MinerU发布至今我已经更新多版整合包了,5天前MinerU发布了第一个正式版1.0.1,并且看到在18小时之前有更新模型文件,我就做了个最新版的一键启动整合包。
整合包更新记录
2024-08-20 发布0.7版
2024-09-16 更新0.8.1版
2024-11-24 更新v0.10版
2025-01-15 更新1.0.1版
2025年02月21日更新v1.1.0版整合包
2025年02月27日更新v1.2.0版整合包
2025-06-05 更新v1.3.12版本
2025-07-24 更新v2.1.4版本
2025-10-23 更新v2.5.4版本
2026-01-25 更新v2.7.2版本
2026-01-28 更新v2.7.3版本
2026-05-11 更新v3.1.11版本
基于官方原功能做如下修改:
取消了最大转换页数限制
取消打包过程,减少步骤节省时间
增加批量处理功能,方便用量大的用户使用
批量模式处理效率高于单文件处理模式
为了实现“免安装一键启动”,及兼容低端和更多电脑减少错误发生,做了一定优化,软件默认使用pytorch后端,但是牺牲了约20%性能
2026-06-24 更新v3.4.0版本
删除部分无用代码,处理速度提升
增加解析强度选项
增加导出Word选项
MinerU介绍
可能还有很多人没使用过这个软件。MinerU是一款非常热门的高质量PDF转markdown和JSON格式软件
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为LaTeX格式
- 自动识别并转换文档中的表格为HTML格式
- 自动检测扫描版PDF和乱码PDF,并启用OCR功能
- OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
Mineru往期更新记录
2025年9月26日 2.5.4版本发布
🎉🎉 MinerU2.5技术报告现已发布!欢迎您阅读,以全面了解其模型架构、训练策略、数据工程和评估结果。
修复了部分PDF文件被误识别为AI文件导致解析失败的问题
2025年9月20日 2.5.3版本发布
调整了依赖版本范围,使Turing及更早架构的GPU能够使用vLLM加速MinerU2.5模型推理。
修复了与torch 2.8.0兼容的管道后端问题。
降低了vLLM异步后端的默认并发量,以减轻服务器压力,避免因高负载导致的连接关闭问题。
更多兼容性相关细节可参见公告
2025年9月19日 2.5.2版本发布
我们正式发布MinerU2.5,这是目前最强大的用于文档解析的多模态大模型。仅凭借12亿参数,MinerU2.5在OmniDocBench基准测试中的准确性全面超越了Gemini 2.5 Pro、GPT-4o和Qwen2.5-VL-72B等顶级多模态模型。它也显著优于dots.ocr、MonkeyOCR和PP-StructureV3等领先的专业模型。该模型已在HuggingFace和ModelScope平台发布,欢迎下载使用!
核心亮点:
极致效率下的SOTA性能:作为一个12亿参数的模型,它实现了超越100亿和1000亿+参数级别模型的最先进(SOTA)结果,重新定义了文档AI领域的参数性能标准。
全面领先的先进架构:通过结合两阶段推理管道(将布局分析与内容识别解耦)和原生高分辨率架构,在布局分析、文本识别、公式识别、表格识别和阅读顺序这五个关键领域均实现了SOTA性能。
关键能力增强:
布局检测:通过准确覆盖页眉、页脚和页码等非正文内容,提供更完整的结果。还能为列表和参考文献提供更精确的元素定位和自然格式重建。
表格解析:大幅改进了对具有挑战性案例的解析,包括旋转表格、无框/半结构化表格以及长/复杂表格。
公式识别:显著提高了对复杂、长格式以及中英混合公式的识别准确性,极大增强了对数学文档的解析能力。
此外,随着vlm 2.5的发布,我们对仓库做了一些调整:
vlm后端已升级至2.5版本,支持MinerU2.5模型,不再兼容MinerU2.0-2505-0.9B模型。支持2.0模型的最后一个版本是mineru-2.2.2。
VLM推理相关代码已移至mineru_vl_utils,减少了与主mineru仓库的耦合,便于未来独立迭代。
vlm加速推理框架已从sglang切换到vllm,实现了与vllm生态系统的完全兼容,允许用户在任何支持vllm框架的平台上使用MinerU2.5模型并进行加速推理。
由于vlm模型的重大升级支持了更多布局类型,我们对解析中间文件middle.json和结果文件content_list.json的结构做了一些调整,详情请参考文档。
更多更新内容可查看以前版本介绍《PDF转Markdown格式软件MinerU一键启动整合包v0.10.0版》
其它更新内容
- 2025/07/23 2.1.4 发布
- 错误修复
- 修复某些场景下后端
MFR步骤内存消耗过大的问题#2771pipeline - 修复某些条件下
image/table和caption/匹配不准确的问题#3129footnote
- 修复某些场景下后端
- 错误修复
- 2025/07/16 2.1.1 发布
- 错误修复
- 修复某些场景下可能出现的文本块内容丢失问题
pipeline#3005 sglang-client修复需要不必要的包(如torch#2968)的问题- 更新
dockerfile以修复由于 Linux 中缺少字体导致的文本内容解析不完整问题 #2915
- 修复某些场景下可能出现的文本块内容丢失问题
- 可用性改进
- 已更新
compose.yaml,以便于直接启动sglang-server、、mineru-api和mineru-gradio服务 - 推出全新的在线文档网站,简化自述文件,提供更好的文档体验
- 已更新
- 错误修复
- 2025/07/05 版本 2.1.0 发布
- 这是MinerU 2的首次重大更新,包含大量新功能和改进,涵盖显著的性能优化、用户体验提升以及错误修复。详细更新内容如下:
- 性能优化:
- 显著提高了特定分辨率文档(长边约 2000 像素)的预处理速度。
pipeline后端批量处理页数较少(<10页)的文档时,后处理速度大大提高。- 后端布局分析速度
pipeline提升约20%。
- 体验增强:
- 内置即用型
fastapi service和gradio webui。有关详细使用说明,请参阅文档。 - 已适配
sglang版本0.4.8,显著降低了后端 GPU 内存需求vlm-sglang。现在只需8GB GPU memory(Turing 架构或更新版本) 的显卡即可运行。 - 为所有相关的命令添加了透明参数传递
sglang,允许后端以与一致的方式sglang-engine接收所有参数。sglangsglang-server - 支持基于配置文件的功能扩展,包括
custom formula delimiters、enabling heading classification和customizing local model directories。详细使用说明请参考文档。
- 内置即用型
- 新功能:
- 后端更新
pipelinePP-OCRv5多语言文本识别模型,支持法语、西班牙语、葡萄牙语、俄语、韩语等37种语言的文本识别,平均准确率提升30%以上。详情 - 在后端引入了对垂直文本布局的有限支持
pipeline。
- 后端更新
在1月10日的时候发布了第一个正式版1.0.1版。1.0.1版更新内容有:
引入了全新的API接口,并通过大量重构增强了兼容性,同时引入了全新的自动语言识别功能:
- 新的 API 接口
- 对于数据端API,我们引入了Dataset类,旨在提供强大而灵活的数据处理框架。该框架目前支持多种文档格式,包括图片(.jpg和.png)、PDF、Word文档(.doc和.docx)和PowerPoint演示文稿(.ppt和.pptx)。它确保有效支持从简单到复杂的数据处理任务。
- 对于用户端API,我们精心设计了MinerU的处理流程为一系列可组合的Stage,每个Stage代表一个具体的处理步骤,用户可以根据自己的需求定义新的Stage,并创造性地组合这些Stage来定制自己的数据处理流程。
- 增强兼容性
- 通过优化依赖环境和配置项,保证在ARM架构Linux系统上稳定、高效的运行。
- 与华为Ascend NPU加速深度融合,提供自主可控的高性能计算能力,支撑中国AI应用平台的本土化发展。Ascend NPU加速
- 自动语言识别
- 通过引入新的语言识别模型,在文档解析时将配置设置
lang为auto将自动选择合适的OCR语言模型,提高扫描文档解析的准确性。
- 通过引入新的语言识别模型,在文档解析时将配置设置
2025年2月21日整合包更新内容
支持最新1.1.0版,此版本重点提升了解析准确率和效率:
模型能力升级(需要重新下载模型文件,以前的已不可用)
布局识别模型升级为最新的doclayout_yolo(2501)模型,提升布局识别准确率。
公式解析模型升级为最新的unimernet(2501)模型,提升公式识别准确率。
性能优化
在满足一定配置要求的设备上(16GB+VRAM),通过优化资源使用和重构处理流水线,整体解析速度提升50%以上。
解析效果优化
2025年2月27日整合包更新内容
1.2.0发布。此版本包括几个修复和改进,以提高解析效率和准确性:
性能优化
提高了自动模式下PDF文档的分类速度。
解析优化
改进了包含水印的文档的解析逻辑,显著提高了此类文档的解析结果。
增强了单个页面内多个图像/表格和标题的匹配逻辑,提高了复杂布局中图像文本匹配的准确性。
漏洞修补
修复了在某些情况下图像/表格跨度被错误地填充到文本块中的问题。
解决了某些情况下标题栏为空的问题。
1.2.1-1.3.10大量更新内容不再转述
1.3.12更新内容
- 增加ppocrv5模型的支持,将
ch_server模型更新为PP-OCRv5_rec_server,ch_lite模型更新为PP-OCRv5_rec_mobile(需更新模型)- 在测试中,发现ppocrv5(server)对手写文档效果有一定提升,但在其余类别文档的精度略差于v4_server_doc,因此默认的ch模型保持不变,仍为
PP-OCRv4_server_rec_doc。 - 由于ppocrv5强化了手写场景和特殊字符的识别能力,因此您可以在日繁混合场景以及手写文档场景下手动选择使用ppocrv5模型
- 您可通过lang参数
lang='ch_server'(python api)或--lang ch_server(命令行)自行选择相应的模型:ch:PP-OCRv4_rec_server_doc(默认)(中英日繁混合/1.5w字典)ch_server:PP-OCRv5_rec_server(中英日繁混合+手写场景/1.8w字典)ch_lite:PP-OCRv5_rec_mobile(中英日繁混合+手写场景/1.8w字典)ch_server_v4:PP-OCRv4_rec_server(中英混合/6k字典)ch_lite_v4:PP-OCRv4_rec_mobile(中英混合/6k字典)
- 在测试中,发现ppocrv5(server)对手写文档效果有一定提升,但在其余类别文档的精度略差于v4_server_doc,因此默认的ch模型保持不变,仍为
- 增加手写文档的支持,通过优化layout对手写文本区域的识别,现已支持手写文档的解析
- 默认支持此功能,无需额外配置
- 可以参考上述说明,手动选择ppocrv5模型以获得更好的手写文档解析效果
MinerU整合包使用说明
首先将软件压缩包从网盘下载到本地电脑上并解压。
然后双击运行【启动软件.bat】,稍后即可自动打开WEBUI操作界面。
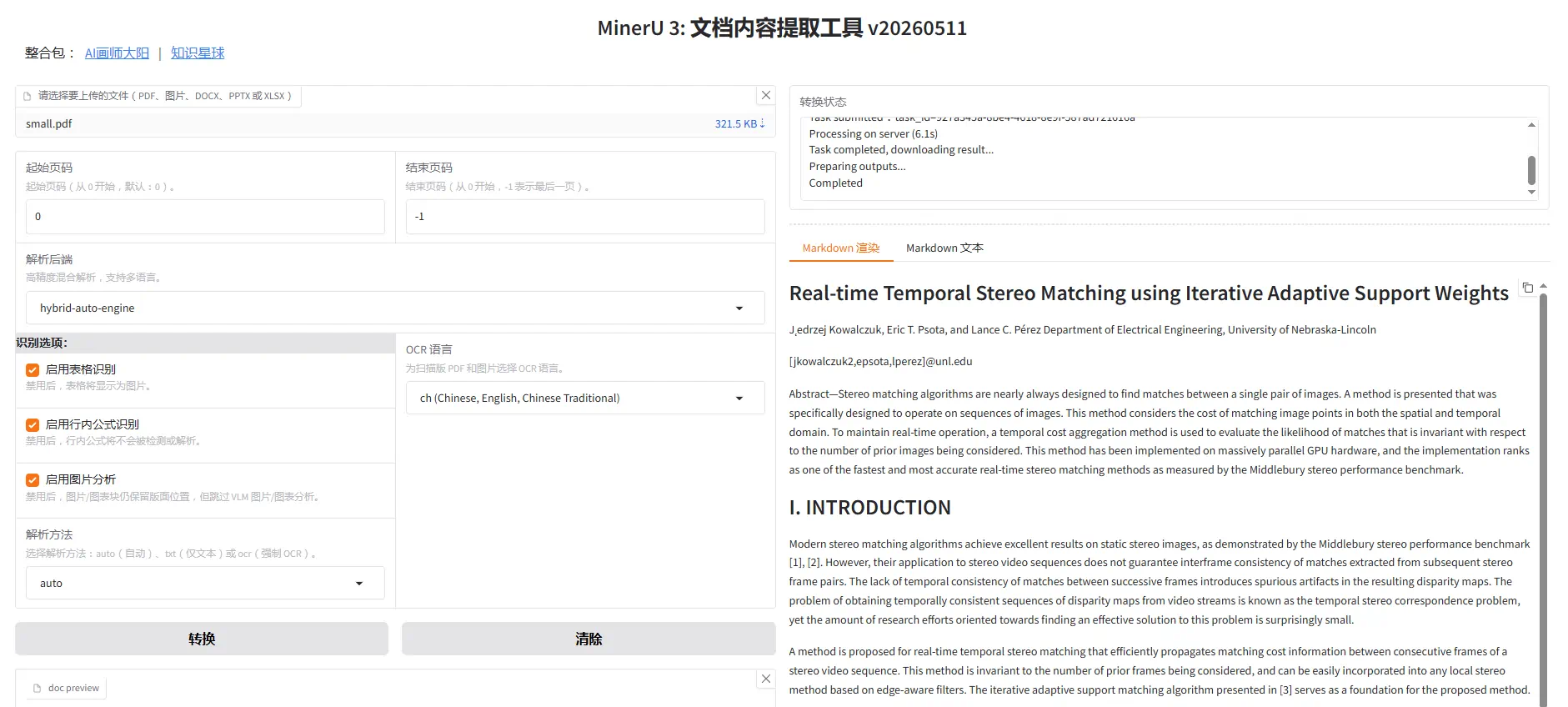
首先选择待处理PDF文件,你可以点击选择文件按钮选择文件,也可以把想要处理的文件鼠标左键按住拖动到软件窗口中。软件也支持批量处理,直接输入文件夹路径即可。软件只支持识别PDF文档和图片格式文件
解析后端:默认hybrid后端,英伟达显卡显存6G以上
解析方法:默认auto模式,你也可以手动选择ocr或txt,如果是纯文本文档,建议选择txt,速度更快
PDF语言:指定文档语言可提高OCR准确性,填写语言代码,如英语文档填:en,其它语言代码如下:[ch|ch_server|ch_lite|en|korean|japan|chinese_cht|ta|te|ka|th|el|latin|arabic|east_slavic|cyrillic|devanagari],不熟悉可忽略。
起始页:想从PDF哪页开始处理。页数从0开始计数的,比如想从第二页开始处理,这里就填1
结束页:想要软件处理到哪页结束,和上面一样,填数字
默认只需要设置待处理文件和保存位置即可,其它不需要设置。
表格识别和公式识别功能默认都是开启的,如果你用不到这些功能或是电脑带不动,你可以选择关闭这些功能。
PDF文档处理完成后结果会保存在你设置的输出目录里。
输出结果文件说明:
├——some_pdf.md#最终md文件
├——images#图像存储目录
├——some_pdf_layout.pdf#布局图
├——some_pdf_middle.json#MinerU中间处理结果
├——some_pdf_model.json模型推理结果
├——some_pdf_origin.pdf#根据设置处理后的原始pdf文件,如裁剪了页数范围
├——some_pdf_spans.pdf#最小粒度bbox位置信息图
└——some_pdf_content_list.json#按阅读顺序排列的富文本json
整合包支持电脑离线使用
最终处理结果
单文件处理后保存在项目文件夹内的output文件夹内
注意事项
建议英伟达显卡显存4G以上用户使用
支持英伟达50系列显卡
整合包只支持Windows 10或11系统
软件运行路径中不要有非英文字符和空格,待处理文件同样注意
保存位置不要选择盘符根目录下
PDF转Markdown/Word软件MinerU 3.4.0版整合包下载链接
https://pan.quark.cn/s/debdb18d23ac
MinerU 在线一键启动
相关推荐
 PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具- Mineru PDF转markdown软件局域网版
- PDF转Markdown软件MinerU 3.1.11整合包(高性能版)
- 图片/PDF转HTML/Markdown/JSON软件Chandra—— Windows 版一键启动包,免安装部署,可离线
- 字节跳动Dolphin图片文档解析工具免安装一键启动整合包下载,PDF转JSON/Markdown软件
- PDF/图片转markdown软件MonkeyOCR整合包,文档图片解析工具下载
- 微软PDF/WORD/HTML文档转Markdown格式软件markitdown整合包下载
- PDF转Markdown软件MinerU 2.5.4版整合包使用说明视频教程


最近更新
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
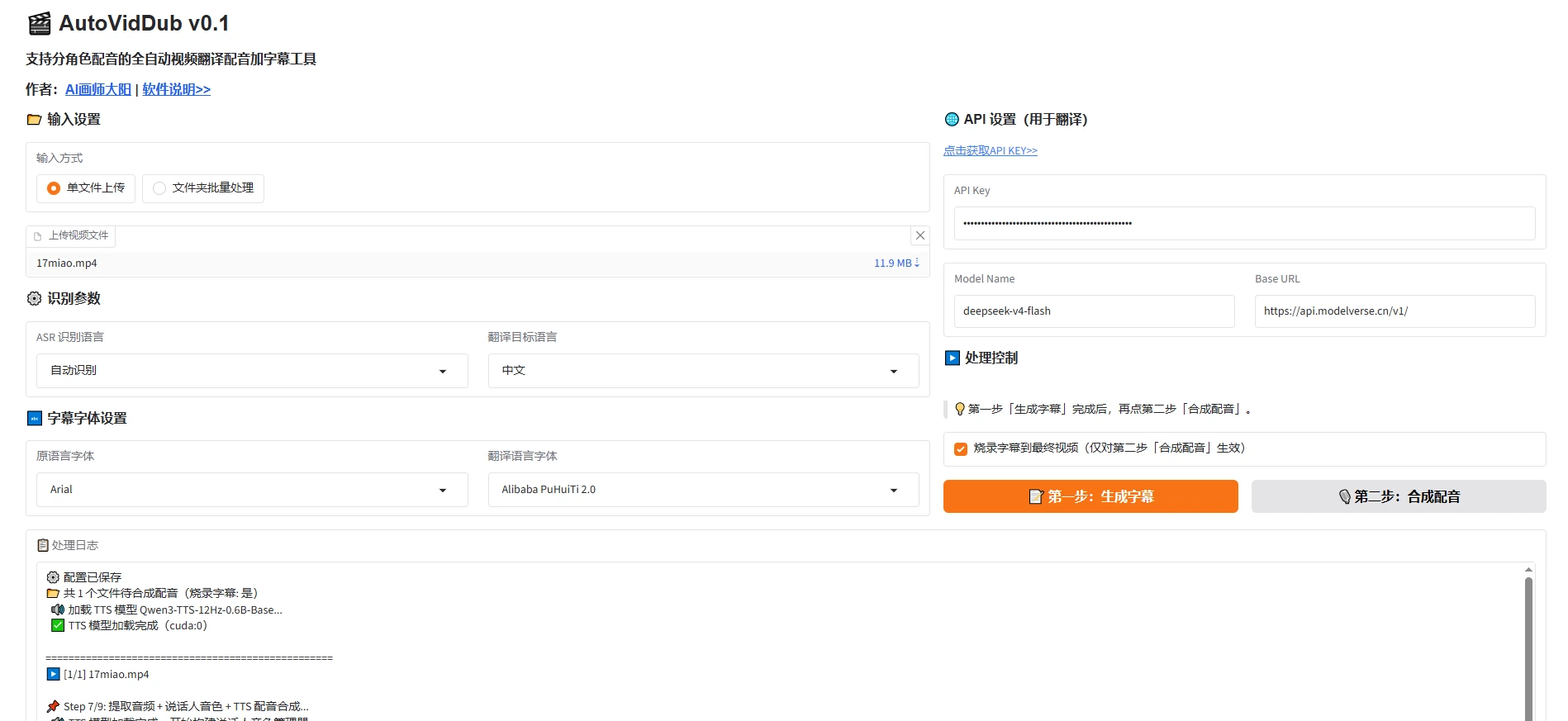
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
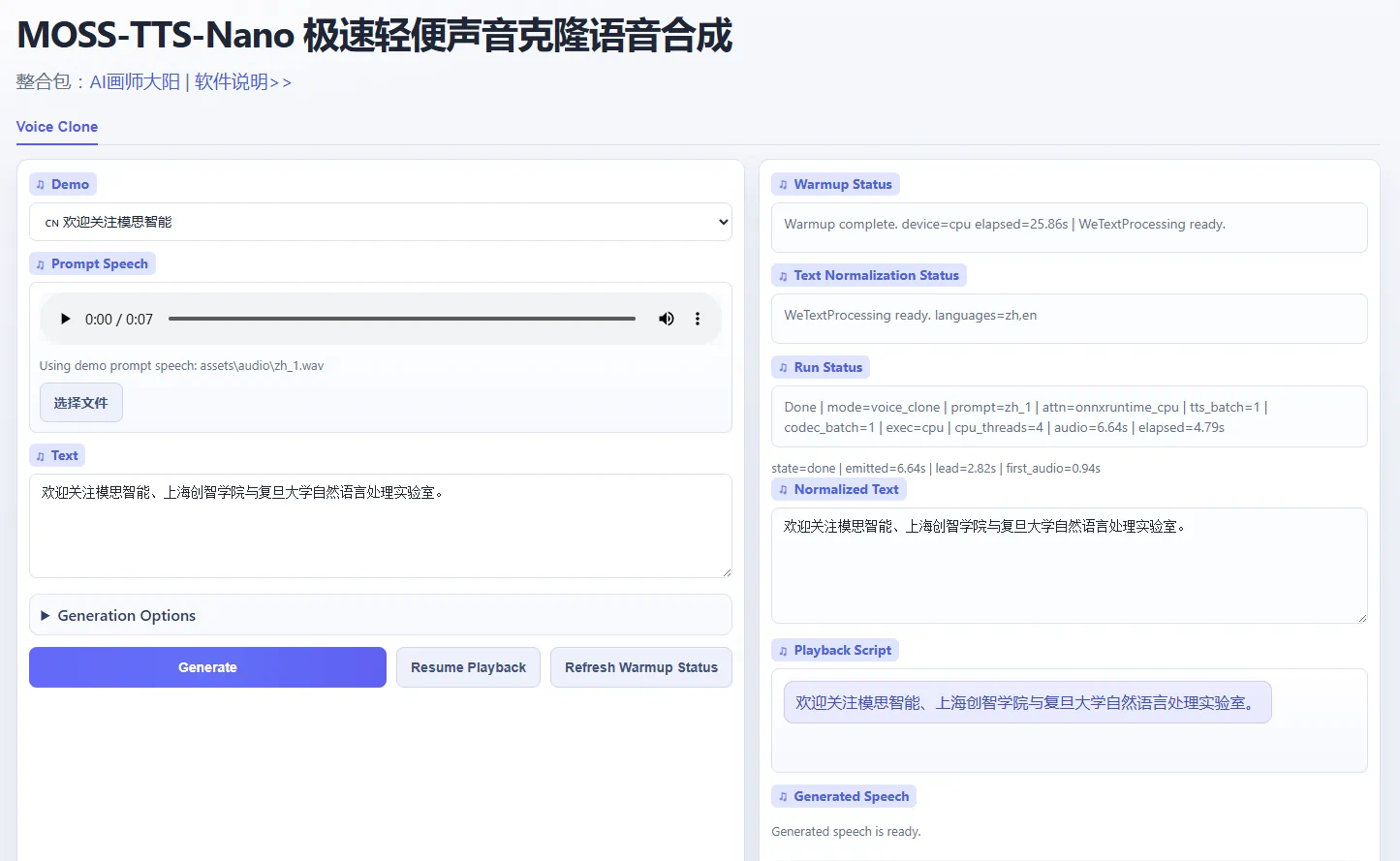
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
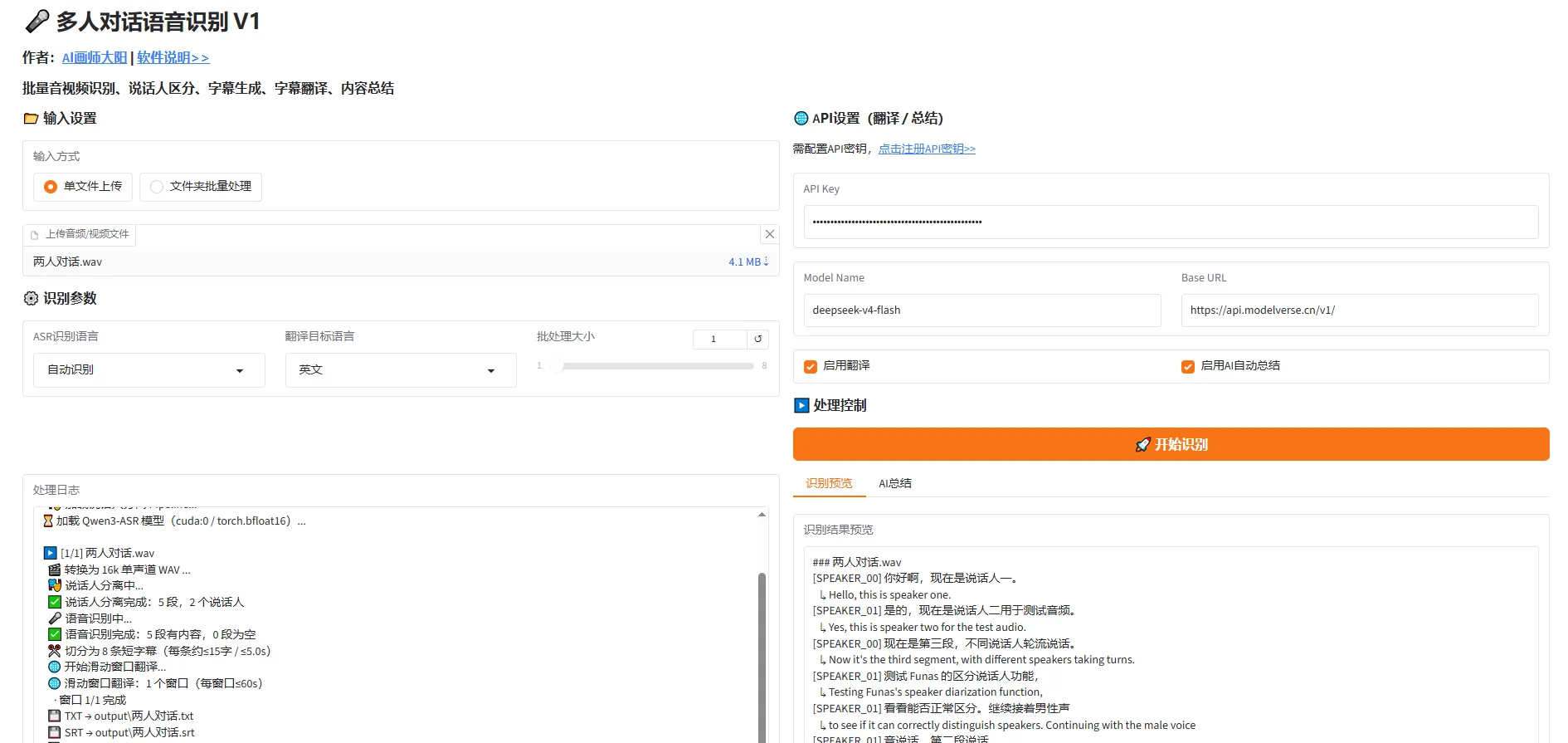
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
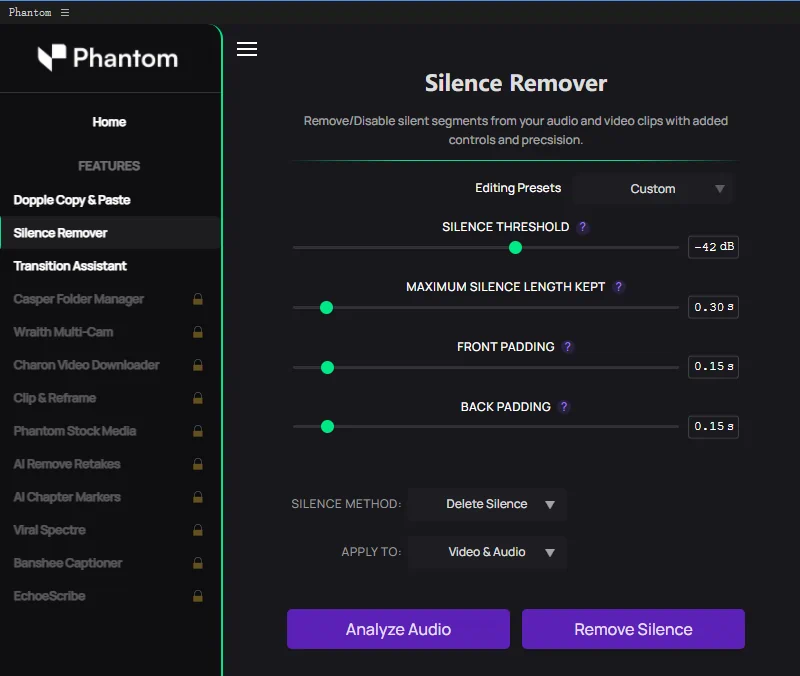
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
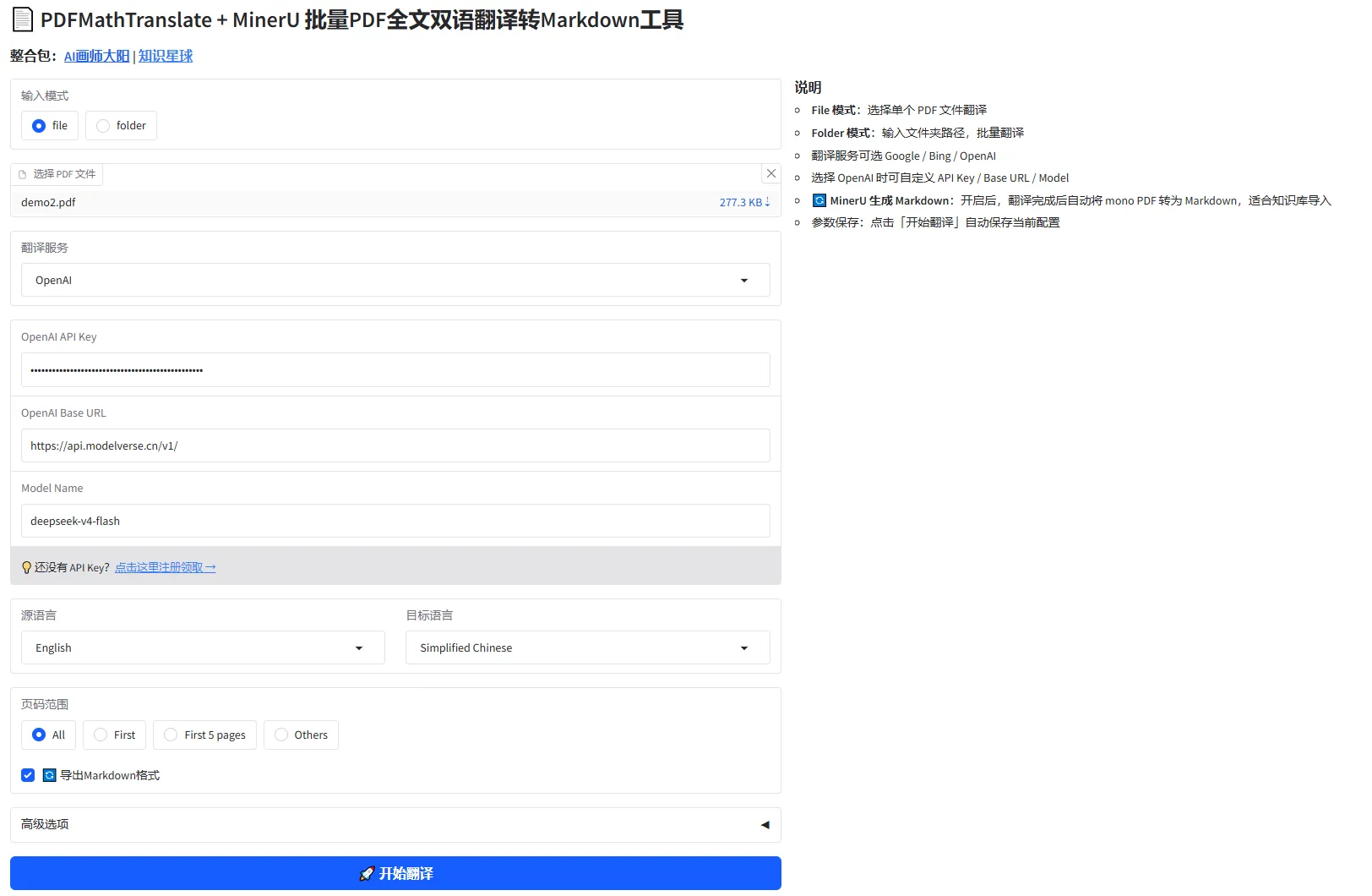
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...