某些电脑Python应用在生成图片时发生错误,生成了纯黑图片,并输出报错信息如下:
site-packages\rembg\sessions\base.py:52: RuntimeWarning: invalid value encountered in divide
im_ary = im_ary / np.max(im_ary)
site-packages\rembg\sessions\u2net.py:44: RuntimeWarning: invalid value encountered in cast
mask = Image.fromarray((pred * 255).astype(“uint8″), mode=”L”)
有些情况是代码问题,有些情况是原始图像问题,上面提到两个问题,
1、rembg 库中的除零问题 (invalid value encountered in divide):
提示图像数组中的最大值为零,导致出现无效除法操作。处理的图像数据中存在异常值,就是我们看到的结果全黑图像。
解决方案:可以在进行除法操作之前检查 np.max(im_ary) 是否为零,并在此情况下跳过除法操作,或确保输入图像数据的质量。
原始代码:
im_ary = np.array(im)
im_ary = im_ary / np.max(im_ary)修改后的代码:
im_ary = np.array(im)
# 检查 np.max(im_ary) 是否为零
max_val = np.max(im_ary)
if max_val > 0:
# 只有在最大值大于零时才进行归一化
im_ary = im_ary / max_val
else:
# 如果最大值为零,可以跳过归一化或者采取其他处理措施
im_ary = np.zeros_like(im_ary)2、rembg 库中的类型转换问题 (invalid value encountered in cast):
提示在进行数组转换为 uint8 类型时遇到了无效值。这可能是因为模型输出的 pred 数组中包含了超出 0-1 范围的值,导致在转换时发生问题。
解决方案:在转换前处理无效值及对 pred 进行剪裁或归一化处理,以确保其数值在合理范围内(如 [0, 1] 之间)
原代码为:
pred = ort_outs[0][:, 0, :, :]
ma = np.max(pred)
mi = np.min(pred)
pred = (pred - mi) / (ma - mi)
pred = np.squeeze(pred)
mask = Image.fromarray((pred * 255).astype("uint8"), mode="L")修改后的代码:
pred = ort_outs[0][:, 0, :, :]
ma = np.max(pred)
mi = np.min(pred)
pred = (pred - mi) / (ma - mi)
# 使用 np.nan_to_num 替换 NaN 和无穷大的值
pred = np.nan_to_num(pred, nan=0.0, posinf=1.0, neginf=0.0)
# 将数值剪裁到 [0, 1] 范围
pred = np.clip(pred, 0, 1)
pred = np.squeeze(pred)
mask = Image.fromarray((pred * 255).astype("uint8"), mode="L")相关推荐
 JupyterLab内5090显卡配置下SageAttention重新编译步骤
JupyterLab内5090显卡配置下SageAttention重新编译步骤- ERROR: Failed to build 'mmcv' when getting requirements to build wheel
- Python gradio应用启动后局域网内其它电脑访问使用开启端口方法
- cannot load library 'libcairo-2.dll': error 0x7e. Additionally,
- model = whisperx.load_model(卡住,程序崩溃闪退
- Processing failed:'DINOv3ViTModel' object has no attribute 'layer'
- Python免费翻译工具库,Google,Bing,百度翻译接口用法
- 使用Nuitka将Python应用打包为windows的exe程序具体方法
最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
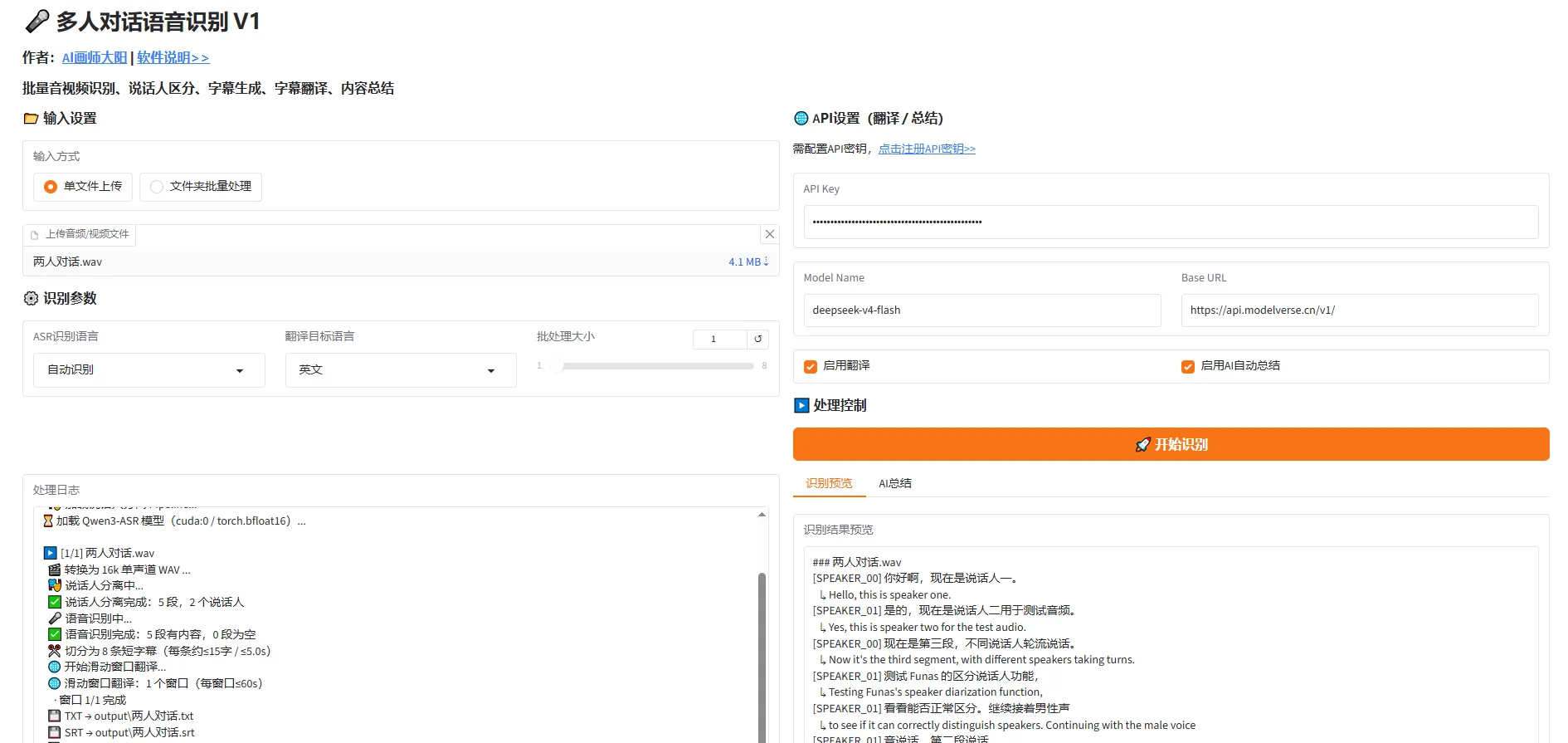
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
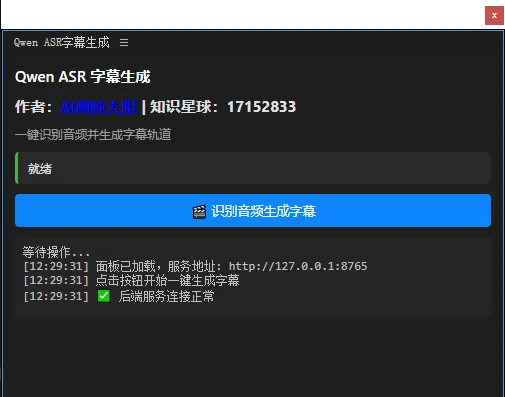
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
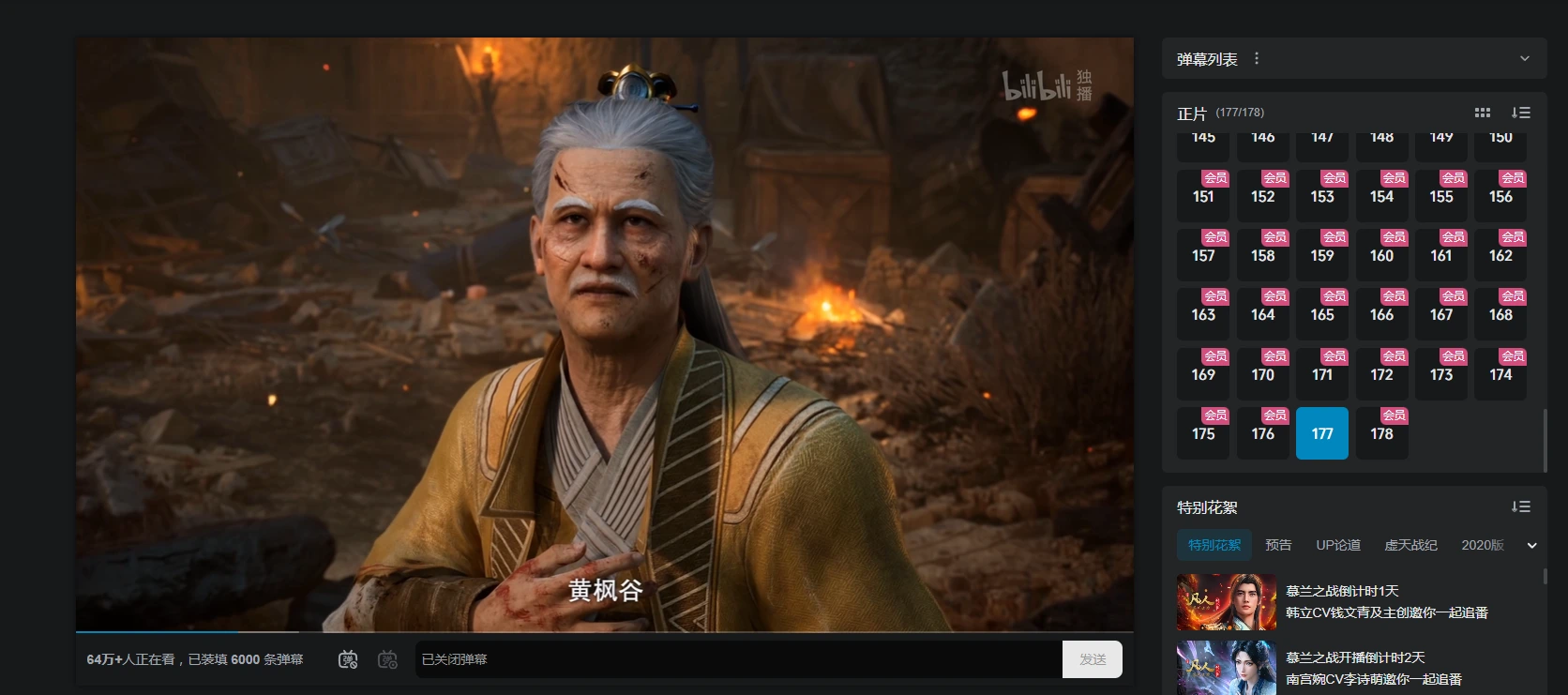
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
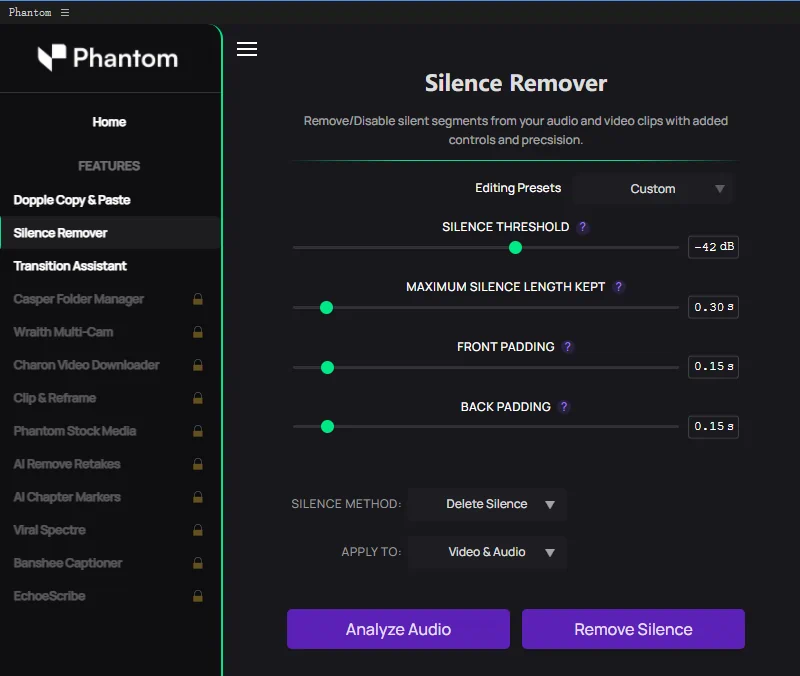
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
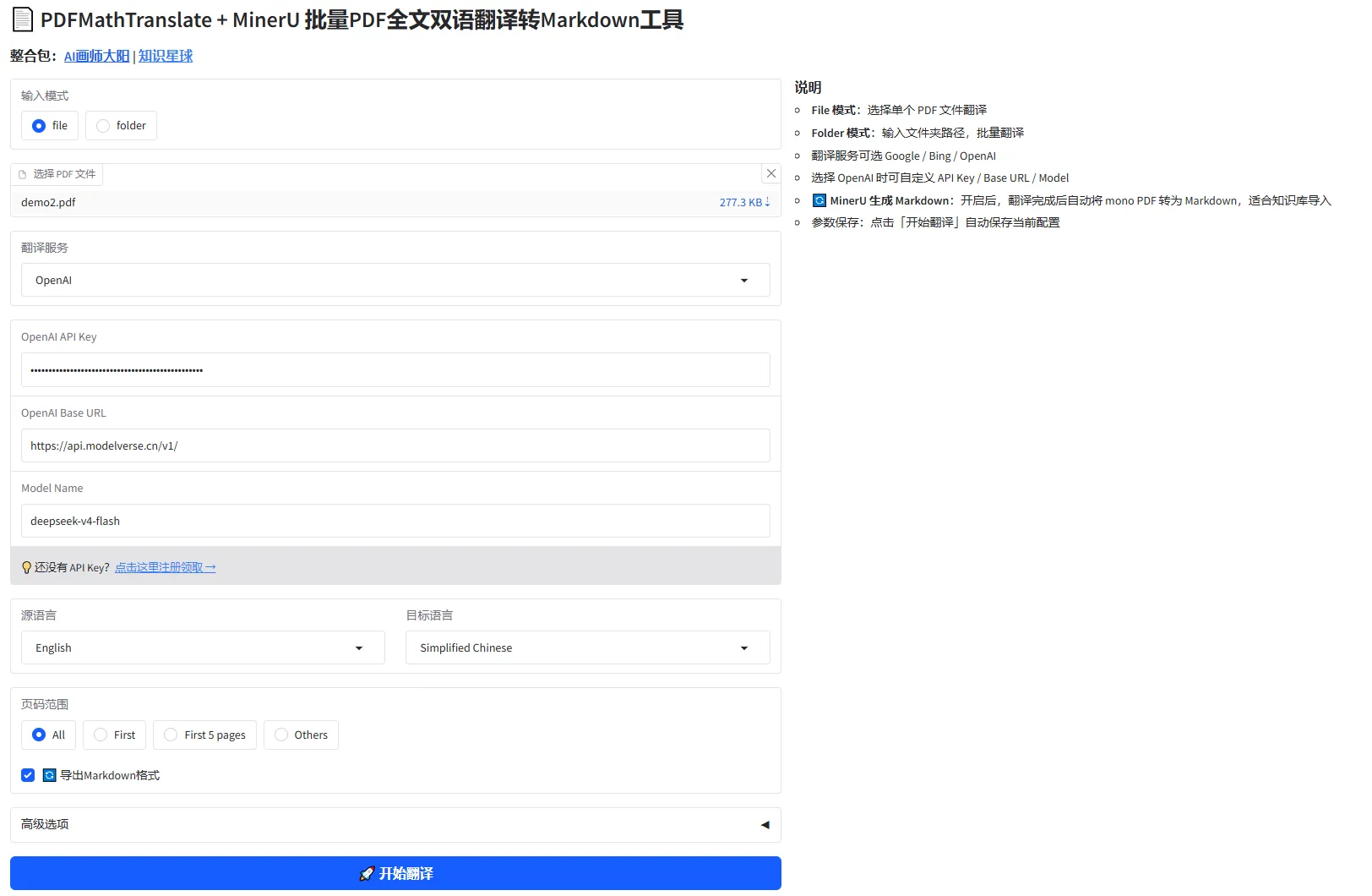
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...