口型软件LatentSync本地电脑安装部署教程
相关推荐
 无限长度的数字人对话视频生成软件InfiniteTalk整合包,图像转视频、视频配音对口型工具
无限长度的数字人对话视频生成软件InfiniteTalk整合包,图像转视频、视频配音对口型工具- 音频驱动口型超逼真数字人视频制作软件Sonic整合包下载
- 字节跳动唇形同步数字人视频制作软件LatentSync整合包使用说明视频教程
- 图片数字人视频制作软件LivePortrait整合包下载,图片转视频动物人物表情转移工具
- 超强AI数字人EchoMimicV2一张半身照片即可生成一段主播解说视频,整合包下载
- 音频驱动口型数字人视频制作软件VideoReTalking整合包,音频视频人物对口型
- 音频驱动数字人视频制作EchoMimic整合包,免费让照片图片开口说话的软件
- 音频驱动口型生成视频软件video-retalking整合包免费下载,基于音频的唇形同步工具




最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
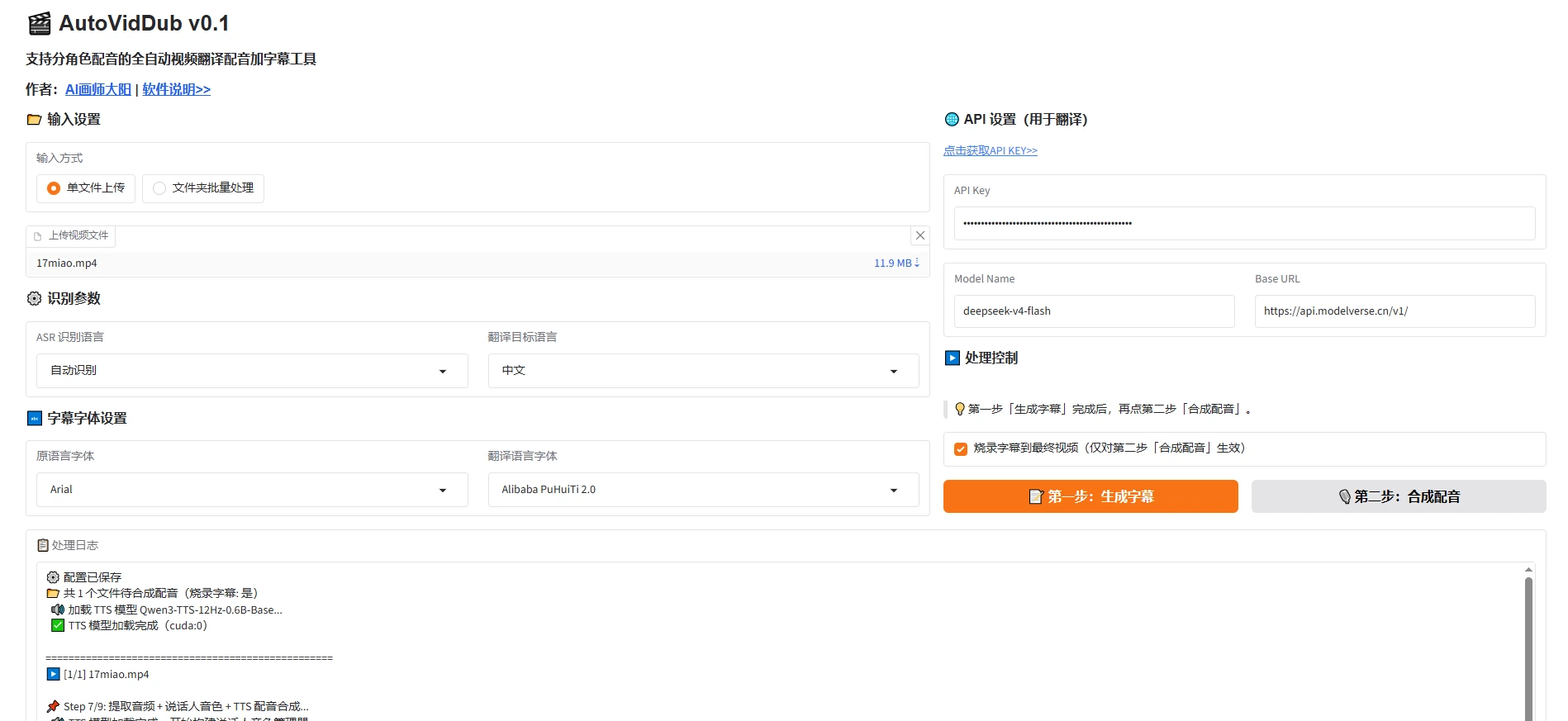
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
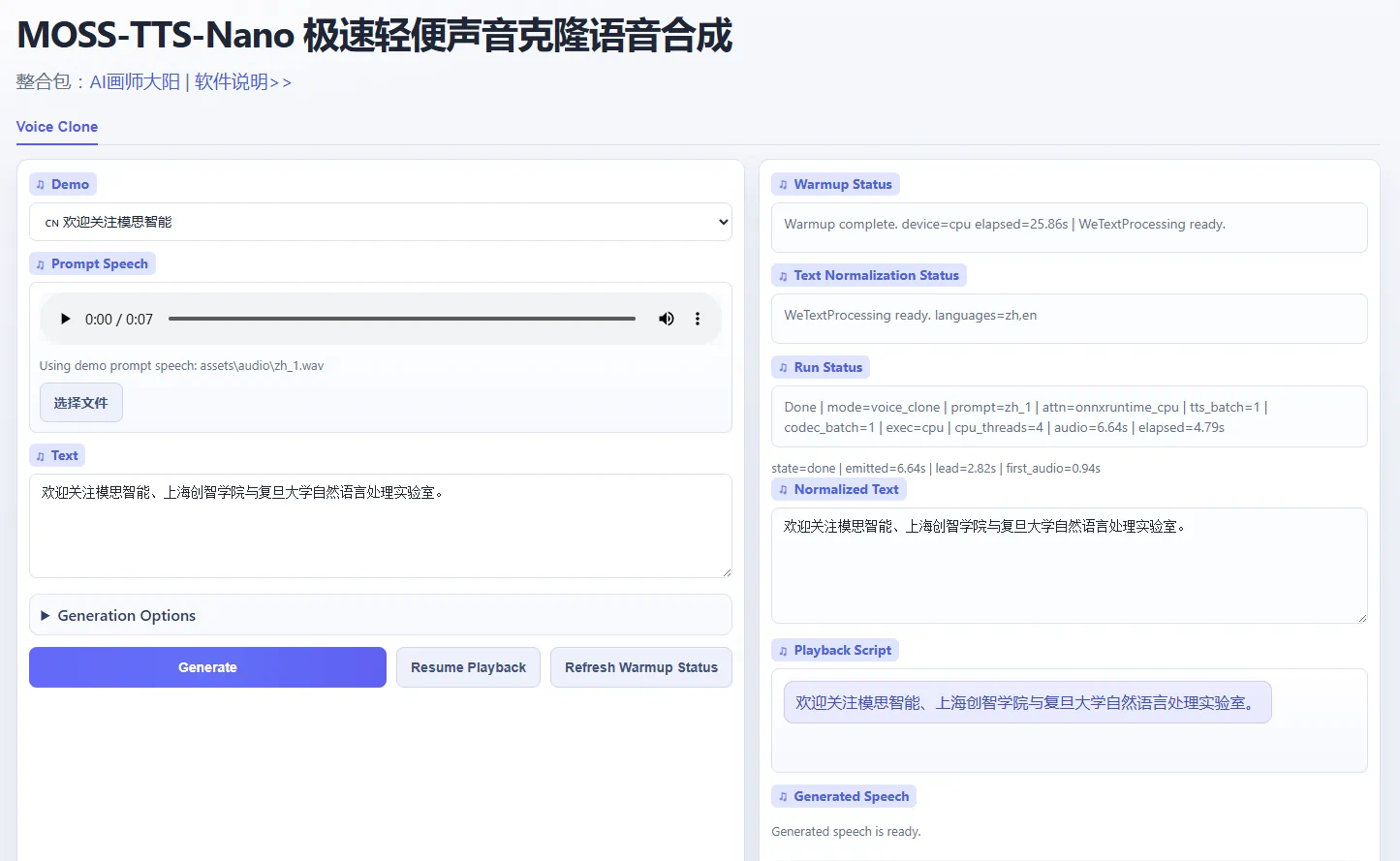
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
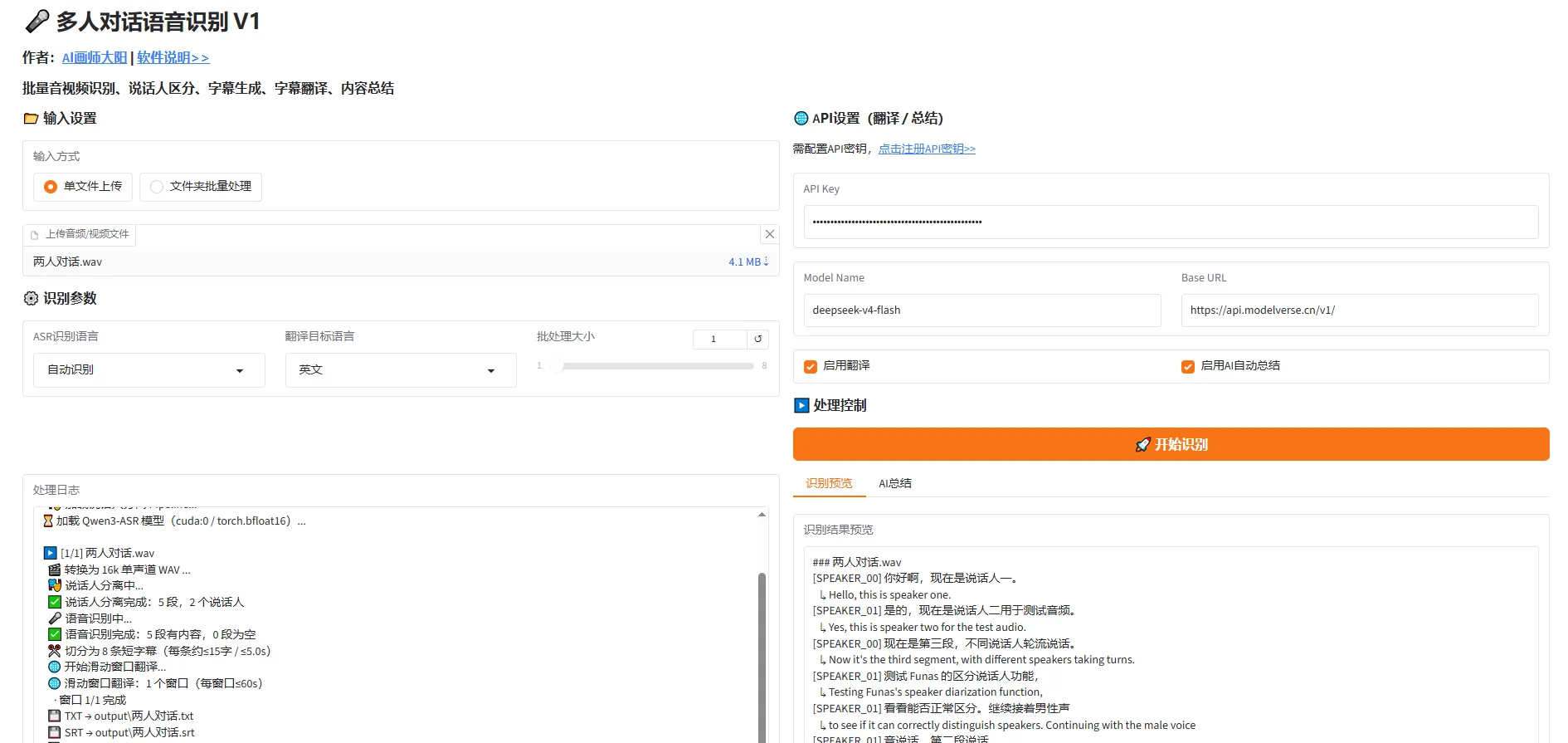
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
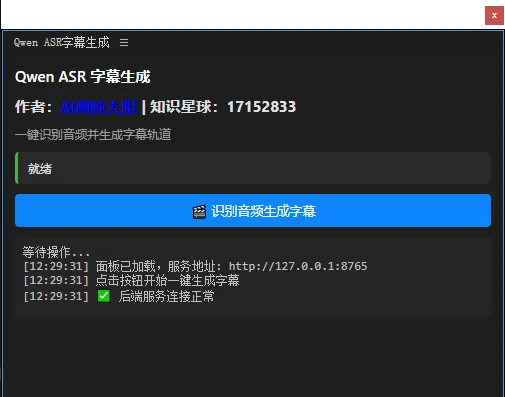
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
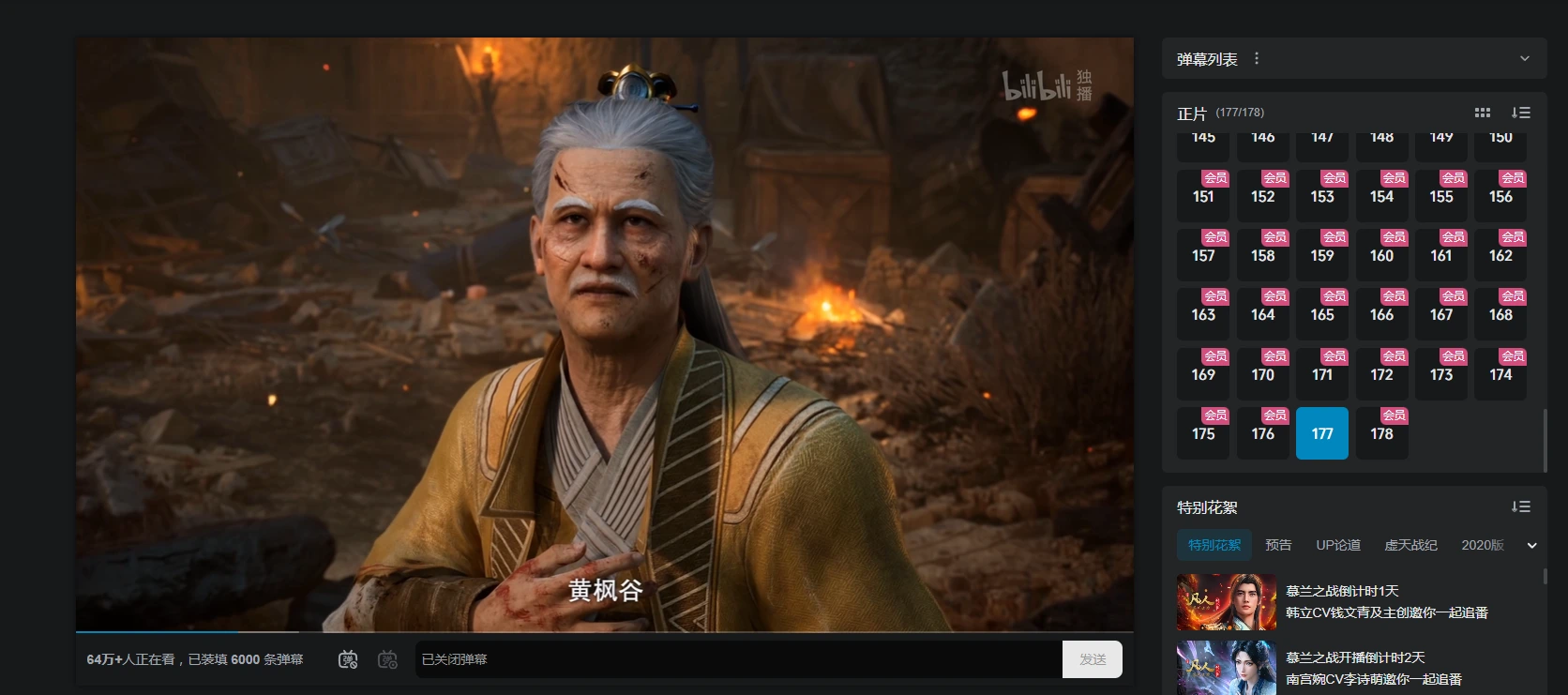
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
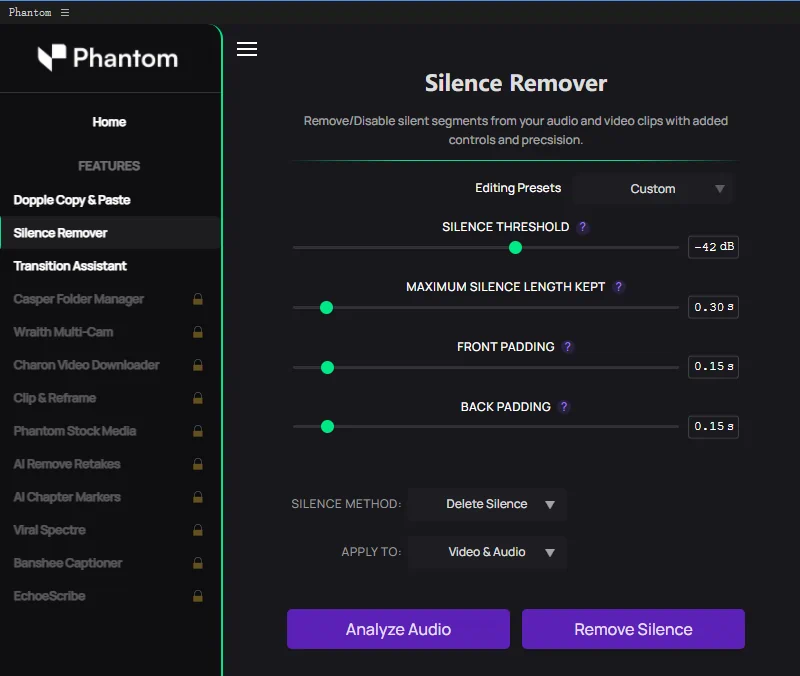
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
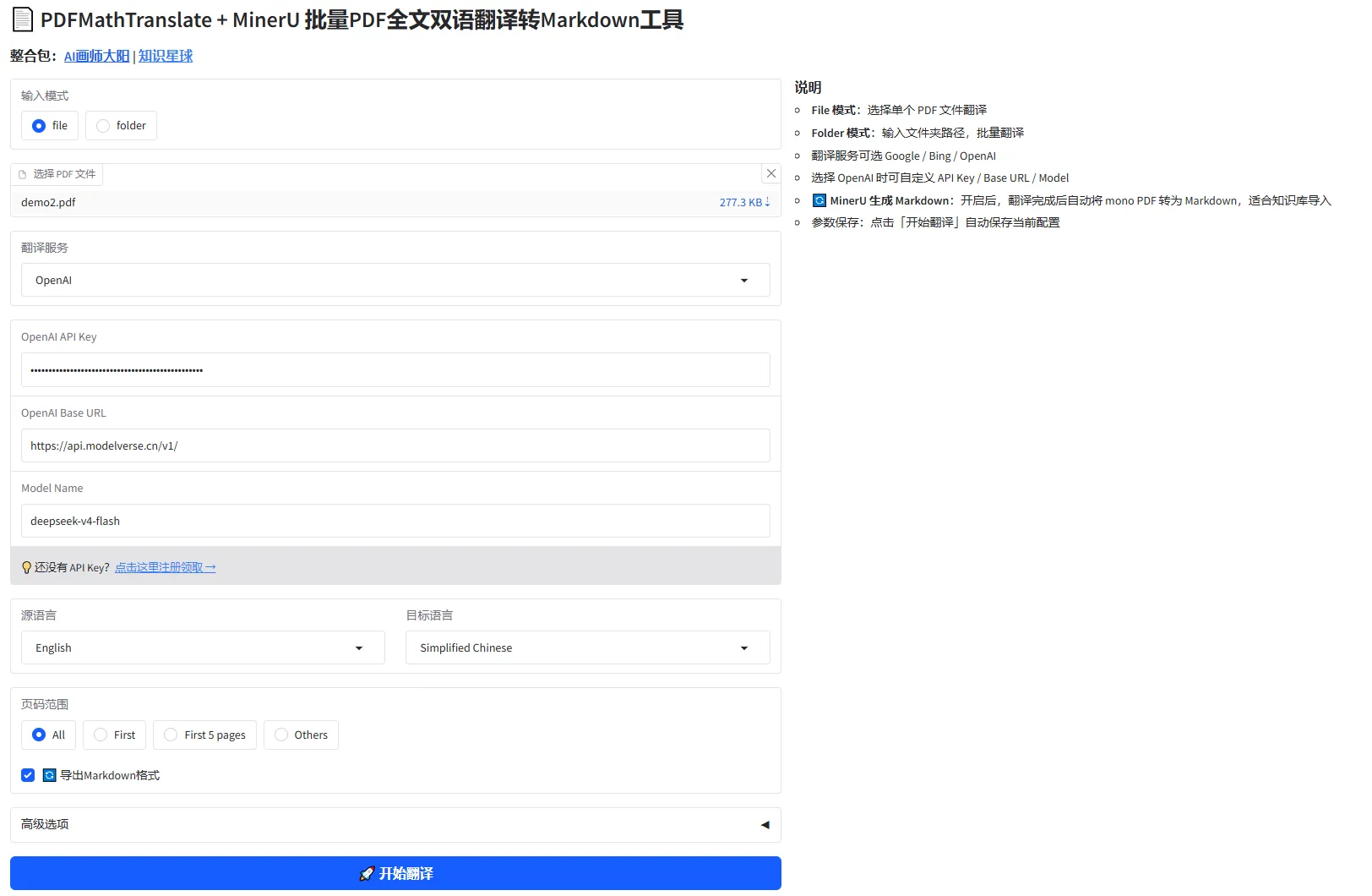
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...