Ultralytics YOLO11 是一款前沿的、最先进的SOTA模型,它在之前 YOLO 版本的成功基础上进行了改进,并引入了新的功能和优化,以进一步提升性能和灵活性。YOLO11 旨在实现快速、准确且易于使用,使其成为广泛目标检测与跟踪、实例分割、图像分类以及姿态估计任务的理想选择。
YOLO11的功能十分强大,所以操作命令也非常多,我根据官方文档整理了最新版YOLO11的各项任务的详细操作命令,包括主要的训练和推理预测等。
YOLO命令格式:yolo TASK MODE ARGS
TASK:任务类型,值可以省略。TASK 的可选值如下:
Detect(默认参数)
任务类型:目标检测
功能:检测图像或视频中的物体,并输出物体的边界框和类别标签。
示例命令:
yolo detect predict model=yolo11n.pt source=’image.jpg’
segment
任务类型:实例分割
功能:不仅检测物体,还为每个物体生成像素级的掩码。
示例命令:
yolo segment predict model=yolo11n-seg.pt source=’image.jpg’
classify
任务类型:图像分类
功能:对图像进行分类,输出图像的类别标签。
示例命令:
yolo classify predict model=yolo11n-cls.pt source=’image.jpg’
pose
任务类型:姿态估计
功能:检测图像中的人体关键点(如关节),并输出关键点的位置。
示例命令:
yolo pose predict model=yolo11n-pose.pt source=’image.jpg’
obb
任务类型:旋转框检测
功能:检测物体并输出旋转的边界框(适用于倾斜的物体)。
示例命令:
yolo obb predict model=yolo11n-obb.pt source=’image.jpg’
TASK值默认可以忽略,程序会根据模型类型自动推断任务类型,处理多种任务时推荐指明参数。
MODE:必需,用于指定要执行的操作模式,定义了 YOLO 的具体行为
train
功能:训练模型。
用途:使用指定的数据集和配置文件训练 YOLO 模型。
示例命令:
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
在图像大小为640的COCO8数据集上训练YOLO11n 100个迭代周期。
val
功能:验证模型。
用途:在验证集上评估模型的性能,计算指标(如 mAP、精度、召回率等)。
示例命令:
yolo detect val model=yolo11n.pt
predict
功能:推理预测。
用途:使用训练好的模型对新的图像或视频进行推理,生成检测结果(如边界框、类别标签、置信度等)。
示例命令:
yolo detect predict model=yolo11n.pt source=’https://ultralytics.com/images/bus.jpg’
export
功能:导出模型。
用途:将训练好的模型导出为其他格式(如 ONNX、TensorRT、CoreML 等),以便在其他平台或框架中使用。
示例命令:
yolo export model=yolo11n.pt format=onnx
track
功能:目标跟踪。
用途:在视频中进行目标检测并跟踪物体的运动轨迹。
示例命令:
yolo track model=yolo11n.pt source=’video.mp4′
benchmark
功能:模型性能基准测试。
用途:测试模型在不同硬件上的推理速度(如 FPS)和资源占用情况。
示例命令:
yolo benchmark model=yolo11n.pt imgsz=640
Train训练
示例代码:
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
命令解释:在图像大小为640的COCO8数据集上训练YOLO11n 100个迭代周期。其他参数:
| 参数 | 类型 | 默认值 | 描述 |
| model | str | None | 指定用于训练的模型文件。接受 .pt 预训练模型或 .yaml 配置文件的路径。用于定义模型结构或初始化权重。 |
| data | str | None | 数据集配置文件的路径(如 coco8.yaml)。该文件包含数据集相关参数,包括训练和验证数据的路径、类别名称和类别数量。 |
| epochs | int | 100 | 训练的总轮数。每轮代表对整个数据集的完整遍历。调整此值会影响训练时长和模型性能。 |
| time | float | None | 训练的最大时间(以小时为单位)。如果设置,此参数会覆盖 epochs 参数,允许在指定时间后自动停止训练。适用于时间受限的训练场景。 |
| patience | int | 100 | 在验证指标没有改善的情况下,等待的轮数,之后提前停止训练。有助于防止过拟合,当性能趋于平稳时停止训练。 |
| batch | int | 16 | 批量大小,支持三种模式:设置为整数(如 batch=16),自动模式(使用 60% 的 GPU 内存,batch=-1),或指定利用率分数的自动模式(如 batch=0.70)。 |
| imgsz | int 或 list | 640 | 训练的目标图像尺寸。所有图像在输入模型之前会被调整为此尺寸。影响模型精度和计算复杂度。 |
| save | bool | True | 启用训练检查点和最终模型权重的保存。适用于恢复训练或模型部署。 |
| save_period | int | -1 | 保存模型检查点的频率(以轮数为单位)。值为 -1 时禁用此功能。适用于长时间训练中保存中间模型。 |
| cache | bool | False | 启用数据集图像的缓存(True/ram 表示内存缓存,disk 表示磁盘缓存,False 表示禁用缓存)。通过减少磁盘 I/O 提高训练速度,但会增加内存使用。 |
| device | int 或 str 或 list | None | 指定训练的计算设备:单个 GPU(device=0),多个 GPU(device=0,1),CPU(device=cpu),或 Apple silicon 的 MPS(device=mps)。 |
| workers | int | 8 | 数据加载的工作线程数(如果是多 GPU 训练,则每个 RANK 的线程数)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
| project | str | None | 保存训练输出的项目目录名称。允许对不同实验进行有序存储。 |
| name | str | None | 训练运行的名称。用于在项目文件夹中创建子目录,保存训练日志和输出。 |
| exist_ok | bool | False | 如果为 True,允许覆盖现有的项目/名称目录。适用于无需手动清除先前输出的迭代实验。 |
| pretrained | bool | True | 确定是否从预训练模型开始训练。可以是布尔值或指定模型的路径。提高训练效率和模型性能。 |
| optimizer | str | ‘auto’ | 训练优化器的选择。选项包括 SGD、Adam、AdamW、NAdam、RAdam、RMSProp 等,或 auto 以根据模型配置自动选择。影响收敛速度和稳定性。 |
| seed | int | 0 | 设置训练的随机种子,确保在相同配置下运行的结果可复现。 |
| deterministic | bool | True | 强制使用确定性算法,确保结果可复现,但可能因限制非确定性算法而影响性能和速度。 |
| single_cls | bool | False | 在多类别数据集中将所有类别视为单一类别进行训练。适用于二分类任务或仅关注物体存在而非分类的场景。 |
| classes | list[int] | None | 指定要训练的类别 ID 列表。适用于在训练中过滤并仅关注某些类别。 |
| rect | bool | False | 启用矩形训练,优化批次组合以减少填充。可提高效率和速度,但可能影响模型精度。 |
| multi_scale | bool | False | 启用多尺度训练,在训练期间将 imgsz 增加/减少最多 0.5 倍。训练模型在推理时对多种图像尺寸更准确。 |
| cos_lr | bool | False | 使用余弦学习率调度器,根据余弦曲线调整学习率。有助于更好地管理学习率以实现收敛。 |
| close_mosaic | int | 10 | 在最后 N 轮禁用马赛克数据增强,以在训练结束前稳定训练。设置为 0 禁用此功能。 |
| resume | bool | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和轮数,无缝继续训练。 |
| amp | bool | True | 启用自动混合精度(AMP)训练,减少内存使用并可能加速训练,同时对精度影响最小。 |
| fraction | float | 1.0 | 指定用于训练的数据集比例。允许在完整数据集的子集上进行训练,适用于实验或资源有限的情况。 |
| profile | bool | False | 启用 ONNX 和 TensorRT 速度的性能分析,适用于优化模型部署。 |
| freeze | int 或 list | None | 冻结模型的前 N 层或指定索引的层,减少可训练参数数量。适用于微调或迁移学习。 |
| lr0 | float | 0.01 | 初始学习率(如 SGD=1E-2,Adam=1E-3)。调整此值对优化过程至关重要,影响模型权重更新的速度。 |
| lrf | float | 0.01 | 最终学习率作为初始学习率的一部分(即 lr0 * lrf),与调度器结合使用以随时间调整学习率。 |
| momentum | float | 0.937 | SGD 的动量因子或 Adam 的 beta1,影响当前更新中过去梯度的结合。 |
| weight_decay | float | 0.0005 | L2 正则化项,惩罚较大的权重以防止过拟合。 |
| warmup_epochs | float | 3.0 | 学习率预热轮数,逐渐将学习率从低值增加到初始学习率,以在训练初期稳定训练。 |
| warmup_momentum | float | 0.8 | 预热阶段的初始动量,逐渐调整到设定的动量值。 |
| warmup_bias_lr | float | 0.1 | 预热阶段偏置参数的学习率,帮助在初始轮次稳定模型训练。 |
| box | float | 7.5 | 损失函数中边界框损失分量的权重,影响对准确预测边界框坐标的重视程度。 |
| cls | float | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他分量的重要性。 |
| dfl | float | 1.5 | 分布焦点损失的权重,用于某些 YOLO 版本中的细粒度分类。 |
| pose | float | 12.0 | 姿态估计模型中姿态损失的权重,影响对准确预测姿态关键点的重视程度。 |
| kobj | float | 2.0 | 姿态估计模型中关键点目标性损失的权重,平衡检测置信度与姿态准确性。 |
| nbs | int | 64 | 损失归一化的标称批量大小。 |
| overlap_mask | bool | True | 确定是否将对象掩码合并为单个掩码进行训练,或为每个对象保留单独的掩码。在重叠情况下,较小的掩码会在合并时覆盖较大的掩码。 |
| mask_ratio | int | 4 | 分割掩码的下采样比例,影响训练期间使用的掩码分辨率。 |
| dropout | float | 0.0 | 分类任务中的 dropout 率,通过在训练期间随机省略单元来防止过拟合。 |
| val | bool | True | 在训练期间启用验证,允许在单独的数据集上定期评估模型性能。 |
| plots | bool | False | 生成并保存训练和验证指标的图表以及预测示例,提供对模型性能和学习进展的直观洞察。 |
Predict推理命令参数:
| 参数 | 类型 | 默认值 | 描述 |
| source | str | ‘ultralytics/assets’ | 指定推理的数据源。可以是图像路径、视频文件、或摄像头0。支持多种格式和来源,适用于不同类型的输入。 |
| conf | float | 0.25 | 设置检测的最小置信度阈值。置信度低于此阈值的检测对象将被忽略。调整此值有助于减少误报。 |
| iou | float | 0.7 | 非极大值抑制(NMS)的交并比(IoU)阈值。较低的值会通过消除重叠框减少检测数量,适用于减少重复检测。 |
| imgsz | int 或 tuple | 640 | 定义推理的图像尺寸。可以是单个整数(如 640,表示正方形调整)或 (高度, 宽度) 元组。适当的尺寸可以提高检测精度和处理速度。 |
| half | bool | False | 启用半精度(FP16)推理,可以在支持的 GPU 上加速模型推理,同时对精度影响最小。 |
| device | str | None | 指定推理的设备(如 cpu、cuda:0 或 0)。允许用户选择 CPU、特定 GPU 或其他计算设备来执行模型。 |
| batch | int | 1 | 指定推理的批量大小(仅在数据源为目录、视频文件或 .txt 文件时有效)。较大的批量大小可以提高吞吐量,缩短推理所需的总时间。 |
| max_det | int | 300 | 每张图像允许的最大检测数量。限制模型在单次推理中可以检测到的对象总数,防止在密集场景中输出过多结果。 |
| vid_stride | int | 1 | 视频输入的帧步幅。允许跳过视频中的帧以加快处理速度,但会降低时间分辨率。值为 1 时处理每一帧,较高的值会跳过帧。 |
| stream_buffer | bool | False | 确定是否为视频流队列传入帧。如果为 False,旧帧会被丢弃以容纳新帧(适用于实时应用)。如果为 True,新帧会被缓冲,确保不跳过任何帧,但如果推理 FPS 低于流 FPS,则会导致延迟。 |
| visualize | bool | False | 激活推理期间模型特征的可视化,提供模型“看到”的内容的洞察。适用于调试和模型解释。 |
| augment | bool | False | 启用测试时数据增强(TTA)进行预测,可能提高检测鲁棒性,但会降低推理速度。 |
| agnostic_nms | bool | False | 启用类别无关的非极大值抑制(NMS),合并不同类别的重叠框。适用于多类别检测场景中类别重叠常见的情况。 |
| classes | list[int] | None | 过滤预测结果到一组类别 ID。仅返回属于指定类别的检测结果。适用于在多类别检测任务中关注相关对象。 |
| retina_masks | bool | False | 返回高分辨率的分割掩码。如果启用,返回的掩码(masks.data)将匹配原始图像尺寸。如果禁用,则使用推理期间的图像尺寸。 |
| embed | list[int] | None | 指定从中提取特征向量或嵌入的层。适用于聚类或相似性搜索等下游任务。 |
| project | str | None | 如果启用了保存功能,则指定保存预测输出的项目目录名称。 |
| name | str | None | 预测运行的名称。如果启用了保存功能,则用于在项目文件夹中创建子目录,保存预测输出。 |
相关推荐


最近更新
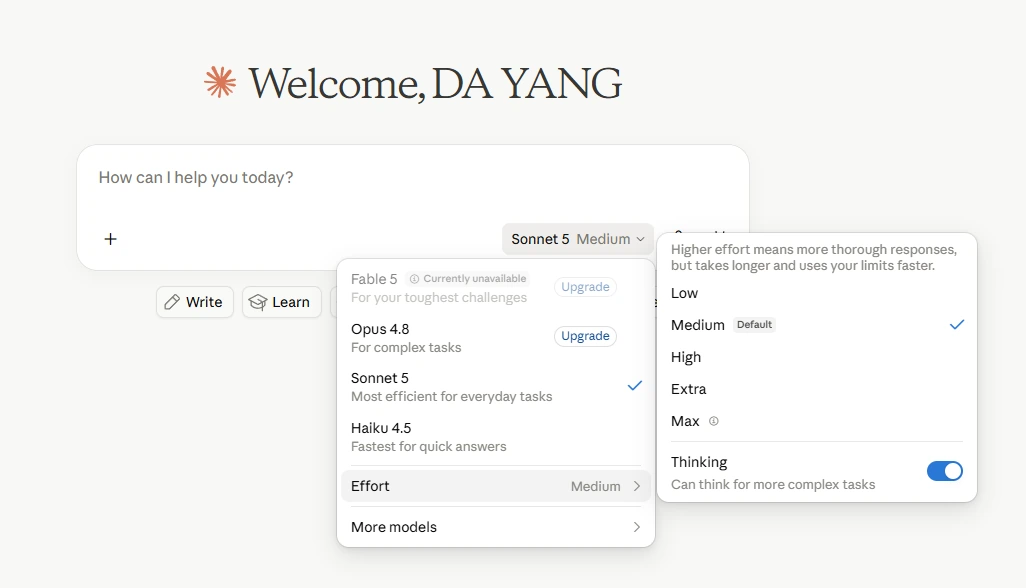
Claude 再放大招,Sonnet 5 来了
一觉醒来Anthropic又放大招了,Claude Sonnet 5来了。 不得不说国外大语言模型更新的是真快的,各家LLM版本更新迭代频率都很高,Claude 刚发布Opus 4.8 不久,这又发布了Sonnet 5.Anthropic ...
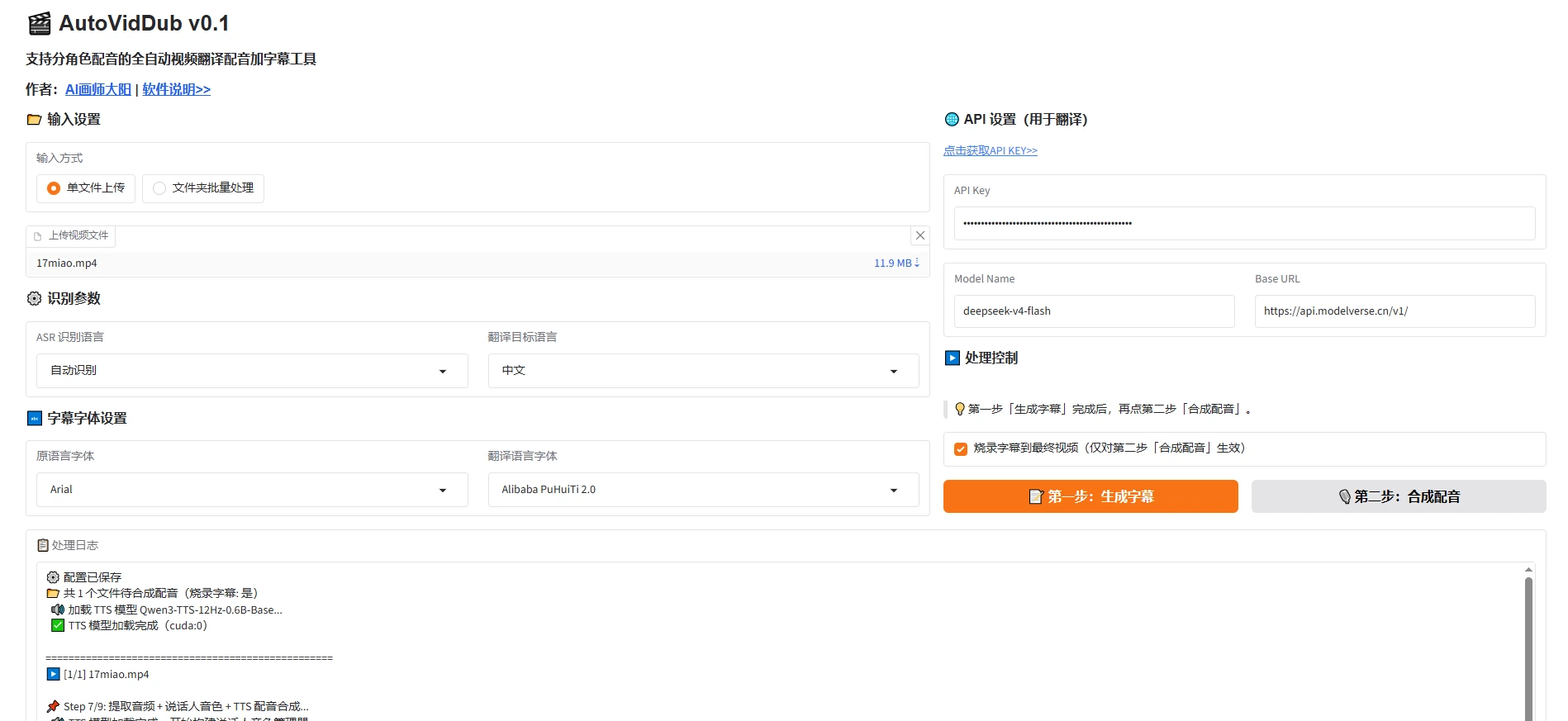
AutoVidDub支持分角色配音的全自动视频翻译配音加字幕工具
支持分角色配音的全自动流水线,一键将外语视频转为带母语配音和双语字幕的目标语言视频。 一、软件简介 AutoVidDub 是一套运行在本地 GPU 上的全自动视频翻译配音工具。你只需提供一个视频文件,它就能自动完成以下全部工序: 二、核心功...
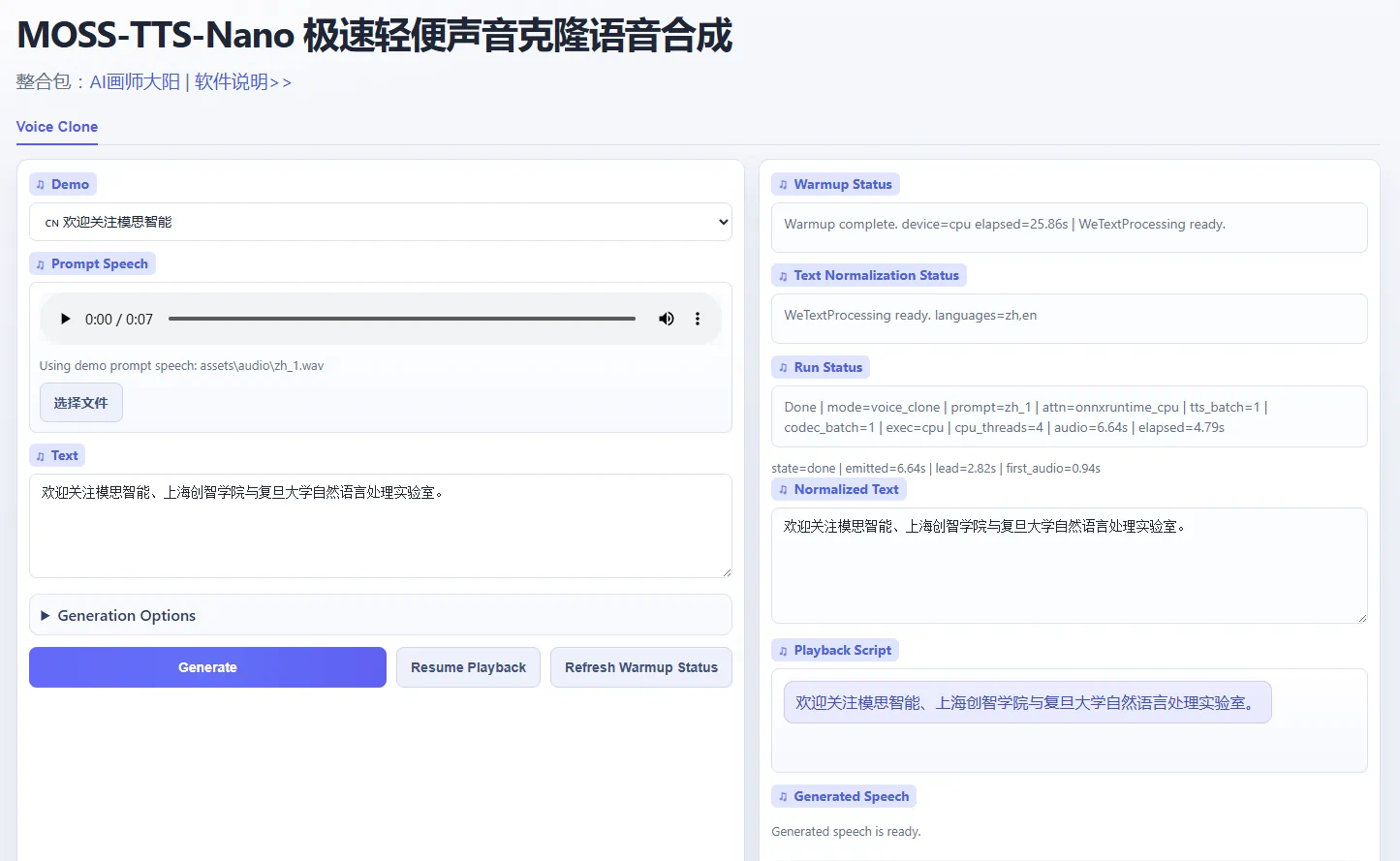
极速轻便声音克隆语音合成软件MOSS-TTS-Nano整合包,CPU可流畅运行
一、项目概述 MOSS-TTS-Nano 是由 MOSI.AI 与 OpenMOSS 团队 联合开发的开源多语言小模型语音合成系统。模型参数量仅 0.1B,专为实时语音生成场景设计,无需 GPU 即可在 CPU 上直接运行,适合本地演示、W...
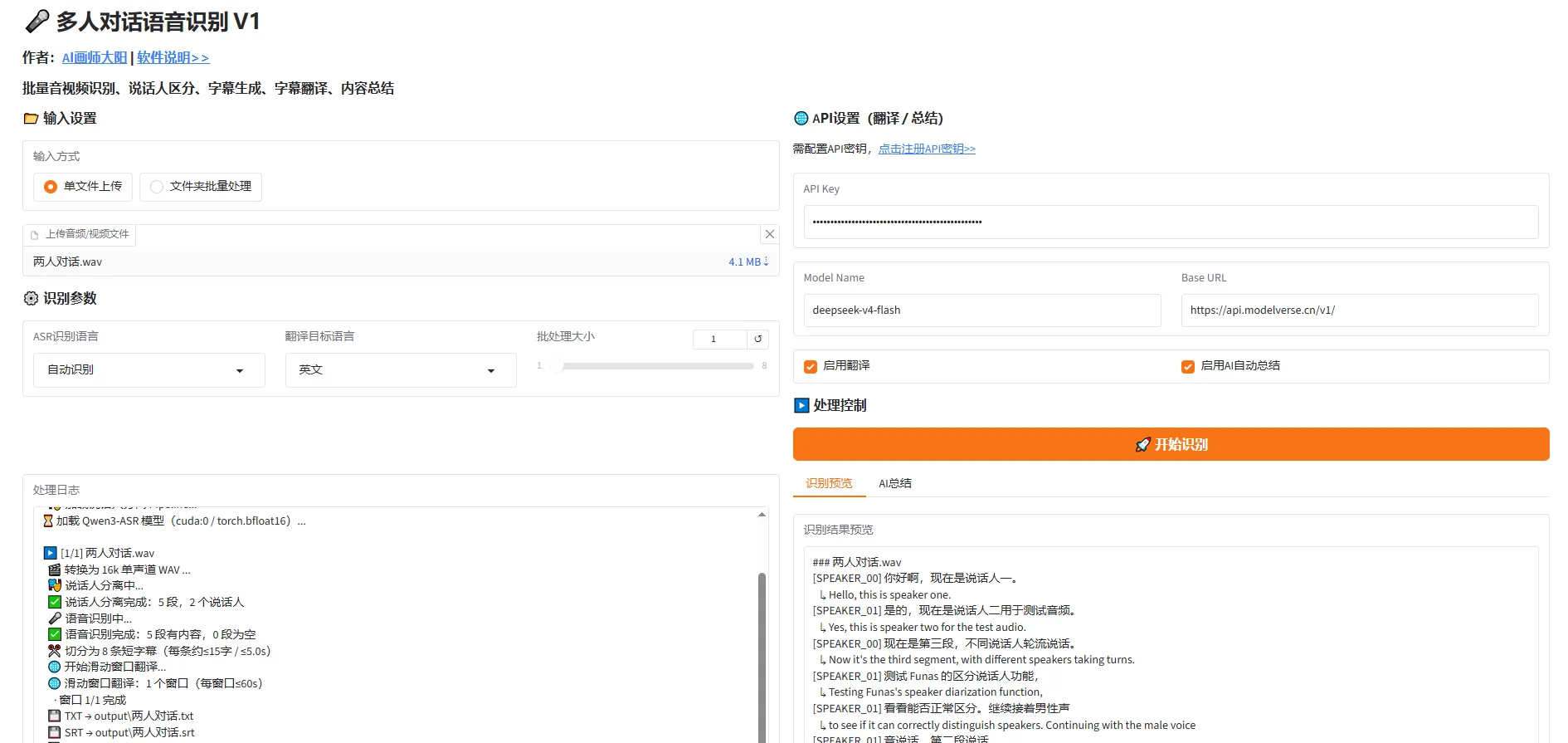
最强分说话人语音识别工具,支持批量音视频识别转字幕,字幕翻译内容总结
本软件是一款基于 Qwen3-ASR-1.7B 大模型的本地音视频语音识别工具,配备说话人分离功能,可在个人电脑上实现: 整个流程通过简洁的 Gradio Web 界面 操作,点击按钮即可完成识别与导出。 主要功能特点 1. 单文件识别与批...
最强PR中文视频自动语音识别生成字幕插件,语音识别准确率高支持多国语言
上次和大家分享了PR非常好用的自动剪辑口播视频静音片段插件,如果想要自动生成视频字幕的话,用PR自带的语音识别转字幕工具,效果非常差,语音识别准确率非常低,识别的文本差太多手动修改起来极其麻烦,反而更加浪费时间了。为了提高工作效率,降低人工...
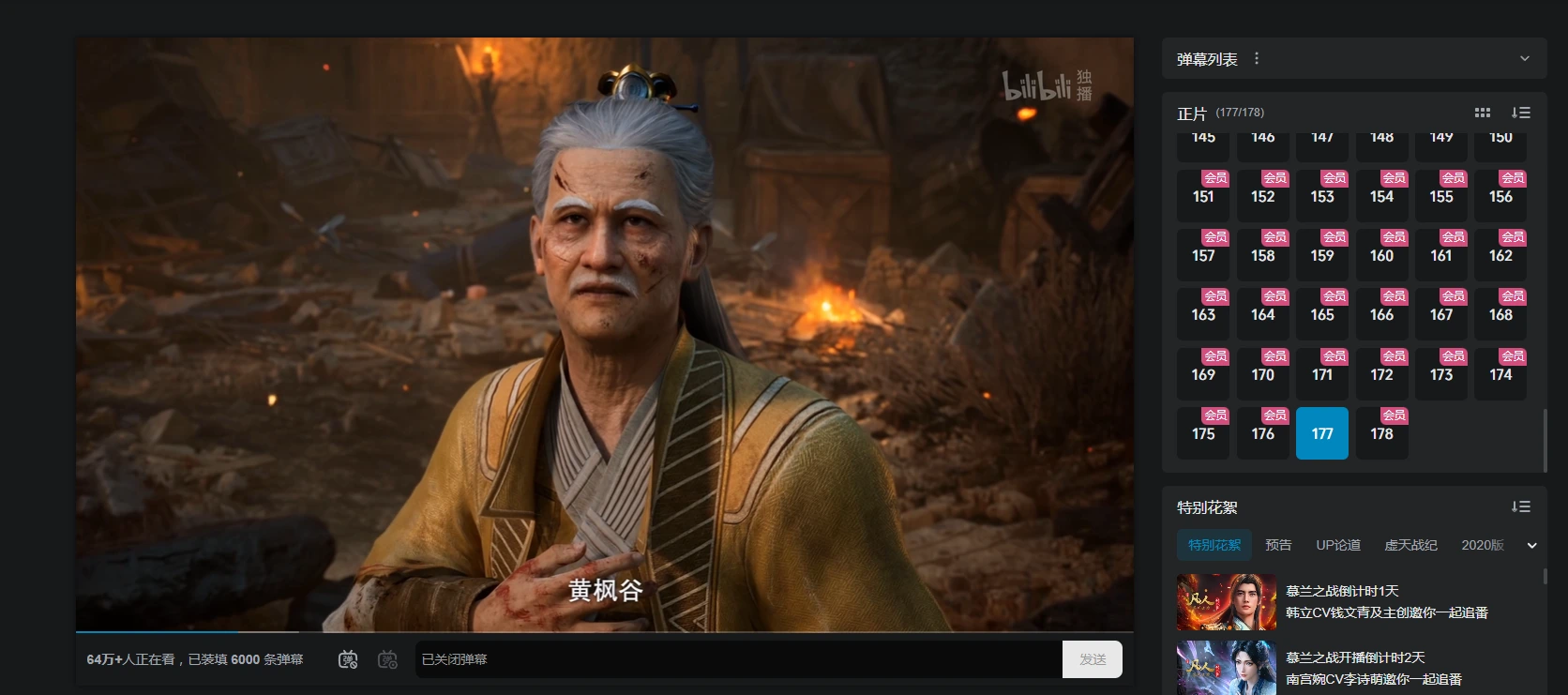
祝贺凡人修仙传2026年新年番开播同时在线人数超64万
今天6月13日凡人修仙传新年番开播,同时在线人数破64万(非最高在线人数,只是我看到的在线人数),作为凡人5年老粉,必须发个帖祝贺一下。 我比较喜欢看动漫,各种类型看了很多,具体不清楚多少,像斗罗斗破之类看了一大半终究是没能看下去,还是雾山...
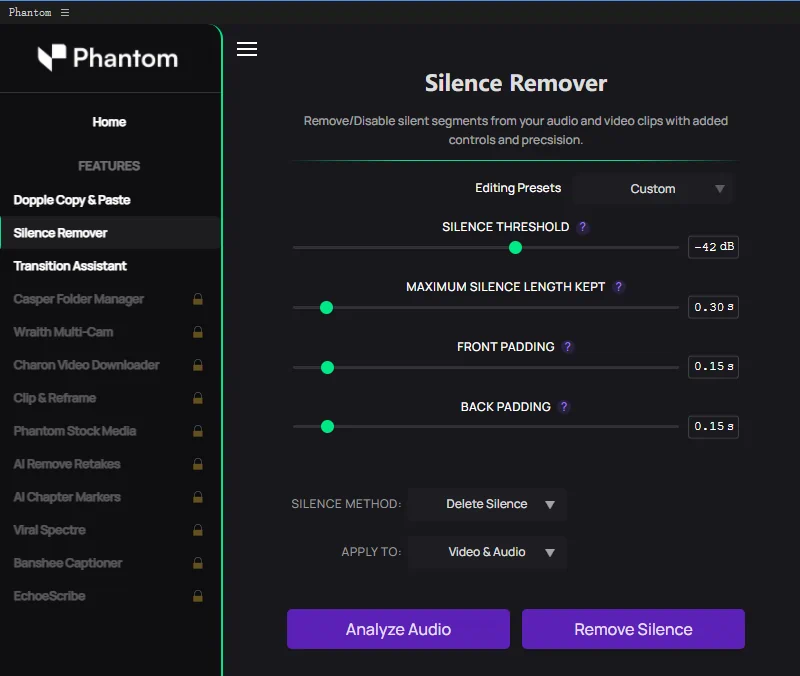
Premiere Pro静音片段自动剪辑插件——Silence Remover使用教程及下载
对于做口播、Vlog、播客剪辑的朋友来说,最耗时的工作之一就是手动找出视频中的”哑巴”片段——说话间隙、停顿、思考时的”嗯啊”——并逐一删除。今天给大家介绍一款来自 Phantom Edito...
蛙蛙写作-能替你"打工"的AI写作平台,附邀请码:UZekHC
我不是一个容易被工具说服的人。用过 ChatGPT、试过各种”AI写作神器”,大多数要么写出来全是机翻腔,要么根本不懂网文的爆款逻辑。 直到我开始用蛙蛙写作,才发现原来一个工具真的可以懂你想写什么。 🐸 蛙蛙写作是什...
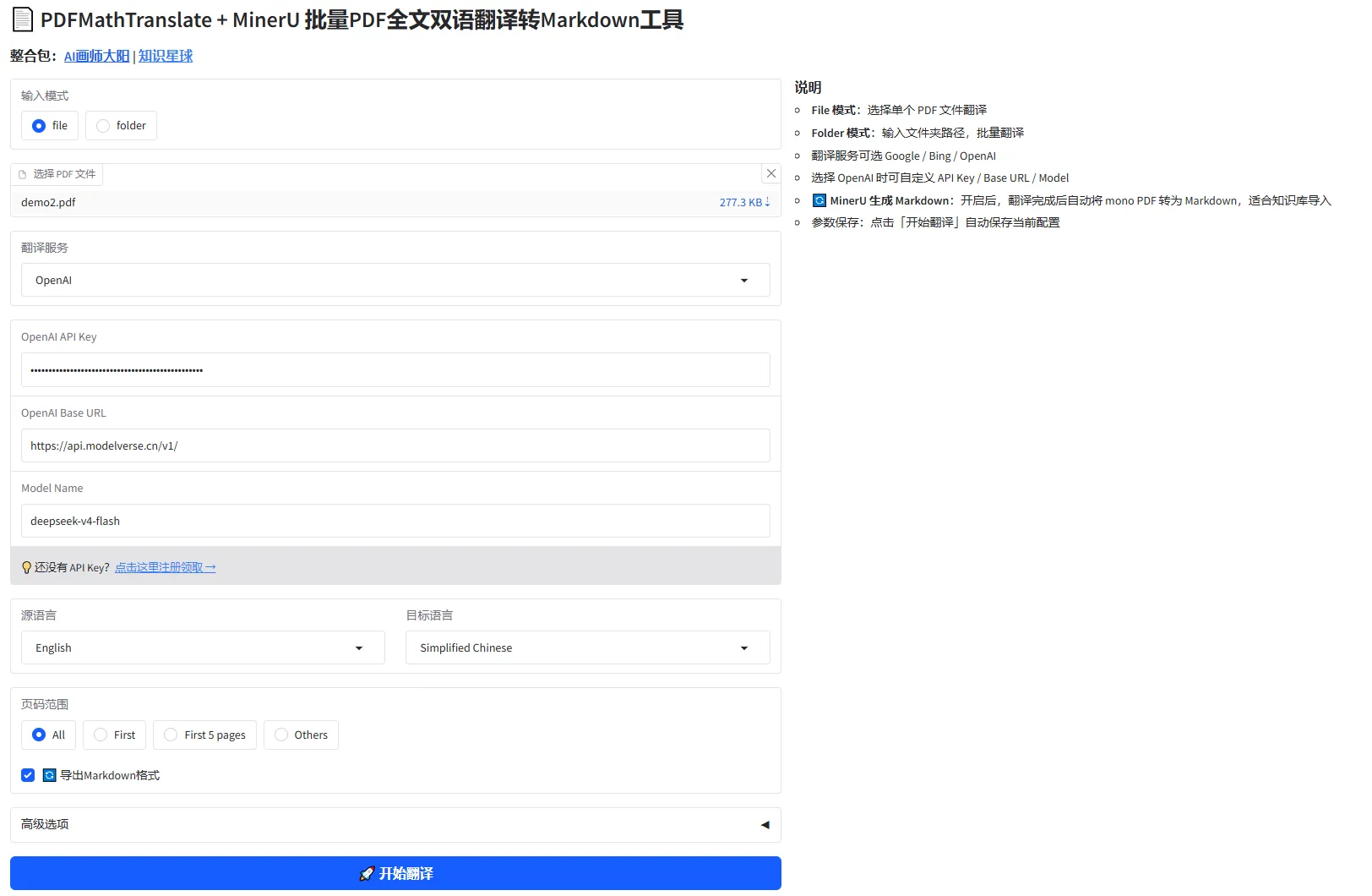
PDFMathTranslate + MinerU 批量PDF全文双语翻译转Markdown工具
本工具是一款基于 PDFMathTranslate 与 MinerU 整合的桌面端 PDF 翻译工具,通过简洁的 Web 界面实现一键式 PDF 全文双语翻译,并可选择将翻译结果导出为 Markdown 格式,方便导入知识库或进行二次编辑。...

Claude居然自称“本人”
今天在和Claude聊网文写作的时候,Claude回复中居然自称本人,这让我有点震惊。 我经常会和AI聊工具功能对比等话题,ChatGPT、Gemini、Claude这些以前我记得从来没有自称过本人的,好像都是本模型,本工具等等,反正从来没...